Author: JD Technology Miao Yuan
Background
With the rapid development of businesses and the increasing complexity of business, traditional monolithic applications have gradually exposed some problems, such as low development efficiency, poor maintainability, poor architecture scalability, inflexible deployment, and poor robustness, etc. Microservices architecture is to break down a single service into a series of small services, and these small services all have independent processes, independent of each other, and well solve the above problems of traditional monolithic applications. However, how to ensure the consistency of transactions in microservices architecture?
1. Introduction to Transactions
1.1 Transactions
1.1.1 The Origin of Transactions
Data in databases is a shared resource, therefore database systems usually need to support access by multiple users or different applications, and each access process is executed independently, which may lead to the phenomenon of concurrent access to data. This is somewhat similar to the multi-threading security issues in Java development (solving the problem of safe access to shared variables). If no measures are taken, data anomalies may occur. Here is a simple classic case: for example, if a user uses the money in their bank card to pay off their JD White Card, the bank card deduction is successful, but the White Card does not repay successfully due to network or system problems, which will cause major problems. In this case, we need to use transactions.
1.1.2 The Concept of Transactions
Transactions are the smallest working unit of database operations, which is a series of operations executed as a single logical working unit; these operations are submitted to the system as a whole, either all are executed or none are executed; a transaction is a set of operations that cannot be further divided (working logical units). For example: In a relational database, a transaction can be a single SQL statement, a group of SQL statements, or the entire program.
1.1.3 Characteristics of Transactions
The four main characteristics of transactions are: Atomicity, Consistency, Isolation, and Durability. These four characteristics are somewhat familiar to everyone, and here I will make a brief introduction.
(1) Atomicity: The operations within a transaction must either all succeed or all fail, and will not end at any intermediate stage. If all operations are successful, then the transaction is successful, and if any operation fails, the transaction will be rolled back to the initial state of the operation.
begin transaction;
update activity_acount set money = money-100 where name = ' 小明 ';
update activity_acount set money = money+100 where name = ' 小红 ';
commit transaction;
(2) Consistency: The execution of a transaction changes the data from one state to another, but maintains the stability of the integrity of the entire data. In other words, the data takes effect as expected, and the state of the data is the expected state. For example, the database must be in a consistent state before and after the execution of a transaction. If the transaction fails, it needs to be automatically rolled back to the original state, that is, once a transaction is committed, the results seen by other transactions are consistent, and once a transaction is rolled back, other transactions can only see the state before the rollback.
To put it in a more通俗 example: Xiao Ming transfers 100 yuan to Xiao Hong, the data before and after the transfer is in the correct state, which is called consistency. If Xiao Hong does not receive 100 yuan or receives an amount less than 100 yuan, this is a data error, and consistency is not achieved.
(3) Isolation: In a concurrent environment, when different transactions modify the same data at the same time, an incomplete transaction will not affect another incomplete transaction.
For example, when multiple users access the database concurrently, such as operating the same table, the transactions opened for each user by the database cannot be interfered with by the operations of other transactions, and multiple concurrent transactions should be isolated from each other.
(4) Durability: Once a transaction is committed, the modified data will be permanently saved in the database, and the change is permanent, even if the database fails afterwards, it should not have any impact on it.
To put it simply, for example: A has 2000 yuan in the card, when A withdraws 500 from the card, under the condition that there is no interference from external factors, then A's card can only have 1500 left. There is no situation where after withdrawing 500 yuan, the card can have 1400, 1500, or 1600 at different times.
1.1.4 MySQL Isolation Level
If we do not consider the problems caused by transaction isolation, such as dirty reads, non-repeatable reads, and phantom reads.
MySQL isolation levels are divided into 4 types: Read Uncommitted (Uncommitted Reads), Read Committed (Committed Reads), Repeatable Red (Repeatable Reads), and Serializaable (Serializable)
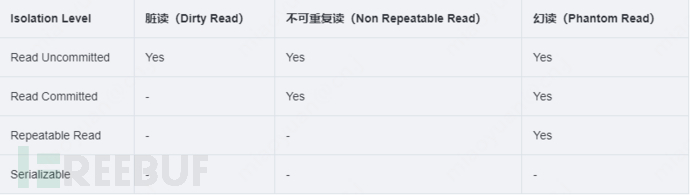
(1) Read Uncommitted is the lowest isolation level of transaction. Under this isolation level, a transaction may read the data updated by another transaction but not yet committed. If the other transaction rolls back, then the data read by the current transaction is dirty data, which is dirty read (Dirty Read).
(2) Under the Read Committed isolation level, a transaction may encounter the problem of non-repeatable read (Non Repeatable Read). Non-repeatable read refers to the situation where, within a transaction, multiple reads of the same data may be inconsistent if another transaction modifies this data before the first transaction ends.
(3) Under the Repeatable Read isolation level, a transaction may encounter the problem of phantom reads (Phantom Read). Phantom read refers to the situation where, in a transaction, the first query of a record finds that it does not exist, but when trying to update this non-existent record, it can be successful, and when reading the same record again, it magically appears, as if a hallucination occurred.
(4) Serializable is the strictest isolation level. Under the Serializable isolation level, all transactions are executed in sequence, so dirty reads, non-repeatable reads, and phantom reads will not occur. Although transactions under the Serializable isolation level have the highest security, due to the serial execution of transactions, the efficiency will decrease greatly, and the performance of the application will drop sharply. Generally, the Serializable isolation level is not used unless there is a particularly important scenario.
If no isolation level is specified, the database will use the default isolation level. In MySQL, if InnoDB is used, the default isolation level is Repeatable Read.
1.1.5 Start Transaction
Before explaining how to start a transaction, let's first think about the transaction propagation behavior. Transaction propagation behavior is used to solve the problem of two transaction-managed methods calling each other. In actual development, transactions are controlled in the service, such as the method calls with propagation behavior below. If serviceB also generates an agent object, it will also perform transaction management, executing serviceA and serviceB separately, and the content of the funA method in the above serviceA is no longer within a single transaction.
class serviceA{
//This method performs transaction control
funA(){
//Multiple dao operations are performed in this method, within a single transaction
userDao.insertUser();
orderDao.insertOrder();
//If another service method is called here, there is a transaction propagation
serviceB.funB();
}
}
class serviceB{
funB(){
}
}
The solution is to add the annotation @EnableTransactionManagement to the startup class and use @Transactional (isolation = Isolation.DEFAULT, propagation = Propagation.REQUIRED) on the transaction execution method to set the isolation level and transaction propagation. The default is REQUIRED.
Spring's declarative transaction defines several levels of transaction propagation, with the default propagation level being REQUIRED, which means that if there is no current transaction, a new transaction will be created, and if there is a current transaction, it will be joined to the current transaction for execution. The others include:
1.SUPPORTS:Indicates that if there is a transaction, it will be joined to the current transaction; if not, no transaction will be started. This propagation level can be used for query methods because SELECT statements can be executed within a transaction or without a transaction.
2.MANDATORY:Indicates that the current transaction must exist and be joined for execution; otherwise, an exception will be thrown. This propagation level can be used for core update logic, such as user balance changes, which are always called by other transaction methods and cannot be directly called by non-transaction methods.
3.REQUIRES_NEW:Indicates that a new transaction must be started regardless of whether there is a current transaction. If there is already a transaction, it will be suspended until the new transaction is completed, and then it will resume execution.
4.NOT_SUPPORTED:Indicates that transactions are not supported. If there is a current transaction, it will be suspended until this method is executed, and then it will resume execution.
5.NEVER:Compared to NOT_SUPPORTED, it not only does not support transactions but also throws an exception to refuse execution when it detects that there is a transaction currently;
6.NESTED:NESTED: It means that if there is a transaction currently, it will start a nested level transaction; if there is no transaction currently, it will start a new transaction.
1.2 Local transactions
1.2.1 Definition of local transactions
Definition: In a monolithic application, we use the same connection to execute multiple business operations, operate the same database, operate different tables, and can roll back the entire operation in case of an exception.
In fact, when introducing the definition of transactions, part of the local transactions were also introduced. Local transactions ensure strong data consistency through ACID, and we have used local transactions more or less in our actual development process. For example, MySQL transaction processing uses begin to start a transaction, rollback to roll back a transaction, and commit to confirm a transaction. After the transaction is submitted, changes are recorded through redo log, and rollback is performed through undo log in case of failure to ensure the atomicity of the transaction. When we develop in Java, we are all familiar with Spring. Spring can implement transaction functionality through the @Transactional annotation, which we have also introduced before. In fact, Spring encapsulates these details. When generating related Beans, it uses an agent to inject related Beans with @Transactional annotations, and starts commit/rollback transactions in the agent.
1.2.2 The disadvantages of local transactions
With the rapid development of business, facing massive data, such as data of tens of millions or even hundreds of millions, the time taken for a single query will increase, and even cause single-point pressure on the database. Therefore, we need to consider the sharding and partitioning scheme. The purpose of sharding and partitioning is to reduce the burden on a single database and table, improve query performance, and shorten query time. Here, let's first look at the scenario of single-database splitting. In fact, the table splitting strategy can be summarized as vertical splitting and horizontal splitting. Vertical splitting involves splitting the fields of a table, that is, splitting a table with many fields into multiple tables, which makes the row data smaller. On the one hand, it can reduce the number of bytes of network transmission between the client program and the database, because the production environment shares the same network bandwidth. With the increase in concurrent queries, it may cause a bandwidth bottleneck, resulting in blockage. On the other hand, a data block can store more data, which will reduce the number of I/O operations during queries. Horizontal splitting involves splitting the rows of a table. Because when the number of rows in a table exceeds several million, it will slow down, and at this time, the data of a single table can be split into multiple tables for storage. Horizontal splitting has many strategies, such as modulus table splitting, time dimension table splitting, etc. In this scenario, although we have split tables according to specific rules, we can still use local transactions.
However, internal table sharding only solves the problem of oversized single-table data, but does not disperse the data of a single table across different physical machines. Therefore, it cannot alleviate the pressure on the MySQL server, and there is still resource competition and bottlenecks on the same physical machine, including CPU, memory, disk IO, and network bandwidth. For the sharding scenario, it divides the data of a table into different databases, with tables in multiple databases having the same structure. At this point, if we route the data we need to use transactions to the same database according to certain rules, we can ensure strong consistency through local transactions. However, for vertical sharding according to business and function, it distributes business data to different databases. Here, the system after sharding will encounter data consistency issues because the data that needs to be guaranteed by transactions is dispersed across different databases, and each database can only ensure that its own data meets the ACID guarantees for strong consistency. However, in a distributed system, they may be deployed on different servers and can only communicate through the network, so it is impossible to accurately know the execution status of transactions in other databases.
In addition, not only do local transactions fail to solve the problems in cross-database calls, but as microservices are implemented, each service has its own database, which is independent and transparent. If service A needs to access data from service B, there will be cross-service calls. In scenarios such as service failure, network connection anomalies, or synchronous call timeouts, this can lead to data inconsistency, which is also a distributed scenario that needs to consider the issue of data consistency.
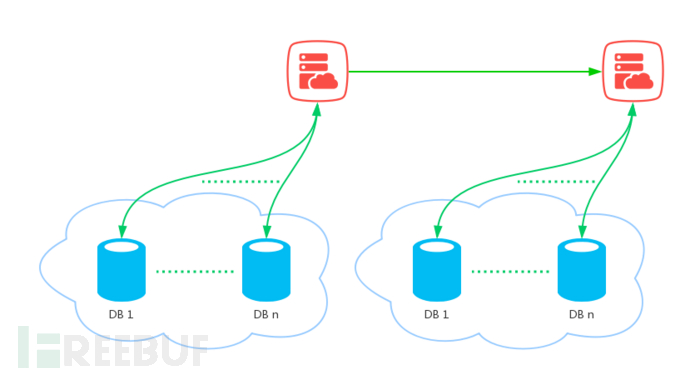
After the expansion of business volume, the sharding of databases, and the service-oriented business after the落地 of microservices, distributed data inconsistency issues will arise. Since local transactions cannot meet the requirements, distributed transactions are therefore needed.
2. Definition of Distributed Transactions
Definition of Distributed Transactions: We can simply understand it as a transaction solution to ensure the consistency of data in different databases. Here, it is necessary to understand the CAP theorem and BASE theory first. The CAP theorem is an abbreviation for Consistency (Consistency), Availablity (Availability), and Partition-tolerance (Partition Tolerance). It is a balancing theory in distributed systems. In distributed systems, consistency requires that all nodes ensure that each read operation can obtain the latest data; availability requires that the service remains available after any failure; partition tolerance requires that partitioned nodes can provide normal external services. In fact, any system can only satisfy two of them at a time, and it is impossible to satisfy all three. For distributed systems, partition tolerance is a basic requirement. If consistency and partition tolerance are chosen and availability is given up, network problems can cause the system to be unavailable. If availability and partition tolerance are chosen and consistency is given up, the data between different nodes cannot be synchronized in time, leading to data inconsistency.
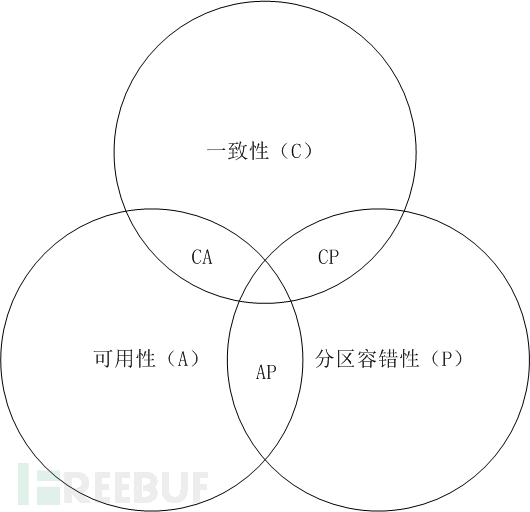
At this point, the BASE theory proposes a solution for consistency and availability, where BASE is an abbreviation for Basically Available (Basic Availability), Soft-state (Soft State), and Eventually Consistent (Eventual Consistency). It is the theoretical support for eventual consistency. Simply put, in a distributed system, it allows for the loss of some availability, and the process of data synchronization between different nodes has a delay. However, after a period of repair, it can eventually achieve the final consistency of data. BASE emphasizes the final consistency of data. Compared to ACID, BASE achieves availability by allowing the loss of some consistency.
Now the most commonly used distributed transaction solutions include strong consistency two-phase commit protocol, three-phase commit protocol, as well as eventually consistent reliable event pattern, compensation pattern, and TCC pattern.
3. Distributed Transactions - Strong Consistency Solution
3.1 Two-Phase Commit Protocol
In a distributed system, each database can only ensure that its own data meets the ACID guarantee of strong consistency, but they may be deployed on different servers and can only communicate through the network, so it is impossible to accurately know the execution status of transactions in other databases. Therefore, in order to solve the coordination problem between multiple nodes, it is necessary to introduce a coordinator to control the operation results of all nodes, either all succeed or all fail. Among them, the XA protocol is a distributed transaction protocol with two roles: transaction manager and resource manager. Here, we can understand the transaction manager as the coordinator and the resource manager as the participant.
The XA protocol ensures strong consistency through the two-phase commit protocol.
As the name suggests, the two-phase commit protocol has two phases: the first phase is preparation, and the second phase is commit. Here, the transaction manager (coordinator) is mainly responsible for controlling the operation results of all nodes, including the preparation process and the commit process. In the first phase, the transaction manager (coordinator) sends a preparation instruction to the resource manager (participant) to inquire whether the pre-commitment is successful. If the resource manager (participant) can complete it, it will perform the operation without committing and finally provide its response result, indicating whether the pre-commitment is successful or failed. In the second phase, if all resource managers (participants) reply that the pre-commitment is successful, the resource manager (participant) formally submits the command. If any resource manager (participant) replies that the pre-commitment is failed, the transaction manager (coordinator) will initiate a rollback command to all resource managers (participants). To illustrate, let's take the case of a transaction manager (coordinator) and three resource managers (participants). In this transaction, we need to ensure the strong consistency of the data of these three participants throughout the transaction process. First, the transaction manager (coordinator) initiates a preparation instruction to predict whether they have successfully pre-committed. If all reply that the pre-commitment is successful, then the transaction manager (coordinator) formally initiates the commit command to execute the data change.
It should be noted that, although a solution is proposed by the two-phase commit protocol to ensure strong consistency, there are still some issues. First, the transaction manager (coordinator) is mainly responsible for controlling the operation results of all nodes, including the preparation process and the commit process, but the entire process is synchronous, so the transaction manager (coordinator) must wait for each resource manager (participant) to return the operation result before proceeding to the next step. This is very likely to cause a synchronization blocking problem. Second, a single point of failure is also an issue that needs to be considered carefully. Both the transaction manager (coordinator) and the resource manager (participant) may experience downtime. If the resource manager (participant) fails, it will not respond and keep waiting, and if the transaction manager (coordinator) fails, the transaction process will lose its controller, in other words, the entire process will remain blocked, and in extreme cases, some resource managers (participants) may execute the commit while others do not, leading to data inconsistency. At this point, readers may raise questions: aren't these issues rare cases that generally do not occur? Yes, but for the distributed transaction scenario, we not only need to consider the normal logical process but also pay attention to the rare exception scenarios. If we lack a handling plan for exception scenarios, data inconsistency may occur, and then it will be a very costly task to rely on manual intervention for later processing. In addition, for the core chain of the transaction, it may not be a data issue but a more serious issue of capital loss.
3.2 Three-Phase Commit Protocol
There are many problems with the two-phase commit protocol, so the three-phase commit protocol has to take the stage. The three-phase commit protocol is an improved version of the two-phase commit protocol, and it is different from the two-phase commit protocol in that it introduces a timeout mechanism to solve the synchronization blocking problem. In addition, it introduces a preparatory phase to discover as early as possible the resource managers (participants) that cannot be executed and terminate the transaction. If all resource managers (participants) can complete, the preparation of the second phase and the submission of the third phase will be initiated. Otherwise, if any resource manager (participant) responds with execution failure or timeout waiting, the transaction will be terminated. In summary, the three-phase commit protocol includes: the first phase preparation, the second phase preparation, and the second phase submission.
Here, some of you may be a bit confused, so I will explain the overall process of the three-phase commit in detail.
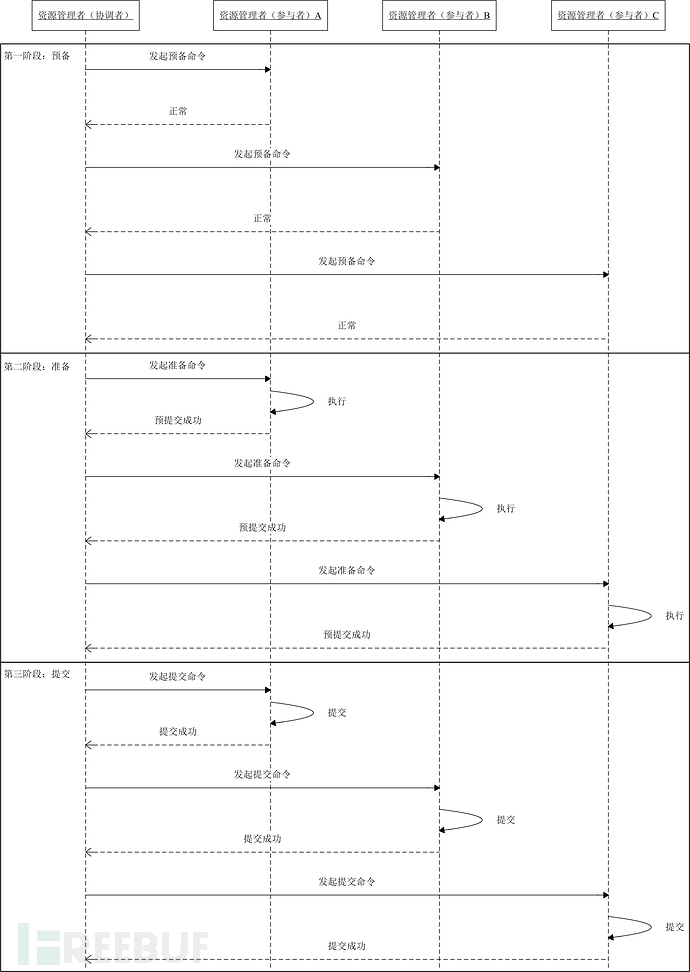
3PC is mainly to solve the single point of failure problem of the two-phase commit protocol and narrow the blocking range of participants. In addition to introducing the timeout mechanism of participant nodes, 3PC divides the preparation stage of 2PC into transaction inquiry (this stage will not block) and transaction pre-commitment, so the three stages are CanCommit, PreCommit, and DoCommit.
(1) The First Phase (CanCommit Phase)
Similar to the preparation (first) stage of 2PC. The coordinator sends a commit request to the participant, and if the participant can commit, it returns a Yes response; otherwise, it returns a No response.
1. Transaction Inquiry:
The coordinator sends a CanCommit request to the participant, asking whether the transaction commit operation can be executed. Then it starts waiting for the participant's response.
2. Response Feedback
After the participant receives the CanCommit request, in normal circumstances,
If it believes that it can smoothly execute the transaction, it will return a Yes response and enter the prepared state.
Otherwise, feedback No.(2) The second stage (PreCommit stage)
The coordinator decides whether to perform the PreCommit operation of the transaction based on the participant's response. According to the response, there are two possibilities:
If the response is Yes, then:
1. Send the pre-commit request:
The coordinator sends a PreCommit request to the participant and enters the Prepared stage.
2. Pre-commit the transaction
After the participant receives the PreCommit request, it will execute the transaction operation and record the undo and redo information into the transaction log.
3. Feedback the response
If the participant successfully executes the transaction operation, it will return an ACK response and start waiting for the final instruction.
If any participant sends a No response to the coordinator, or if the coordinator does not receive the participant's response after waiting for timeout, then the interruption of the transaction is executed. Then there is:
1. Send the interruption request:
The coordinator sends an abort request to all participants
2. Interrupt the transaction
After the participant receives the abort request from the coordinator (or after timeout, if it has not received the request from the coordinator), it executes the interruption of the transaction.
(3) The third stage (doCommit stage)
This stage performs the actual transaction commitment, which can also be divided into two cases: executing the commit and interrupting the transaction.
If the execution is successful, the following operations will be performed:
1. Send the commit request
When the coordinator receives the ACK response from the participant, it will move from the pre-commit state to the commit state.
and sends a doCommit request to all participants.
2. Commit the transaction
After the participant receives the doCommit request, it executes the formal transaction commitment.
and release all transaction resources after the transaction commitment is completed.
3. Feedback the response
After the transaction is committed, send an ACK response to the coordinator.
4. Complete the transaction
After the coordinator receives the ACK response from all participants, it completes the transaction.
If the coordinator does not receive the ACK response from the participant (it may be that the sender did not send an ACK response, or the response timed out), then it will execute the interruption of the transaction (Note that this is not receiving the ACK at the end of the second segment, here you need to understand clearly) Then there are the following operations:
1. Send the interruption request
The coordinator sends an abort request to all participants
2. Rollback the transaction
After the participant receives the abort request, it uses the undo information recorded in stage two to perform the rollback operation of the transaction,
and release all transaction resources after the rollback is completed.
3. Feedback the result
After the participant completes the rollback of the transaction, it sends an ACK message to the coordinator
4. Interrupt the transaction
after the coordinator receives the ACK message from the participant, the interruption of the transaction is executed.
the most critical:At the doCommit stage,If the participant fails to receive the doCommit or rebort request from the coordinator in time(1. Coordinator problems; 2. Network failure between coordinator and participant), after waiting for the timeout, the transaction submission will continue. (In fact, this should be based on probability. When entering the third phase, it means that the participant has received the PreCommit request in the second phase. The premise for the coordinator to generate the PreCommit request is that he receives all the CanCommit responses from participants are Yes before the start of the second phase. (Once the participant receives PreCommit, it means he knows that everyone actually agrees to modify it.) So, in a word, when entering the third phase, although the participant has not received the commit or abort response, he has reason to believe: the probability of successful submission is very high)
The three-phase commit protocol has well-solved the problems brought by the two-phase commit protocol and is a very valuable solution. However, there may be data inconsistency in a very small probability scenario. Because the three-phase commit protocol introduces a timeout mechanism. Once the participant fails to receive information from the coordinator in time, it will default to execute commit instead of holding the transaction resources and remaining in a blocked state. However, this mechanism may also lead to data consistency issues. Because, due to network reasons, the abort response sent by the coordinator is not received in time by the participant, then the participant will execute the commit operation after waiting for the timeout. This will result in data inconsistency with other participants who have received the abort command and executed rollback.
4. Distributed Transactions - Final Consistency Solution
4.1 TCC Mode
The two-phase commit protocol and the three-phase commit protocol have well-solved the problem of distributed transactions, but there is still data inconsistency in extreme cases. In addition, it has a large overhead on the system, and it is easy to appear a bottleneck of a single point after introducing a transaction manager (coordinator). In the case of continuously expanding business scale, the scalability of the system may also be a problem. It should be noted that it is a synchronous operation, so after the introduction of a transaction, the resources can only be released after the global transaction is completed, which may be a big problem in performance. Therefore, it is rarely used in high-concurrency scenarios. Therefore, another solution is needed: the TCC mode. It should be noted that many readers equate two-phase commit with the two-phase commit protocol, which is a misunderstanding. In fact, the TCC mode is also a two-phase commit.
The TCC mode splits a task into three operations: Try, Confirm, and Cancel. Suppose we have a func() method, then in the TCC mode, it becomes tryFunc(), confirmFunc(), and cancelFunc() three methods.
In the TCC mode, the main business service is responsible for initiating the process, and the dependent business services provide the three operations of TCC mode: Try, Confirm, and Cancel. There is also a role of a transaction manager responsible for controlling the consistency of the transaction. For example, we currently have three business services: trading service, inventory service, and payment service. The user selects products, places an order, and then chooses a payment method to make a payment. Then, this request, the trading service will first call the inventory service to deduct inventory, and then the trading service will call the payment service to perform related payment operations, and then the payment service will request the third-party payment platform to create a transaction and deduct the payment. Here, the trading service is the main business service, and the inventory service and payment service are dependent business services.
Let's sort out the process of TCC mode. In the first phase, the main business service calls the Try operation of all the dependent business services, and the transaction manager records the operation log. In the second phase, when all dependent business services are successful, the Confirm operation is executed, otherwise, the Cancel reverse operation is executed for rollback.
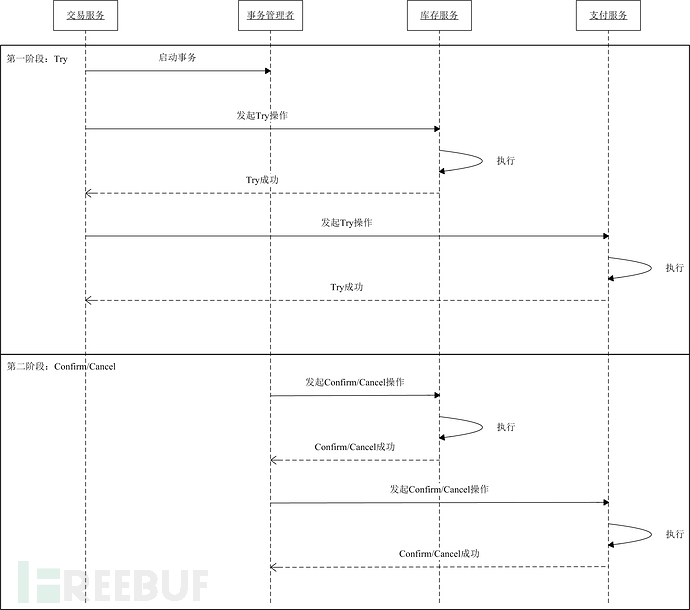
Note:We need to pay special attention to the idempotence of operations. The core of the idempotent mechanism is to ensure the uniqueness of resources, for example, repeated submission or multiple retries on the server will only produce one result. In payment scenarios, refund scenarios, transactions involving money cannot have problems such as multiple deductions. In fact, query interfaces are used to obtain resources because they only query data without affecting the change of resources, so no matter how many times the interface is called, the resources will not change, so it is idempotent. On the other hand, the new interface is not idempotent because multiple calls to the interface will always produce changes in resources. Therefore, we need to perform idempotent processing when repeated submission occurs.
How can we ensure the idempotent mechanism? In fact, we have many implementation solutions. One common solution is to create a unique index. Creating a unique index on the resource field that needs to be constrained in the database can prevent the insertion of duplicate data. However, when it comes to sharding and partitioning, the unique index is not very effective. In this case, we can first query the database once, then judge whether the constrained resource field exists duplicate, and then perform the insertion operation if there is no duplicate. It is noted that to avoid concurrent scenarios, we can use locking mechanisms such as pessimistic locking and optimistic locking to ensure the uniqueness of the data. Here, distributed lock is a frequently used solution, which is usually an implementation of pessimistic locking. However, many people often confuse pessimistic locking, optimistic locking, and distributed locking with solutions for idempotent mechanisms, which is incorrect. In addition, we can also introduce a state machine to constrain and transition states through the state machine, ensuring the process-oriented execution of the same business process, thus realizing data idempotence.
4.2 Compensation Mode
We mentioned the retry mechanism. In fact, it is also a solution for eventual consistency: we need to make every effort to retry continuously to ensure that the database operations ultimately guarantee data consistency. If the retry fails multiple times, we can notify the developers to manually intervene based on related logs. It should be noted that the called party needs to ensure its idempotence. The retry mechanism can be a synchronous mechanism, such as timely re-launching business calls in case of timeout or abnormal call failures in the main business service. The retry mechanism can be roughly divided into fixed number of retries strategy and fixed time of retries strategy. In addition, we can also make use of message queue and timing task mechanisms. The retry mechanism of the message queue is to redeliver the message if the message consumption fails, thus avoiding the situation where the message is not consumed and discarded. For example, JMQ can allow each message to retry a maximum of how many times by default, and the interval time for each retry can be set. The retry mechanism of the timing task, we can create a task execution table and add a 'retry times' field. In this design, we can check whether the task is in a failed execution status and has not exceeded the retry times during the timing call. If it is, then perform a failed retry. However, when the execution fails and exceeds the retry times, it indicates that the task has permanently failed and requires manual intervention and problem investigation by the developers.
In addition to the retry mechanism, repairs can also be made during each update. For example, for scenarios such as social interaction likes,收藏数, comments, etc., data may be inconsistent for a period of time due to network fluctuations or unavailability of related services. In this case, we can make repairs during each update to ensure that the system reaches consistency after a short period of self-recovery and correction. It should be noted that under this solution, if a piece of data becomes inconsistent but is not updated and repaired again, it will always be abnormal data.
Timely correction is also a very important solution, which ensures the operation by taking periodic verification. When it comes to the selection of the timing task framework, commonly used in the industry include Quartz for single-machine scenarios, and distributed timing task middleware such as Elastic-Job, XXL-JOB, SchedulerX, etc. for distributed scenarios. Our company has a distributed call platform ( https://schedule.jd.com/Regarding scheduled reconciliation, there are two scenarios: one is the incomplete scheduled retry, such as using scheduled tasks to scan the call tasks that have not been completed, and use compensation mechanisms to repair them to achieve data consistency in the end. Another is scheduled reconciliation, which requires the main business service to provide relevant query interfaces to the secondary business service for reconciliation and query, used to restore lost business data. Now, let's imagine the e-commerce scenario of refund business. In this refund business, there will be a refund basic service and an automated refund service. At this time, the automated refund service enhances the refund capability based on the refund basic service, realizes automated refund based on multiple rules, and receives the refund snapshot information pushed by the refund basic service through the message queue. However, due to the loss of messages sent by the refund basic service or the active discard of the message queue after multiple failed retries, it is very likely to cause data inconsistency. Therefore, it is particularly important to recover lost business data by querying and reconciling from the refund basic service on a scheduled basis.
4.3 Reliable Event Pattern
In a distributed system, the message queue plays a very important role in the architecture of the service-side, mainly solving problems such as asynchronous processing, system decoupling, and traffic smoothing. If multiple systems use synchronous communication, it is easy to cause blocking, and at the same time, these systems will be coupled together. Therefore, after introducing the message queue, on the one hand, it solves the blocking caused by synchronous communication mechanisms, and on the other hand, it achieves business decoupling through the message queue.
The reliable event pattern, by introducing a reliable message queue, ensures that as long as the current reliable event delivery is guaranteed and the message queue ensures the event delivery at least once, the consumer subscribing to this event can ensure that the event can be consumed within its business. Does it mean that the problem can be solved by simply introducing a message queue? In fact, introducing a message queue alone cannot guarantee its ultimate consistency, because in a distributed deployment environment, communication is based on the network, and during the process of network communication, messages may be lost due to various reasons.
Firstly, the main business service may fail to send messages due to the unavailability of the message queue. In this case, we can ensure that the main business service (producer) sends the message and then proceed with the business call. The general practice is to persist the message to be sent in the local database, set the flag status to
After understanding the methodology of
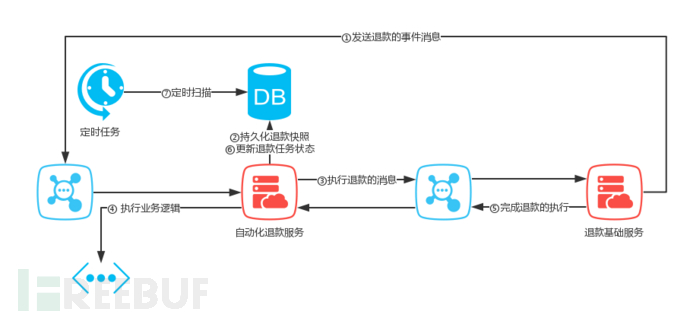
In summary, the introduction of a message queue does not guarantee reliable event delivery. In other words, message loss due to various reasons such as the network cannot guarantee its ultimate consistency. Therefore, we need to ensure reliable event delivery of the message queue through the 'positive and negative message mechanism' and use compensation mechanisms to resubmit messages that have not been completed within a certain period of time.
5, Summary
Mike Burrows, the author of Google Chubby, once said, 'There is only one consensus protocol, and that is Paxos' – all other approaches are just broken versions of Paxos. This means that there is only one consistency algorithm in the world, which is Paxos, and all other consistency algorithms are incomplete versions of the Paxos algorithm. The solutions mentioned above are all concrete solutions based on the Paxos algorithm theory. Systems such as Google's Chubby, MegaStore, and Spanner, the ZAB protocol of ZooKeeper, and the more easily understandable Raft protocol all have the shadow of the Paxos algorithm. Those who are interested can refer to the detailed explanation of the Paxos algorithm, and this will not be elaborated on here.
Currently working on project related to activity platforms, often required to complete an activity component in a short period of time. Generally, there is no complete consideration of ensuring transaction consistency under microservices or a unified standard, so it is necessary to have SOP for ensuring transaction consistency under microservices. This ensures that each activity can be quickly set up and safely operated. An overall solution for ensuring transaction consistency under microservices for the activity platform will be launched later. Everyone may have heard of it before or considered it to some extent during the coding process, and may have used some of the solutions mentioned earlier, but there is no systematic understanding or comprehensive solution research. It is hoped that this article can give everyone a more complete understanding. Any deficiencies in the article or better solutions from everyone are welcome to discuss together.

评论已关闭