CQRS is just a very simple pattern (pattern), CQRS itself is not a style of architecture, and it has no necessary connection with eventual consistency / messaging / read-write separation / event sourcing / DDD, etc. Its greatest advantage is that it brings us more architectural attribute options.
1 The essence of CQRS
1.1 CQS: Command and Query Segregation
Command and Query Segregation, the core idea of which is that any method of an object can be divided into two categories
・Query: Retrieve data, return the queried data without changing the data state
• Command: Change data status, return no data
Based on the CQS thought, any method can be divided into two parts: Command and Query:
private int origin = 0;
private int add(int value)
{
origin += value;
return origin;
}
The above method changes the data and returns the data status. According to the CQS thought, this method can be divided into Command and Query parts, as follows:
private void add(int value)
{
origin += value;
}
private int queryValue()
{
return origin;
}
There is controversy over whether to strictly adhere to the above conventions, and whether the command side returns data does not necessarily fully unify in actual business requirements. For example:
•" Pop" operation changes the stack state and returns data
• In some business scenarios, there may be a demand for returning business primary keys, such as returning the order number in the order operation
1.2 CQRS: Command and Query Responsibility Separation
Command and Query ResponsibilitySegregation, i.e., Command Query Responsibility Separation, proposed by Greg Young. CQRS is based on CQS,Extending the level of segregation from the code method level to the object level. The application of the CQRS pattern is very simple, as shown in the figure below
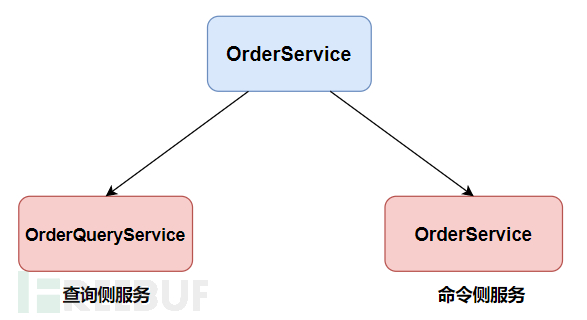
Assuming our service is OrderService, under the non-CQRS mode, it contains both query and update service interfaces:
public class OrderService {
// Query Order by ID
Order getOrder(OrderId)
// Query Paid Orders
List<Order> getPayedOrders()
// Place Order
void placeOrder(Order)
// Cancel Order
void cancelOrder(OrderId)
}
After applying the CQRS pattern, the OrderService is split into two interfaces, each taking on the responsibilities of querying and writing:
/**
Command Side Service
*/
public class OrderService {
void placeOrder(PlaceOrderCommand command)
void cancelOrder(CancelOrderCommand command)
}
/**
Query Service
*/
public class OrderQueryService{
Order GetOrder(OrderId)
List<Order> getPayedOrders()
}
The above simple separation is all there is to the CQRS pattern, isn't it very simple? Indeed, at first glance, CQRS is indeed this simple.
The greatest advantage of CQRS isBased on this responsibility separation, we can have more architectural property choices
・Independent deployment for both 'query' and 'command' sides to achieve better scalability
・Independent architectural design for both 'query' and 'command' sides
・Independent data model design for both 'query' and 'command' sides
Based on CQRS, we can derive more architectural properties, combine them with actual business scenarios, and carry out differentiated architectural design.
After the team introduces the CQRS pattern, it is often not just a simple separation of read and write responsibilities at the class responsibility level, but generally adopts a more complex application architecture style, as follows is a typical CQRS architectural style:
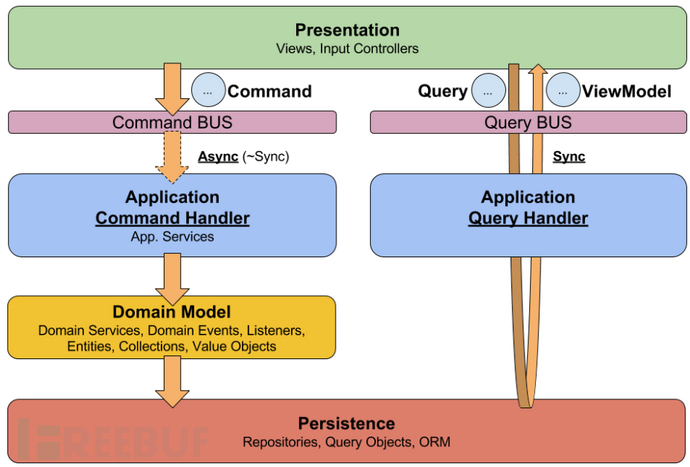
・Command side: Introduce a command bus to support flexible routing of different commands; highlight the application of domain models
・Query side: Introduce a query bus to route query requests; the request chain generally connects directly to the storage layer to meet different customized query needs
2 Myths about CQRS
2.1 Whether to separate the data model
CQRS emphasizes the separation of responsibilities between commands and queries, but at the level of the underlying data model, CQRS does not impose any mandatory restrictions, that is,Adopting the CQRS pattern does not require the separation of data models.
・Separated models: The query side and the write side models do not interfere with each other, and their implementation complexity in the application layer is relatively low. However, due to the separation of the models, the data consistency between the command side and the query side needs to be taken into consideration.
・Not separated: There is no need to consider data consistency issues, but since the requirements of the query side and the write side for the model may be different, the design of the model often needs to be compromised.
2.2 CQRS and Message Patterns
There is no necessary connection between CQRS and message patterns; it is not necessary to use message patterns to implement CQRS.
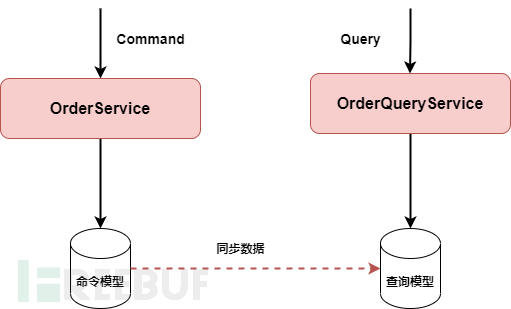
If we adopt the CQRS pattern, but the underlying data models on both sides of commands and queries are not separated, but based on shared data storage and data models, there is no need for additional interaction between commands and queries, and the data updates on the command side are visible in real-time to the query side. In this architectural mode, both sides are naturally integrated based on shared data, without the need for additional mechanisms for communication, and it is also unnecessary to introduce messages. If we adopt the CQRS pattern and separate the data models on both sides of commands and queries, both depend on independent data models. At the same time, the data storage is also deployed separately. The command side is responsible for data updates, while the query side is only responsible for data queries, and how to synchronize data updates in a timely manner to the query side is a problem that needs to be solved. In this architectural mode, using the message pattern as the communication mechanism between the two sides is a good choice, of course, this is not the only option.
2.3 CQRS and ES (Event Sourcing, 事件溯源)
ES is not a new concept; it has been applied in the earliest financial systems. To understand ES, we need to first look at traditional data storage. In traditional applications, databases such as MySQL (assuming the storage medium is a database) always store the latest state of the data. For example, if we have made multiple modifications or edits to a user's information and then saved the data to the database, the database will always record the final, latest user status. As long as we query the corresponding record in the database based on id or other information, we can obtain the latest information of the user. This is a typical data storage characteristic in applications.
Of course, we can design specific data models to save the change records of the data.
The characteristic of this data storage mode is simplicity; it does not require additional complex design maintenance. We can easily obtain the latest user information. Unfortunately, we lose historical information, including user intent information. This information is helpful for data rollback, user behavior analysis, and debugging during the development process, among others.

Under the ES model, the database no longer stores the latest state of the data, but the change records of the data, which is more officially referred to as 'events (Event)'. The data change event stream stored in the database. We can reconstruct the latest state based on the event stream, and we can also conveniently reproduce any historical node data. ES needs to solve the problem of storing a large number of events and efficiently reconstructing instances, which will be introduced in a separate article later.
2.4 CQRS and Eventual Consistency (最终一致性)
Final consistency is often introduced between services as well, and the purpose of final consistency is to improve scalability and availability.
CQRS and eventual consistency do not necessarily have a direct relationship.After adopting CQRS, the query and command sides often adopt independent data models. In this architectural mode, after the data changes on the command side are synchronized to the query side in a timely manner, the data on both sides is not real-time. After a certain delay, the data on both sides eventually reach consistency.
3 Conclusion
The greatest advantage of CQRS lies inBy separating the responsibilities of commands and queries, it provides architects with more architectural attribute options.We can independently design the architecture on the query side and the command side. Object-level responsibility separation is the essence of CQRS, but in practice, many more flexible and complex architectural styles have emerged, such as the introduction of buses, separation of data models, consistency strategy, event sourcing, and so on. The introduction of additional components or technologies inevitably leads to increased complexity and cost, and the adoption of these options requires the team to weigh the pros and cons.

评论已关闭