1. Desensitization and de-identification
Recently, the standards for desensitizing a large amount of data have been analyzed, including the GB/T 37964 issued by the National Information Security Standardization Technical Committee (abbreviated as ANTC, TC260) in 2019, which provides detailed explanations and guidance on the de-identification process for personal information and the methods of data de-identification, applicable to:
- Organize the work of personal information anonymization work,
- Organizations responsible for cyber security, third-party evaluation agencies, and other organizations carry out supervision and management, evaluation, and other work on personal information security.
But from the current commercial market of security, the basic idea of this guide has not been widely referenced,If the most core term 'anonymization' is mentioned, in the current data security products, we usually call it 'data desensitization', and the state also targetsData desensitization productsProject research on product quality, including the majority of industries currently released (such as telecommunications network and the Internet, electricity, transportation and communication) / local standards (such as Guangdong Province's health medical care, public data of various provinces) etc., the titles of which are none other than 'XXX Data Desensitization XXX', not 'XXX Anonymization XXX'. This means that in the industry, we see this word almost never alone, except in compliance documents or in the introduction of the term 'data desensitization',That is, the concept of 'annotation' has not been widely applied in the commercial market of data security, and we are more often engaged in the differentiation-free privacy removal of all sensitive fields, rather than focusing on the privacy removal of 'annotation' data.

How can we understand the anonymization mentioned in T37964-2019 'Guidelines for Personal Information Anonymization in Information Security Technology'?
According to the 'Personal Information Protection Law of the People's Republic of China' passed in 2021, the word 'desensitization' is not mentioned in the entire text, but 'anonymization' is mentioned twice. One is in Chapter V 'Obligations of Personal Information Processors' of the 'Appendix', which mentions: 'take appropriate technical measures such as encryption and anonymization'; the other is in Article 73 of the 'Supplementary Provisions', which defines the meaning of the term: 'anonymization refers to'Personal informationProcessed to make it impossible to identify a specific natural person without additional information.
That is, from a broad sense,We can consider that anonymization is a specific term for data in the context of personal information desensitization, and its essence is still data desensitization.
But from a narrow sense,The concept of 'annotation' includes whether specific data canAnnotate toNatural persons, which means that in the desensitization process, desensitization methods should be developed around the goal of 'how to desensitize in order to ensure that it is impossible to identify a specific natural person', which requires higher standards for data desensitization.
Currently, the Safety Evaluation Committee has issued two documents on personal information anonymization, all named 'Anonymization', as one of the implementation standards of the Personal Information Protection Law, and also corresponds to the Personal Information Reporting Law:
- GB/T37964-2019 'Guidelines for Personal Information Anonymization in Information Security Technology' — tells us how to desensitize personal information, the process and mechanism of desensitization, and the algorithms that can be referred to for desensitization
- GB/T 42460-2023 'Guidelines for the Assessment of Effectiveness of Personal Information Anonymization in Information Security Technology' — tells us how to evaluate the effectiveness of personal information desensitization
This article mainly summarizes GB/T37964-2019 'Information Security Technology - Guidelines for Personal Information De-identification', to perceive the concept of 'identification' in the desensitization process, as well as the objectives and principles to be followed. Although some descriptions need to be iteratively updated with the emergence of cloud and large models, I believeThe overall idea of this guide is very worth learning and referencingwhich is also the origin of writing this article.
Note: For convenience, we equate the concept of de-identification with data desensitization during the interpretation.
2. The related concepts and demands extended from the identified subject
In GB/T37964-2019, the core subject that needs to be desensitized is clearly defined, namelyPersonal information subject——person. Taking a database as an example, where personal information of students in Class A has been stored, we find the data rows describing this student, such as 'Zhang San, 15 years old, 330201189201239230, living at No. 35 Damao Lane, Binjiang District, Hangzhou City' this record, defined asMicro-data.
Among them, 'Zhang San' and other corresponding fields, such as name, can be calledAttribute. At the same time, in order to demonstrate the necessity of data in the de-identification process, we found in this record that the ID number 330201189201239230 can uniquely identify the information subject as Zhang San, a student. Therefore, 'ID number' is defined asDirect identifierWhile data such as 'Zhang San, 15 years old, living at No. 35 Damao Lane, Binjiang District, Hangzhou City' corresponds to attributes, although each attribute cannot identify who it is individually, it can identify Zhang San through combination. Therefore, 'name', 'age', and 'address' are defined asQuasi-identifier.
The data objects of de-identification, simply understood,This is the process of de-privacy for direct and indirect identifiers.
In fact, de-identification is not as simple as imagined. We need to fully assess the security of the data after de-identification under the premise of ensuring data usability, that is, whether it will be exploited or still exist risks associated with individuals, which is calledRe-identification(i.e., re-identification), it requires a comprehensive consideration of various factors. The following will be mentioned in the process of de-privacy.
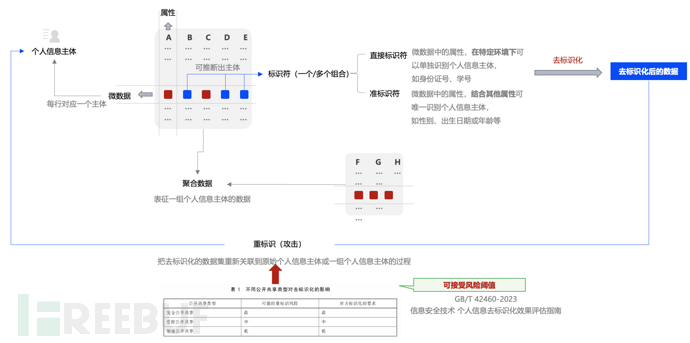
Figure 1 Understand the concept of nouns from the overall architecture
3. The objectives of de-identification
1. Delete or transform direct/indirect identifiers
2. Control the risk of re-identification and keep it within an acceptable range.
3. Select appropriate de-identification models and technologies based on business objectives and data characteristics to ensure that the desensitized data meets the expected objectives of usability.
4. The process of de-identification
Based on the above desensitization objectives, the text divides data desensitization into 5 processes.
4.3. List API: Display all objects (object) that a user can access
AI Large Model Security: Prompt Injection Attack (Prompt Injection Attack)
1.1 Create user objects from the Active Directory Users and Computers console
ArchKeeper (Introduction): Issues and concepts of the architecture protection platform

评论已关闭