1 Preface
A while ago, a colleague next to me asked me about hot data issues. After giving him a rough explanation of the case of redis data skew, I also reviewed some methodologies about hot data processing, and also remembered the JD open source project hotkey that I learned last year, which is specifically used to solve hot data problems. Here, combining the related knowledge points of both, I will introduce the relevant methodologies and the source code analysis of hotkey through several small diagrams and some rough explanations, so that everyone can understand the related methodologies and the source code analysis of hotkey.
2 Redis data skew
2.1 Definition and harm
Let's first talk about the definition of data skew, borrowing the explanation from Baidu Encyclopedia:
For cluster systems, caches are generally distributed, that is, different nodes are responsible for a certain range of cache data. We call it data skew when the cache data dispersion is not enough, causing a large amount of cache data to be concentrated on one or several service nodes. Generally, data skew is caused by the poor implementation of load balancing.
From the above definition, it can be known that the general cause of data skew is that the effect of load balancing is not good, leading to a very concentrated amount of data on some nodes.
Then, what kind of harm will it cause?
If data skew occurs, the instance that saves a large amount of data or saves hot data will increase the processing pressure, slow down the speed, and even may cause the memory resources of this instance to be exhausted, leading to a crash. This is something we need to avoid when applying slice clusters.
2.2 Classification of data skew
2.2.1 Data volume skew (write skew)
1. Illustration
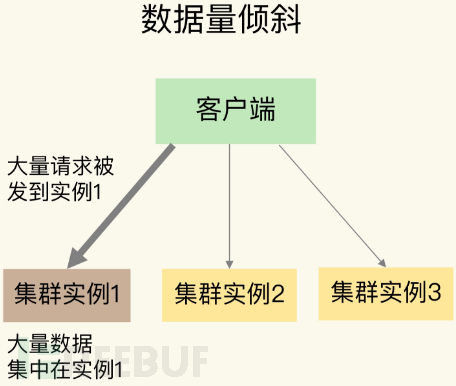
As shown in the figure, in some cases, the data distribution on the instance is unbalanced, and the data on a certain instance is particularly large.
2. bigkey causes skew
bigkey is exactly saved on a certain instance. The value of bigkey is very large (String type), or bigkey saves a large number of collection elements (collection type), which will cause the data volume of this instance to increase, and the corresponding memory resource consumption will also increase.
Countermeasures
When generating data at the business layer, it is necessary to avoid storing too much data in the same key-value pair as much as possible.
If the bigkey is exactly a set type, there is another method, which is to split the bigkey into many small set type data and store them scatteredly on different instances.
3. Uneven Slot Allocation Causes Skew
Let's briefly introduce the concept of slot. The full name of slot is Hash Slot (哈希槽), in the Redis Cluster slice cluster, there are a total of 16384 slots. These hash slots are similar to data partitions, and each key-value pair will be mapped to a hash slot according to its key. The Redis Cluster solution uses hash slots to handle the mapping relationship between data and instances.
A picture to explain the mapping distribution of data, hash slots, and instances.
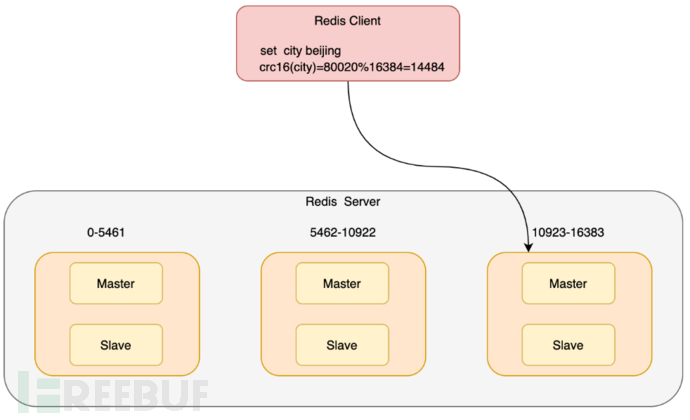
Here, CRC16(city)%16384 can be simply understood as taking the hash value of key1 according to the CRC16 algorithm and taking the modulus of the number of slots, which is the slot position of 14484, and the corresponding instance node is the third one.
When constructing a slice cluster, operations and maintenance personnel need to manually allocate hash slots and allocate all 16384 slots, otherwise the Redis cluster cannot work normally. Since it is manual allocation, it may lead to some instances being allocated too many slots, causing data skew.
Countermeasures
Use the CLUSTER SLOTS command to view the slot allocation situation, and use the CLUSTER SETSLOT, CLUSTER GETKEYSINSLOT, and MIGRATE commands to migrate slot data. The specific content is not detailed here; those who are interested can learn it by themselves.
4. Hash Tag Causes Skew
Hash Tag Definition: It refers to the case when a key contains {}, and the entire key is not hashed, but only the string included in {} is hashed.
Assuming the hash algorithm is sha1. For user:{user1}:ids and user:{user1}:tweets, their hash values are all equal to sha1(user1).
Hash Tag Advantage: If the Hash Tag content of different keys is the same, then the data corresponding to these keys will be mapped to the same Slot and allocated to the same instance.
Hash Tag Disadvantage: If used improperly, it may lead to a large amount of data being concentrated on a single instance, causing data skew and unbalanced load in the cluster.
2.2.2 Data Access Skew (Read Skew - Hot Key Problem)
Generally speaking, data access skew is caused by hot key problems, and how to deal with Redis hot key problems is often asked in interviews. Therefore, understanding the relevant concepts and methodologies is an indispensable part.
1. Illustration
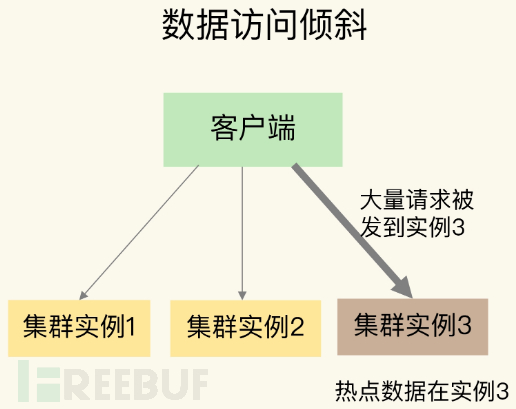
As shown in the figure, although the data volume on each cluster instance is not very different, but the data on a certain instance is hot data, which is accessed very frequently.
But why do hot data appear?
2. Causes and hazards of hot keys
1) The data consumed by users is much greater than the data produced (hot-selling goods, hot news, hot comments, star live broadcasts).
In daily work and life, some sudden events, such as the price reduction promotion of some popular products during the Double Eleven period, when one of these products is clicked, browsed, or purchased tens of thousands of times, it will form a large demand, which will cause hot spot problems in this case.
Similarly, hot news, hot comments, star live broadcasts, etc., which are widely published and browsed, these typical read-many-write-few scenarios will also cause hot spot problems.
2) Request sharding concentration, exceeding the performance limit of a single Server.
When reading data for access on the service side, data is often split and sliced, and during this process, the corresponding Key will be accessed on a certain host Server. When the access exceeds the Server's extreme limit, it will lead to the emergence of hot key problems.
If the hotspots are too concentrated and there are too many hot key caches, exceeding the current cache capacity, it will lead to the phenomenon of cache sharding service being overwhelmed. After the cache service crashes, if there are any requests generated at this time, they will be cached on the background DB. Since the DB itself has weak performance, it is easy to have a request penetration phenomenon when facing large requests, which will further lead to a cascading phenomenon, seriously affecting the performance of the device.
3. Common solutions to hotkey problems:
Solution one: Backup hot keys
Hot data can be copied multiple times, and a random suffix is added to the key of each data copy, so that it will not be mapped to the same Slot as other copies of data.
This is equivalent to copying a piece of data to other instances, so that when accessing, it also adds a random prefix, which distributes the access pressure to other instances.
For example:
When we put the cache in, we split the corresponding business cache key into multiple different keys. As shown in the figure below, we first split the key into N parts on the side of updating the cache, for example, if a key name is 'good_100', we can split it into four parts, 'good_100_copy1', 'good_100_copy2', 'good_100_copy3', 'good_100_copy4'. We need to change these N keys every time we update and add, and this step is to split the key.
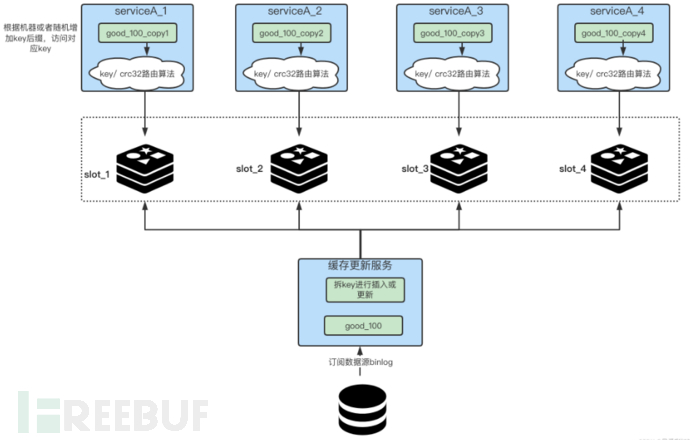
For the service end, we need to try our best to make the traffic we access as even as possible.
How to add a suffix to the hot key you are about to access? Several methods, according to the hash of the local machine's IP or MAC address, the value after that is taken modulo the number of split keys, and finally decide on the type of key suffix to be concatenated to reach which machine; the random number at the service startup is taken modulo the number of split keys.
Pseudocode is as follows:
const M = N * 2
//Generate a random number
random = GenRandom(0, M)
//Construct a new backup key
bakHotKey = hotKey + “_” + random
data = redis.GET(bakHotKey)
if data == NULL {
data = GetFromDB()
redis.SET(bakHotKey, expireTime + GenRandom(0,5))
}Solution two: Local cache + dynamic calculation automatically discover hot cache
Basic flow chart
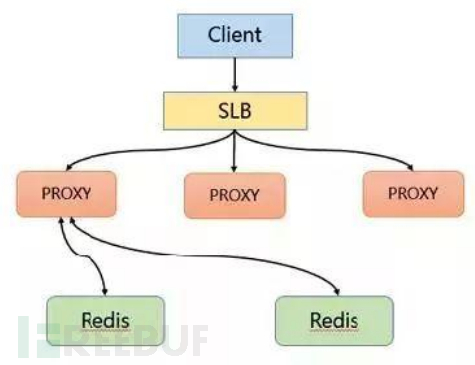
This solution solves the problem of hot Key by actively discovering hot data and storing it. First, the Client will also access the SLB, and various requests will be distributed to the Proxy through the SLB. The Proxy will forward requests to the backend Redis based on routing.
The solution for hot Key is to increase caching on the server side. Specifically, local caching is added on the Proxy, and the LRU algorithm is used to cache hot data. The backend node adds a hot data calculation module to return hot data.
The main advantages of the Proxy architecture are as follows:
Proxy caches hot data locally, and the reading capability can be horizontally expanded
DB nodes calculate the hot data set at regular intervals
DB feedback Proxy hot data
Completely transparent to the client, no compatibility is required
Discovery and storage of hot data
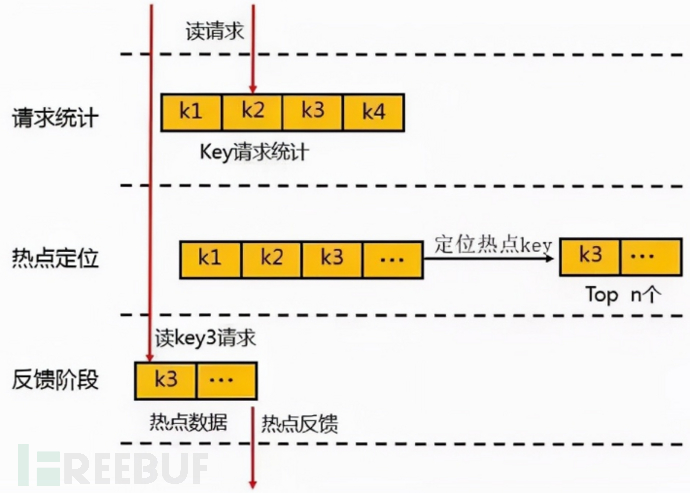
For the discovery of hot data, the request statistics of Key will be carried out within a cycle first. After reaching the level of requests, the hot Key will be located, and all hot Keys will be placed in a small LRU linked list. When accessing through Proxy requests, if Redis finds that the point to be visited is a hot point, it will enter a feedback stage and mark the data at the same time.
An etcd or zk cluster can be used to store the feedback hot data, and then all local nodes monitor the hot data and load it into the local JVM cache.
Acquisition of hot data
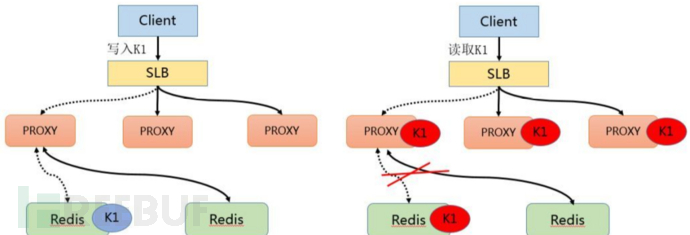
The handling of hot Key is mainly divided into two forms: write and read. In the data writing process, when the SLB receives data K1 and writes it to a Redis through a certain Proxy, the data writing is completed.
If the backend hot point module calculates that K1 becomes a hot key, the Proxy will cache the hot point, and when the client accesses K1 again, it can bypass Redis.
Finally, since the proxy can be horizontally expanded, it can arbitrarily enhance the access capability of hot data.
Best mature solution: JD open-source hotKey
This is a relatively mature automatic detection of hotkey and distributed consistency caching solution. The principle is to do insight on the client side, then report the corresponding hotkey. After the server detects it, it will send the corresponding hotkey to the corresponding service end for local caching, and ensure the consistency of local caching and remote caching.
We will not go into detail here. The third part of this article: JD open-source hotkey source code analysis will lead everyone to understand its overall principle.
3 JD open-source hotkey—Automatic detection of hotkey, distributed consistency caching solution
3.1 Solve pain points
From the above, it can be seen that the problem of hot key occurs frequently in systems with high concurrency (especially in秒杀 activities), and it also brings great harm to the system.
Then, what is the purpose of hotkey's birth for this? What pain points need to be solved, and what is its implementation principle?
Here is a quote from the project to summarize:
For any sudden hot data that cannot be perceived in advance, including but not limited to hot data (such as a large number of requests for the same product), hot users (such as malicious crawlers), hot interfaces (sudden massive requests for the same interface), etc., it can be accurately detected in milliseconds. Then, these hot data and hot users are pushed to the JVM memory of all service端, which can greatly reduce the impact on the backend data storage layer, and the user can decide how to allocate and use these hotkeys (such as local caching for hot products, denying access to hot users, or circuit breaking or returning default values for hot interfaces). These hot data are consistent across the entire service cluster and isolated in business.
Core function: Detect hot data and push it to each server in the cluster
3.2 Integration method
The integration method is not described in detail here. Those who are interested can search for it themselves.
3.3 Source code analysis
3.3.1 Architecture overview
1. Panorama view
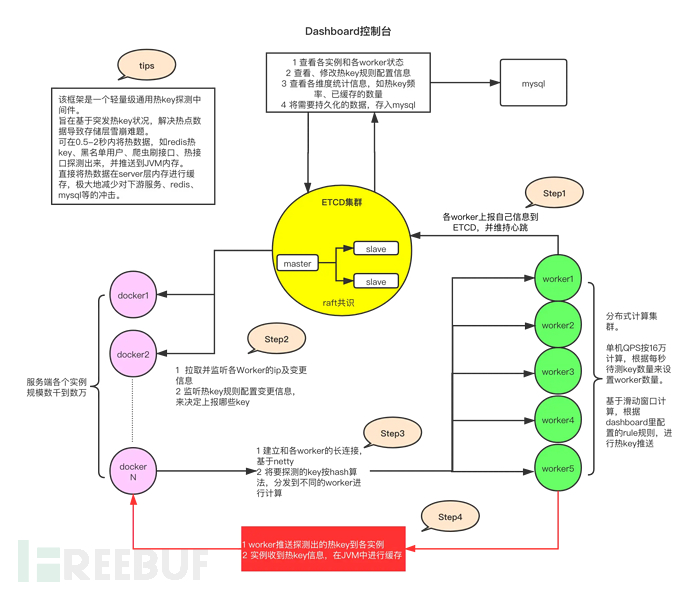
Process introduction:
The client reports its own information to the worker and establishes a long connection with the worker at startup, through the client package of hotkey. It regularly pulls the rule information and worker cluster information from the configuration center.
The client calls the ishot() method of hotkey to first match the rules, and then count whether it is a hotkey.
Upload hot key data to the worker node through scheduled tasks.
After the worker cluster receives all the data about this key (because the key is uploaded to which worker is decided by hash, so the same key will only be on the same worker node), it will match with the defined rules to judge whether it is a hot key. If it is, it will be pushed to the client side to complete local caching.
2. Role Composition
Here we directly borrow the author's description:
1) Etcd Cluster
Etcd, as a high-performance configuration center, can provide efficient listening and subscription services with minimal resource consumption. It is mainly used to store rule configurations, IP addresses of various workers, and detected hot keys, manually added hot keys, etc.
2) Client Side Jar Package
It is a reference jar added to the service, and after being introduced, it can be used to conveniently judge whether a key is a hot key. At the same time, this jar completes key reporting, monitoring changes in the rule in etcd, worker information changes, hot key changes, and local caffeine caching for hot keys.
3) Worker Side Cluster
The worker side is an independently deployed Java program that connects to etcd after startup and regularly reports its IP information, providing addresses for client sides to establish long connections. After that, the main task is to accumulate and calculate the keys sent by various client sides for testing, and push the hot keys to the client sides when the rule threshold set in etcd is reached.
4) Dashboard Console
The console is a Java program with a visual interface, which is connected to etcd, and then sets the key rules for various APPs in the console, such as 20 times in 2 seconds being considered hot. Then when the worker detects a hot key, it will send the key to etcd, and the dashboard will also monitor the hot key information for storage and record. At the same time, the dashboard can also manually add or delete hot keys for monitoring by various client sides.
3. Hotkey Project Structure
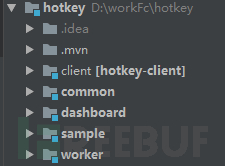
3.3.2 Client Side
Mainly from the following three aspects to analyze the source code:
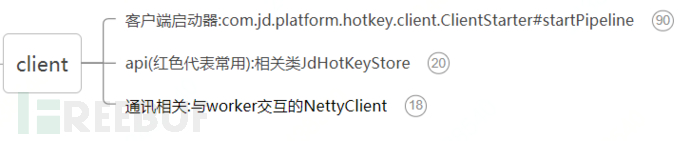
4. Client Starter
1) Start Method
@PostConstruct
public void init() {
ClientStarter.Builder builder = new ClientStarter.Builder();
ClientStarter starter = builder.setAppName(appName).setEtcdServer(etcd).build();
starter.startPipeline();
}appName: is the name of this application, usually the value of ${spring.application.name}, and all subsequent configurations start with this.
etcd: is the address of the etcd cluster, separated by commas, the configuration center.
You can also see that ClientStarter implements the Builder pattern, making the code more concise.
2) Core entry point
com.jd.platform.hotkey.client.ClientStarter#startPipeline
/**
* Start listening to etcd
*/
public void startPipeline() {
JdLogger.info(getClass(), "etcdServer:" + etcdServer);
//Set the maximum capacity of caffeine
Context.CAFFEINE_SIZE = caffeineSize;
//Set etcd address
EtcdConfigFactory.buildConfigCenter(etcdServer);
//Start scheduled pushing
PushSchedulerStarter.startPusher(pushPeriod);
PushSchedulerStarter.startCountPusher(10);
//Enable worker reconnection
WorkerRetryConnector.retryConnectWorkers();
registEventBus();
EtcdStarter starter = new EtcdStarter();
//All listeners related to etcd are enabled
starter.start();
}This method mainly has five functions:
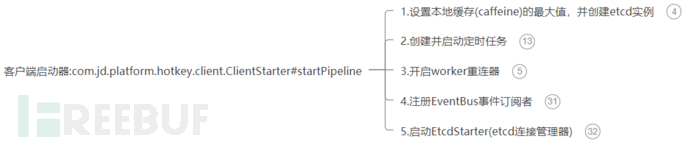
① Set the maximum value of the local cache (caffeine) and create an etcd instance
//Set the maximum capacity of caffeine Context.CAFFEINE_SIZE = caffeineSize; //Set etcd address EtcdConfigFactory.buildConfigCenter(etcdServer);
caffeineSize is the maximum value of the local cache, which can be set at startup, and defaults to 200000 if not set.
etcdServer is the etcd cluster address mentioned above.
Context can be understood as a configuration class, which contains two fields:
public class Context {
public static String APP_NAME;
public static int CAFFEINE_SIZE;
}EtcdConfigFactory is the factory class for the etcd configuration center
public class EtcdConfigFactory {
private static IConfigCenter configCenter;
private EtcdConfigFactory() {}
public static IConfigCenter configCenter() {
return configCenter;
}
public static void buildConfigCenter(String etcdServer) {
//Comma-separated when connecting multiple
configCenter = JdEtcdBuilder.build(etcdServer);
}
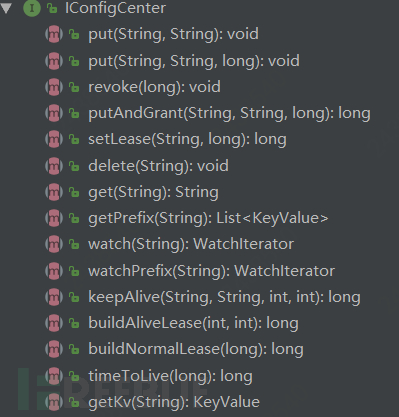
}Get the etcd instance object by calling the configCenter() method, and the IConfigCenter interface encapsulates the behavior of the etcd instance object (including basic crud, monitoring, lease renewal, etc.)
② Create and start scheduled task: PushSchedulerStarter
//Start scheduled pushingPushSchedulerStarter.startPusher(pushPeriod);//Push the to-be-tested key every 0.5 secondsPushSchedulerStarter.startCountPusher(10);//Push the count statistics every 10 seconds, not configurable
pushPeriod is the interval time for pushing, which can be set when starting, the minimum is 0.05s, the faster the push, the denser the detection, and the faster the detection can be made, but the corresponding increase in client resource consumption
PushSchedulerStarter class
/**
* Push the to-be-tested key every 0.5 seconds
*/
public static void startPusher(Long period) {
if (period == null || period <= 0) {
period = 500L;
}
@SuppressWarnings("PMD.ThreadPoolCreationRule")
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("hotkey-pusher-service-executor", true));
scheduledExecutorService.scheduleAtFixedRate(() -> {
//Hotkey collector
IKeyCollector<HotKeyModel, HotKeyModel> collectHK = KeyHandlerFactory.getCollector();
//Here, every 0.5 seconds, the collected hotkey information is pushed to the worker through netty, mainly some metadata information of hotkeys (the app source of the hotkey, the type of the key, and whether it is a delete event, as well as the number of reports of the hotkey)
//This is also where a global unique ID is generated for each report of the hotkey, and the creation time of each report of the hotkey is generated when netty sends it, and the time of the same batch of hotkeys is the same
List<HotKeyModel> hotKeyModels = collectHK.lockAndGetResult();
if(CollectionUtil.isNotEmpty(hotKeyModels)){
//Accumulated key set for half a second, distributed to different workers based on hash
KeyHandlerFactory.getPusher().send(Context.APP_NAME, hotKeyModels);
collectHK.finishOnce();
}
,0, period, TimeUnit.MILLISECONDS);
}
/**
* Push the count statistics every 10 seconds
*/
public static void startCountPusher(Integer period) {
if (period == null || period <= 0) {
period = 10;
}
@SuppressWarnings("PMD.ThreadPoolCreationRule")
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("hotkey-count-pusher-service-executor", true));
scheduledExecutorService.scheduleAtFixedRate(() -> {
IKeyCollector<KeyHotModel, KeyCountModel> collectHK = KeyHandlerFactory.getCounter();
List<KeyCountModel> keyCountModels = collectHK.lockAndGetResult();
if(CollectionUtil.isNotEmpty(keyCountModels)){
//Accumulated count for 10 seconds, distributed to different workers based on hash
KeyHandlerFactory.getPusher().sendCount(Context.APP_NAME, keyCountModels);
collectHK.finishOnce();
}
}From the above two methods, it can be seen that both implement timed tasks through a scheduled thread pool and are daemon threads.
Let's focus on the KeyHandlerFactory class, which is a rather clever design in the client side, directly translated from the class name as 'key handling factory'. The specific instance object is DefaultKeyHandler:
public class DefaultKeyHandler {
//Pusher for HotKeyMsg messages to Netty
private IKeyPusher iKeyPusher = new NettyKeyPusher();
//Collector for keys to be tested, this includes two maps, where the key is mainly the name of the hotkey, and the value is mainly the metadata information of the hotkey (such as: the app source of the hotkey and the type of key and whether it is a deletion event)
private IKeyCollector<HotKeyModel, HotKeyModel> iKeyCollector = new TurnKeyCollector();
//Count collector, this includes two maps, where the key is the corresponding rule, and HitCount contains the total and hot access times of this rule
private IKeyCollector<KeyHotModel, KeyCountModel> iKeyCounter = new TurnCountCollector();
public IKeyPusher keyPusher() {
return iKeyPusher;
}
public IKeyCollector<HotKeyModel, HotKeyModel> keyCollector() {
return iKeyCollector;
}
public IKeyCollector<KeyHotModel, KeyCountModel> keyCounter() {
return iKeyCounter;
}
}There are three member objects in this class, namely the NettyKeyPusher encapsulating the push of messages to netty, the TurnKeyCollector for key collection to be tested, and the TurnCountCollector for count collection, among which the latter two both implement the interface IKeyCollector<t, v="">, which can effectively aggregate the processing of hotkeys, fully reflecting the high cohesion of the code.
Let's take a look at the NettyKeyPusher class that encapsulates pushing messages to netty:
/**
* Pushes msg to netty's pusher
* @author wuweifeng wrote on 2020-01-06
* @version 1.0
*/
public class NettyKeyPusher implements IKeyPusher {
@Override
public void send(String appName, List<HotKeyModel> list) {
//Accumulated key set for half a second, distributed to different workers based on hash
long now = System.currentTimeMillis();
Map<Channel, List<HotKeyModel>> map = new HashMap<>();
for(HotKeyModel model : list) {
model.setCreateTime(now);
Channel channel = WorkerInfoHolder.chooseChannel(model.getKey());
if (channel == null) {
continue;
}
List<HotKeyModel> newList = map.computeIfAbsent(channel, k -> new ArrayList<>());
newList.add(model);
}
for (Channel channel : map.keySet()) {
try {
List<HotKeyModel> batch = map.get(channel);
HotKeyMsg hotKeyMsg = new HotKeyMsg(MessageType.REQUEST_NEW_KEY, Context.APP_NAME);
hotKeyMsg.setHotKeyModels(batch);
channel.writeAndFlush(hotKeyMsg).sync();
} catch (Exception e) {}}
try {
InetSocketAddress insocket = (InetSocketAddress) channel.remoteAddress();
JdLogger.error(getClass(),"flush error " + insocket.getAddress().getHostAddress());
}
JdLogger.error(getClass(),"flush error");
}
}
}
}
@Override
public void sendCount(String appName, List<KeyCountModel> list) {
//Accumulated count for 10 seconds, distributed to different workers based on hash
long now = System.currentTimeMillis();
Map<Channel, List<KeyCountModel>> map = new HashMap<>();
for(KeyCountModel model : list) {
model.setCreateTime(now);
Channel channel = WorkerInfoHolder.chooseChannel(model.getRuleKey());
if (channel == null) {
continue;
}
List<KeyCountModel> newList = map.computeIfAbsent(channel, k -> new ArrayList<>());
newList.add(model);
}
for (Channel channel : map.keySet()) {
try {
List<KeyCountModel> batch = map.get(channel);
HotKeyMsg hotKeyMsg = new HotKeyMsg(MessageType.REQUEST_HIT_COUNT, Context.APP_NAME);
hotKeyMsg.setKeyCountModels(batch);
channel.writeAndFlush(hotKeyMsg).sync();
} catch (Exception e) {}}
try {
InetSocketAddress insocket = (InetSocketAddress) channel.remoteAddress();
JdLogger.error(getClass(),"flush error " + insocket.getAddress().getHostAddress());
}
JdLogger.error(getClass(),"flush error");
}
}
}
}
}send(String appName, List list)
Mainly to push the keys to be tested collected by TurnKeyCollector to the worker through netty, the HotKeyModel object mainly contains some metadata information of hot keys (such as the app source of hot keys, the type of keys, whether it is a deletion event, and the reporting times of the hot key)
sendCount(String appName, List list)
Mainly to push the rules corresponding to the keys collected by TurnCountCollector to the worker through netty, the KeyCountModel object mainly contains some rule information and access counts corresponding to the keys
WorkerInfoHolder.chooseChannel(model.getRuleKey())
The key corresponding to the hash algorithm is obtained and distributed to the corresponding server's Channel connection, so the server can horizontally scale infinitely without any pressure issues.
Let's analyze the key collectors: TurnKeyCollector and TurnCountCollector:
Implement the IKeyCollector interface:
/**
* Aggregates hotkey
* @author wuweifeng wrote on 2020-01-06
* @version 1.0
*/
public interface IKeyCollector<T, V> {
/**
* Return value after locking
*/
List<V> lockAndGetResult();
/**
* Input parameter
*/
void collect(T t);
void finishOnce();
}lockAndGetResult()
It is mainly to obtain the information collected by the collect method and clear the locally stored information to facilitate the accumulation of data in the next statistical period.
collect(T t)
As the name implies, it collects key information during API calls and puts the collected key information into local storage.
finishOnce()
This method currently implements all empty, no need to pay attention.
Test key collector: TurnKeyCollector
public class TurnKeyCollector implements IKeyCollector<HotKeyModel, HotKeyModel> {
//The keys in this map are mainly the names of hotkeys, and the values are mainly metadata information of hotkeys (such as: the app of the source of the hotkey and the type of the key and whether it is a delete event)
private ConcurrentHashMap<String, HotKeyModel> map0 = new ConcurrentHashMap<>();
private ConcurrentHashMap<String, HotKeyModel> map1 = new ConcurrentHashMap<>();
private AtomicLong atomicLong = new AtomicLong(0);
@Override
public List<HotKeyModel> lockAndGetResult() {
//After incrementing, the corresponding map will stop being written and wait to be read
atomicLong.addAndGet(1);
List<HotKeyModel> list;
//By observing the same position as the collect method, you will find that one operates on map0 and the other on map1, ensuring that reading the map does not block writing to the map
//Both maps provide alternating read and write capabilities, designed very cleverly, worth learning
if (atomicLong.get() % 2 == 0) {
list = get(map1);
map1.clear();
}
list = get(map0);
map0.clear();
}
return list;
}
private List<HotKeyModel> get(ConcurrentHashMap<String, HotKeyModel> map) {
return CollectionUtil.list(false, map.values());
}
@Override
public void collect(HotKeyModel hotKeyModel) {
String key = hotKeyModel.getKey();
if (StrUtil.isEmpty(key)) {
return;
}
if (atomicLong.get() % 2 == 0) {
// Return null if it does not exist and put the key-value into it, return the value corresponding to the existing key if there is a key with the same key, and do not overwrite
HotKeyModel model = map0.putIfAbsent(key, hotKeyModel);
if (model != null) {
// Increase the number of times this hotMey is reported
model.add(hotKeyModel.getCount());
}
}
HotKeyModel model = map1.putIfAbsent(key, hotKeyModel);
if (model != null) {
model.add(hotKeyModel.getCount());
}
}
}
@Override
public void finishOnce() {}
}It can be seen that this class has two ConcurrentHashMap<string, hotkeymodel=""> and one AtomicLong. By incrementing the AtomicLong and then taking the modulus of 2, it controls the read and write capabilities of the two maps respectively, ensuring that each map can perform read and write operations, and that the same map cannot perform read and write operations at the same time. This can avoid blocking of concurrent set read and write operations. The lock-free design in this section is very clever and greatly improves the throughput of collection.
Key number collector: TurnCountCollector
The design here is quite similar to TurnKeyCollector, so we won't go into detail. It is worth mentioning that it has a parallel processing mechanism. When the number of collected items exceeds the threshold DATA_CONVERT_SWITCH_THRESHOLD=5000, the lockAndGetResult process uses Java Stream parallel stream processing to improve processing efficiency.</string,>
③ Enable worker reconnection
//Enable worker reconnection
WorkerRetryConnector.retryConnectWorkers();
public class WorkerRetryConnector {
/**
* Reconnect to workers that have not connected on a schedule
*/
public static void retryConnectWorkers() {
@SuppressWarnings("PMD.ThreadPoolCreationRule")
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("worker-retry-connector-service-executor", true));
//Start fetching etcd worker information, if the fetch fails, then continue to fetch on a schedule
scheduledExecutorService.scheduleAtFixedRate(WorkerRetryConnector::reConnectWorkers, 30, 30, TimeUnit.SECONDS);
}
private static void reConnectWorkers() {
List<String> nonList = WorkerInfoHolder.getNonConnectedWorkers();
if (nonList.size() == 0) {
return;
}
JdLogger.info(WorkerRetryConnector.class, "trying to reConnect to these workers :" + nonList);
NettyClient.getInstance().connect(nonList);//This will trigger the netty connection method channelActive
}
}It is also executed through a scheduled thread, with a default time interval of 30s, which cannot be set.
The connection information of the client's worker is controlled by WorkerInfoHolder, which is a List using CopyOnWriteArrayList, as it is a read-heavy and write-light scenario, similar to metadata information.
/** * The mapping relationship between worker's IP address and Channel is saved, which is ordered. Each time the client sends a message, it will hash based on the size of the map * If key-1 is sent to the first Channel of workerHolder, and key-2 is sent to the second Channel */ private static final List<Server> WORKER_HOLDER = new CopyOnWriteArrayList<>();
④ Register EventBus event subscriber
private void registEventBus() {
//Netty connector will pay attention to WorkerInfoChangeEvent event
EventBusCenter.register(new WorkerChangeSubscriber());
//Hot key detection callback to pay attention to hot key events
EventBusCenter.register(new ReceiveNewKeySubscribe());
//Event of Rule change
EventBusCenter.register(new KeyRuleHolder());
}Using guava's EventBus event message bus, leveraging the publisher/subscriber pattern to decouple the project. It can achieve inter-component communication with very little code.
The basic principle diagram is as follows: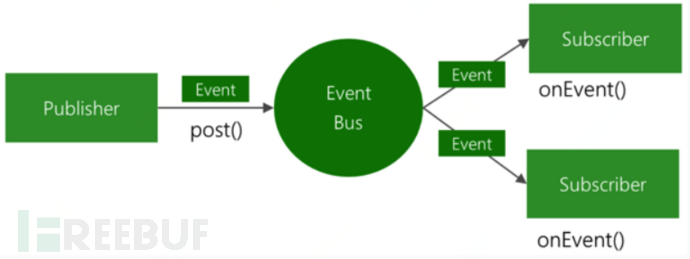
Listen to worker information changes: WorkerChangeSubscriber
/**
* Listen to worker information changes
*/
@Subscribe
public void connectAll(WorkerInfoChangeEvent event) {
List<String> addresses = event.getAddresses();
if (addresses == null) {
addresses = new ArrayList<>();
}
WorkerInfoHolder.mergeAndConnectNew(addresses);
}
/**
* Delete when the connection between client and worker is disconnected
*/
@Subscribe
public void channelInactive(ChannelInactiveEvent inactiveEvent) {
//Get the disconnected channel
Channel channel = inactiveEvent.getChannel();
InetSocketAddress socketAddress = (InetSocketAddress) channel.remoteAddress();
String address = socketAddress.getHostName() + ":" + socketAddress.getPort();
JdLogger.warn(getClass(), "this channel is inactive : " + socketAddress + " trying to remove this connection");
WorkerInfoHolder.dealChannelInactive(address);
}
Listen to hot key callback event: ReceiveNewKeySubscribe
private ReceiveNewKeyListener receiveNewKeyListener = new DefaultNewKeyListener();
@Subscribe
public void newKeyComing(ReceiveNewKeyEvent event) {
HotKeyModel hotKeyModel = event.getModel();
if (hotKeyModel == null) {
return;
}
//Received new key push
if (receiveNewKeyListener != null) {
receiveNewKeyListener.newKey(hotKeyModel);
}
}This method will receive a new hot key subscription event and then add it to the collector of KeyHandlerFactory for processing.
Core processing logic: DefaultNewKeyListener#newKey:
@Override
public void newKey(HotKeyModel hotKeyModel) {
long now = System.currentTimeMillis();
//If the key arrives after 1 second has passed, record it. There is no CreateTime when manually deleting the key
if (hotKeyModel.getCreateTime() != 0 && Math.abs(now - hotKeyModel.getCreateTime()) > 1000) {
JdLogger.warn(getClass(), "the key comes too late : " + hotKeyModel.getKey() + " now ":"
+now + " keyCreateAt " + hotKeyModel.getCreateTime());
}
if (hotKeyModel.isRemove()) {
//If it is a delete event, delete directly
deleteKey(hotKeyModel.getKey());
return;
}
//It is already a hot key, and the same hot key is pushed again, make a log record, and refresh
if (JdHotKeyStore.isHot(hotKeyModel.getKey())) {
JdLogger.warn(getClass(), "receive repeat hot key :" + hotKeyModel.getKey() + " at " + now);
}
addKey(hotKeyModel.getKey());
}
private void deleteKey(String key) {
CacheFactory.getNonNullCache(key).delete(key);
}
private void addKey(String key) {
ValueModel valueModel = ValueModel.defaultValue(key);
if (valueModel == null) {
//Does not meet any rules
deleteKey(key);
return;
}
//If the key already exists, then the value is reset, and the expiration time is also reset. If it does not exist originally,The newly added hot key
JdHotKeyStore.setValueDirectly(key, valueModel);
}
If the HotKeyModel contains a delete event, then get the caffeine corresponding to the timeout time of the key in RULE_CACHE_MAP, then delete the key cache from it, and then return (this is equivalent to deleting the local cache).
If it is not a delete event, then add the cache of the corresponding key in the caffeine cache of RULE_CACHE_MAP.
Here is a point to note, if it is not a delete event, when calling the addKey() method to add cache in caffeine, the value is a magic value 0x12fcf76. This value only indicates that this cache has been added, but this cache is equivalent to null when queried.Listen to the Rule change event: KeyRuleHolder
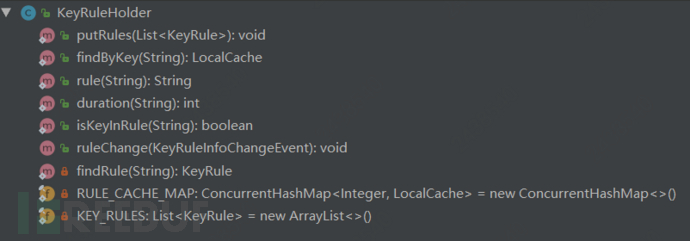
It can be seen that there are two member attributes: RULE_CACHE_MAP, KEY_RULES
/** * Save the mapping of timeout time and caffeine, key is timeout time, value is caffeine[(String,Object)] */ private static final ConcurrentHashMap<Integer, LocalCache> RULE_CACHE_MAP = new ConcurrentHashMap<>(); /** * Here, KEY_RULES saves all the rules corresponding to the appName in etcd */ private static final List<KeyRule> KEY_RULES = new ArrayList<>();
ConcurrentHashMap<integer, localcache=""> RULE_CACHE_MAP:</integer,>
Save the mapping of timeout time and caffeine, key is timeout time, value is caffeine[(String,Object)].
Exquisite design: here, the expiration time of the key is used as the bucketing strategy, so that keys with the same expiration time will be in the same bucket (caffeine). Each caffeine here is the local cache of the client, which means that the local cache of the hotKey's KV is actually stored here.
List KEY_RULES:
- Here, KEY_RULES saves all the rules corresponding to the appName in etcd.
Specific event listening method for KeyRuleInfoChangeEvent:
@Subscribe
public void ruleChange(KeyRuleInfoChangeEvent event) {
JdLogger.info(getClass(), "new rules info is :" + event.getKeyRules());
List<KeyRule> ruleList = event.getKeyRules();
if (ruleList == null) {
return;
}
putRules(ruleList);
}Core processing logic: KeyRuleHolder#putRules:
/**
* All rules, if the timeout of the rules changes, will rebuild caffeine
*/
public static void putRules(List<KeyRule> keyRules) {
synchronized (KEY_RULES) {
//If the rules are empty, clear the rule table
if (CollectionUtil.isEmpty(keyRules)) {
KEY_RULES.clear();
RULE_CACHE_MAP.clear();
return;
}
KEY_RULES.clear();
KEY_RULES.addAll(keyRules);
Set<Integer> durationSet = keyRules.stream().map(KeyRule::getDuration).collect(Collectors.toSet());
for (Integer duration : RULE_CACHE_MAP.keySet()) {
//First, clear those that are stored in RULE_CACHE_MAP but have no rules left in the rule
if (!durationSet.contains(duration)) {
RULE_CACHE_MAP.remove(duration);
}
}
//Iterate through all the rules
for (KeyRule keyRule : keyRules) {
int duration = keyRule.getDuration();
//If there is no value of duration as the timeout in RULE_CACHE_MAP, a new one will be created and added to RULE_CACHE_MAP
//For example, if RULE_CACHE_MAP is initially empty, the mapping relationship of RULE_CACHE_MAP will be constructed here
//TODO If the keyRules contain a keyRule with the same duration, only one key will be created with the value of duration and the value of caffeine, where caffeine is (string, object)
if (RULE_CACHE_MAP.get(duration) == null) {
LocalCache cache = CacheFactory.build(duration);
RULE_CACHE_MAP.put(duration, cache);
}
}
}
}Use the synchronized keyword to ensure thread safety;
If the rule is empty, clear the rule table (RULE_CACHE_MAP, KEY_RULES);
Use the passed in keyRules to override KEY_RULES;
Clear the mapping relationship in RULE_CACHE_MAP that does not exist in keyRules;
Iterate through all keyRules, if there is no related timeout time key in RULE_CACHE_MAP, then assign it inside;
⑤ Start EtcdStarter (etcd connection manager)
EtcdStarter starter = new EtcdStarter();
//All listeners related to etcd are enabled
starter.start();
public void start() {
fetchWorkerInfo();
fetchRule();
startWatchRule();
//Listen to hotkey events, only listen to manually added or deleted keys
startWatchHotKey();
}fetchWorkerInfo()
Pull the worker cluster address information allAddress from etcd and update the WORKER_HOLDER in WorkerInfoHolder
/**
* Fetch worker information every 30 seconds
*/
private void fetchWorkerInfo() {
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
//Start fetching etcd worker information, if the fetch fails, then continue to fetch on a schedule
scheduledExecutorService.scheduleAtFixedRate(() -> {
JdLogger.info(getClass(), "trying to connect to etcd and fetch worker info");
fetch();
}, 0, 30, TimeUnit.SECONDS);
}Executed using a timing thread pool, single-threaded.
Timingly fetches from etcd, address /jd/workers/+$appName or default, the time interval cannot be set, the default is 30 seconds, which stores the ip+port of the worker address.
Publish the WorkerInfoChangeEvent event.
Note: The address has $appName or default, configured in the worker, if the worker is placed under a certain appName, then the worker will only participate in the calculation of that app.
fetchRule()
The timing thread executes, single-threaded, the time interval cannot be set, the default is 5 seconds. After successfully pulling the rule configuration and the manually configured hotKey, the thread is terminated (which means it will only be executed once), and the execution will continue if it fails.
private void fetchRule() {
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
//Start fetching etcd worker information, if the fetch fails, then continue to fetch on a schedule
scheduledExecutorService.scheduleAtFixedRate(() -> {
JdLogger.info(getClass(), "trying to connect to etcd and fetch rule info");
boolean success = fetchRuleFromEtcd();
if (success) {
//Fetch the existing hotkey
fetchExistHotKey();
//If the rule fetching and the fetching of the manually configured hotKey are successful, then the scheduled execution thread stops
scheduledExecutorService.shutdown();
}
}, 0, 5, TimeUnit.SECONDS);
}fetchRuleFromEtcd();
Get the rule rules configured for the appName from etcd, address /jd/rules/+$appName.
If the rules are empty, it will clear the local rule configuration cache and all rule key caches by publishing the KeyRuleInfoChangeEvent event.
Publish the KeyRuleInfoChangeEvent event.
fetchExistHotKey();
Get the manually configured hotkey for the appName from etcd, address /jd/hotkeys/+$appName.
Publish the ReceiveNewKeyEvent event, and the content HotKeyModel is not a delete event.
startWatchRule();
/**
* Asynchronously listen to rule rule changes
*/
private void startWatchRule() {
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.submit(() -> {
JdLogger.info(getClass(), "--- begin watch rule change ----");
try {
IConfigCenter configCenter = EtcdConfigFactory.configCenter();
KvClient.WatchIterator watchIterator = configCenter.watch(ConfigConstant.rulePath + Context.APP_NAME);
//If there is a new event, i.e., a rule change, pull all the information again
while (watchIterator.hasNext()) {
//This sentence must be written, next will make it stuck unless there is a real rule change
WatchUpdate watchUpdate = watchIterator.next();
List<Event> eventList = watchUpdate.getEvents();
JdLogger.info(getClass(), "rules info changed. begin to fetch new infos. rule change is " + eventList);
//Full pull of rule information
fetchRuleFromEtcd();
}
} catch (Exception e) {}}
JdLogger.error(getClass(), "watch err");
}
});
}Asynchronously listen to rule changes, using etcd to listen to node changes at the address /jd/rules/+$appName
Use a thread pool, single-threaded, to asynchronously listen to rule changes. If there is an event change, call the fetchRuleFromEtcd() method.
startWatchHotKey();
Asynchronously start listening to hotkey change information, using etcd to listen to the prefix address /jd/hotkeys/+$appName
/**
* Asynchronously start listening to hotkey change information, only manual key information is added in this directory
*/
private void startWatchHotKey() {
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.submit(() -> {
JdLogger.info(getClass(), "--- begin watch hotKey change ----");
IConfigCenter configCenter = EtcdConfigFactory.configCenter();
try {
KvClient.WatchIterator watchIterator = configCenter.watchPrefix(ConfigConstant.hotKeyPath + Context.APP_NAME);
//If there is a new event, i.e., a new key is generated or deleted
while (watchIterator.hasNext()) {
WatchUpdate watchUpdate = watchIterator.next();
List<Event> eventList = watchUpdate.getEvents();
KeyValue keyValue = eventList.get(0).getKv();
Event.EventType eventType = eventList.get(0).getType();
try {
//It can be seen from here that the full path of the node is returned by etcd, and we need to remove the prefix for the key we need
String key = keyValue.getKey().toStringUtf8().replace(ConfigConstant.hotKeyPath + Context.APP_NAME + "/", "");
//If the key is to be deleted, delete it immediately
if (Event.EventType.DELETE == eventType) {
HotKeyModel model = new HotKeyModel();
model.setRemove(true);
model.setKey(key);
EventBusCenter.getInstance().post(new ReceiveNewKeyEvent(model));
}
HotKeyModel model = new HotKeyModel();
model.setRemove(false);
String value = keyValue.getValue().toStringUtf8();
//Add new hotkey
JdLogger.info(getClass(), "etcd receive new key : " + key + " --value:" + value);
//If this is a delete command, do nothing
//TODO There is a question, the lazy delete command issued by the worker automatic detection is skipped, but is the local cache not updated?
//TODO So I guess that in the API of the client to judge whether the cache exists, it should judge whether the value of the related cache is "#[DELETE]#" delete mark
//Clarification: Here, we indeed only listen to manually configured hotKey, the /jd/hotkeys/+$appName address is only manually configured hotKey, and the hotKey automatically detected by the worker is directly informed to the client through the netty channel
if (Constant.DEFAULT_DELETE_VALUE.equals(value)) {
continue;
}
//Manually created value is timestamp
model.setCreateTime(Long.valueOf(keyValue.getValue().toStringUtf8()));
model.setKey(key);
EventBusCenter.getInstance().post(new ReceiveNewKeyEvent(model));
}
} catch (Exception e) {}}
JdLogger.error(getClass(), "new key err :" + keyValue);
}
}
} catch (Exception e) {}}
JdLogger.error(getClass(), "watch err");
}
});
}Use a thread pool, single thread, and asynchronous listen to the change of hotkey
Use etcd to listen to all changes in the current node and its child nodes of the prefix address
Delete node action
Publish the ReceiveNewKeyEvent event, and the content HotKeyModel is the delete event
New or update node action
The value of the event change is the delete mark #[DELETE]#
If it is a delete mark, it represents that it is an automatic detection by the worker or a command that the client needs to delete.
If it is a delete mark, do nothing and skip directly (you can see this from the HotKeyPusher#push method, when performing delete event operations, it will add a node with a value of delete mark to the /jd/hotkeys/+$appName node, and then delete the node at the same path, so that the delete node event above can be triggered, so if it is a delete mark, skip directly).
Not marked for deletion
Publish the ReceiveNewKeyEvent event, the createTime in the HotKeyModel event content is the timestamp corresponding to the kv
Question: The code comments say that only manually added or deleted hotKey is monitored, does it mean that the address /jd/hotkeys/+$appName is just a manually configured address?
Clarification: Here, we indeed only listen to manually configured hotKey, the address /jd/hotkeys/+$appName of etcd is just manually configured hotKey, and the hotKey automatically detected by the worker is directly informed to the client through the netty channel
5. API analysis
1)Flow chart
① Query process
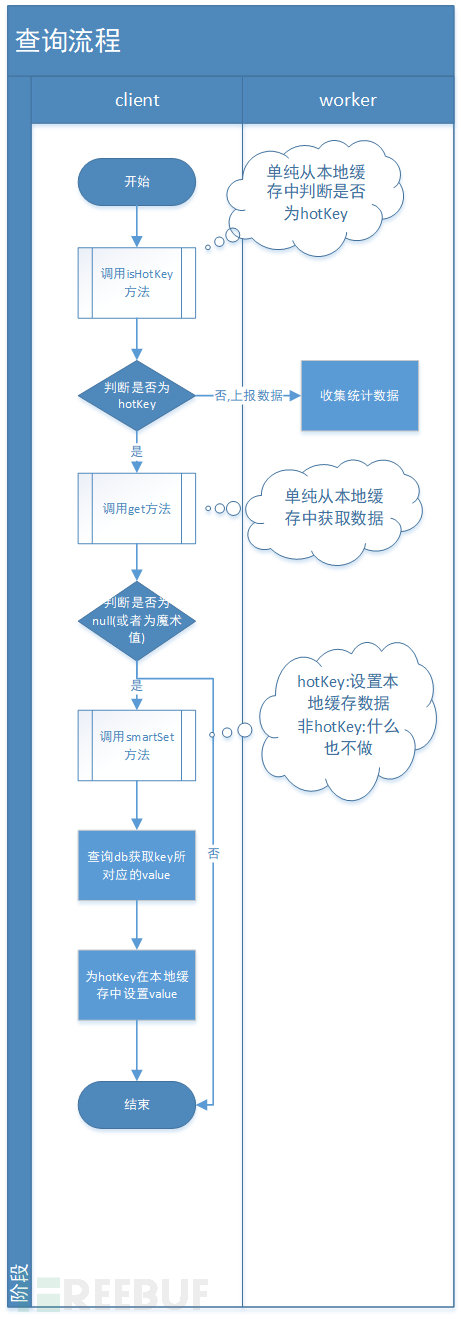
② Deletion process:

From the above flow chart, everyone should know how the hot key is twisted in the code, here we will explain the source code analysis of the core API again, due to the reasons of space, we will not paste the relevant source code one by one, but simply tell you how its internal logic is.
2)Core class: JdHotKeyStore
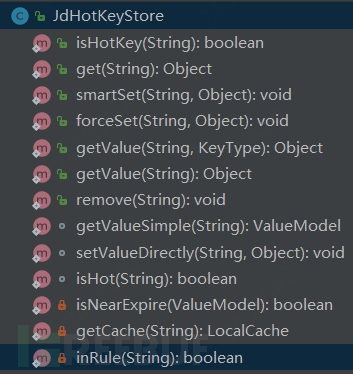
JdHotKeyStore is an encapsulated core class for client API calls, including the above 10 public methods, and we will focus on the analysis of 6 important methods:
① isHotKey(String key)
Determine whether it is in the rule, if not, return false
Determine whether it is a hot key, if it is not or if the expiration time is within 2 seconds, then collect it with TurnKeyCollector#collect
Finally, do statistical collection for TurnCountCollector#collect
② get(String key)
Fetch the value from the local caffeine
If the obtained value is a magic value, it only means that it has been added to the caffeine cache, and the query result will be null
③ smartSet(String key, Object value)
Determine whether it is a hot key, here regardless of whether it is in the rule, if it is a hot key, then assign the value to it, and if it is not a hot key, do nothing
④ forceSet(String key, Object value)
Force assignment to value
If the key is not in the rule configuration, the passed value will not take effect, and the assigned value in the local cache will be set to null
⑤ getValue(String key, KeyType keyType)
Get the value, if the value does not exist, then call the HotKeyPusher#push method to send to netty
If no rules are configured for the key, there is no need to report the key, and directly return null
If the obtained value is a magic value, it only means that it has been added to the caffeine cache, and the query result will be null
⑥ remove(String key)
Deleting a key (local caffeine cache) will notify the entire cluster to delete (notify the cluster to delete through etcd)
3) Client upload hotkey entry class: HotKeyPusher
Core method:
public static void push(String key, KeyType keyType, int count, boolean remove) {
if (count <= 0) {
count = 1;
}
if (keyType == null) {
keyType = KeyType.REDIS_KEY;
}
if (key == null) {
return;
}
//The reason for using LongAdder here is to ensure the thread safety of multi-threaded counting, although it is called within the method, but in the two maps of TurnKeyCollector,
//Stored instances of HotKeyModel, so there will be a thread safety counting inaccuracy problem when multiple threads modify the count attribute at the same time.
LongAdder adderCnt = new LongAdder();
adderCnt.add(count);
HotKeyModel hotKeyModel = new HotKeyModel();
hotKeyModel.setAppName(Context.APP_NAME);
hotKeyModel.setKeyType(keyType);
hotKeyModel.setCount(adderCnt);
hotKeyModel.setRemove(remove);
hotKeyModel.setKey(key);
if (remove) {
//If it is to delete a key, it can be sent directly to etcd without aggregation. But there is a problem now, this deletion can only delete manually added keys, not the ones detected by the worker.
//Because each client is listening to the path manually added, not the path automatically detected. So if there is no such key under the manually added path, it cannot be deleted.
//If it can't be deleted, the effect of the cluster listening for deletion events cannot be achieved. What should be done? You can add a new hotkey and then delete it.
//TODO Why doesn't it directly delete the node? Does the worker's automatic detection of hotKey not add new events to this node?
//Clarification: When the worker determines that a certain key is a hotKey according to the probing configuration rules, it indeed will not add a node to the keyPath, it just simply adds an empty value to the local cache to represent that it is a hot key
EtcdConfigFactory.configCenter().putAndGrant(HotKeyPathTool.keyPath(hotKeyModel), Constant.DEFAULT_DELETE_VALUE, 1);
EtcdConfigFactory.configCenter().delete(HotKeyPathTool.keyPath(hotKeyModel)); // TODO This is very clever, needs to be supplemented with description
//Also delete the directory probed by the worker
EtcdConfigFactory.configCenter().delete(HotKeyPathTool.keyRecordPath(hotKeyModel));
}
//If the key is the key to be probed within the rule, accumulate and wait for transmission
if (KeyRuleHolder.isKeyInRule(key)) {
//Accumulate and wait to send once every half second
KeyHandlerFactory.getCollector().collect(hotKeyModel);
}
}
}From the above source code, we can know:
The reason for using LongAdder here is to ensure the thread safety of multi-threaded counting, although this is called within a method, in the two maps of TurnKeyCollector, HotKeyModel instance objects are stored. This may cause an inaccuracy in thread-safe counting when multiple threads modify the count count attribute at the same time.
If it is a remove deletion type, in addition to deleting the manually configured hot key configuration path, it will also delete the dashboard display hot key configuration path.
Only the keys configured in the rule will be accumulated and sent to the worker for calculation.
6. Communication Mechanism (Interaction with worker)
1) NettyClient: netty connector
public class NettyClient {
private static final NettyClient nettyClient = new NettyClient();
private Bootstrap bootstrap;
public static NettyClient getInstance() {
return nettyClient;
}
private NettyClient() {
if (bootstrap == null) {
bootstrap = initBootstrap();
}
}
private Bootstrap initBootstrap() {
//Few threads
EventLoopGroup group = new NioEventLoopGroup(2);
Bootstrap bootstrap = new Bootstrap();
NettyClientHandler nettyClientHandler = new NettyClientHandler();
bootstrap.group(group).channel(NioSocketChannel.class)
.option(ChannelOption.SO_KEEPALIVE, true)
.option(ChannelOption.TCP_NODELAY, true)
.handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
ByteBuf delimiter = Unpooled.copiedBuffer(Constant.DELIMITER.getBytes());
ch.pipeline()
.addLast(new DelimiterBasedFrameDecoder(Constant.MAX_LENGTH, delimiter))//Here is to define the delimiter between multiple TCP packets for better packet splitting
.addLast(new MsgDecoder())
.addLast(new MsgEncoder())
//If there is no message for 30 seconds, send a heartbeat packet
.addLast(new IdleStateHandler(0, 0, 30))
.addLast(nettyClientHandler);
}
});
return bootstrap;
}
}Using the Reactor thread model, there are only 2 working threads and no separate main thread is set
Netty's delimiter "$( )"
Protobuf serialization and deserialization
Send a heartbeat packet to determine activity if there is no message sent to the opposite party within 30 seconds
Worker thread handler NettyClientHandler
The TCP protocol design of JDhotkey is to send and receive strings, and each TCP message packet is separated by a special character $( )$
Advantages: The implementation is very simple.
After obtaining the message packet, perform JSON or Protobuf deserialization.
Disadvantages: It needs to deserialize from byte stream to string to deserialize into a message object, and two-level serialization consumes some performance.
Protobuf serialization is fast, but the speed of JSON serialization is only a few hundred thousand per second, which will consume some performance.
2) NettyClientHandler: Worker thread handler
@ChannelHandler.Sharable
public class NettyClientHandler extends SimpleChannelInboundHandler<HotKeyMsg> {
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
IdleStateEvent idleStateEvent = (IdleStateEvent) evt;
//This indicates that if both read and write are down
if (idleStateEvent.state() == IdleState.ALL_IDLE) {
//Send a message to the server
ctx.writeAndFlush(new HotKeyMsg(MessageType.PING, Context.APP_NAME));
}
}
super.userEventTriggered(ctx, evt);
}
//The channelActive method of ChannelInboundHandler may be called when Channel is registered to EventLoop, bound to SocketAddress, and connected to ChannelFuture
//After the TCP three-way handshake is successful, this is triggered
@Override
public void channelActive(ChannelHandlerContext ctx) {
JdLogger.info(getClass(), "channelActive:" + ctx.name());
ctx.writeAndFlush(new HotKeyMsg(MessageType.APP_NAME, Context.APP_NAME));
}
//Similar to the TCP four-handshake after, wait for 2MSL time after triggering (about 180s), such as the channel channel is closed to trigger (channel.close())
//When the client channel closes the connection actively, it will send a write request to the server, and then the selector of the server channel will listen to an OP_READ event, and then
//Execute data read operation, and during the read, it is found that the client channel has been closed.If the number of data bytes read is -1, then the close operation will be executed, closing the underlying socket corresponding to the channel.
//And in the pipeline, from the head, downwards the InboundHandler, and trigger the execution of the handler's channelInactive and channelUnregistered methods, as well as a series of operations to remove handlers from the pipeline.
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
super.channelInactive(ctx);
//Disconnected, it may be that the client and server are disconnected, but both are not disconnected from etcd. It may also be that the client is disconnected from the internet, or the server is disconnected.
//Publish disconnection event. After 10 seconds, reconnect will be attempted. Reconnect will be determined based on the worker information in etcd. If there is no information in etcd, no reconnect will be performed. If there is information in etcd, a reconnect will be attempted.
notifyWorkerChange(ctx.channel());
}
private void notifyWorkerChange(Channel channel) {
EventBusCenter.getInstance().post(new ChannelInactiveEvent(channel));
}
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, HotKeyMsg msg) {
if (MessageType.PONG == msg.getMessageType()) {}}
JdLogger.info(getClass(), "heart beat");
return;
}
if (MessageType.RESPONSE_NEW_KEY == msg.getMessageType()) {
JdLogger.info(getClass(), "receive new key : " + msg);
if (CollectionUtil.isEmpty(msg.getHotKeyModels())) {
return;
}
for (HotKeyModel model : msg.getHotKeyModels()) {
EventBusCenter.getInstance().post(new ReceiveNewKeyEvent(model));
}
}
}
}userEventTriggered
- Return new HotKeyMsg(MessageType.PING, Context.APP_NAME) when receiving the heartbeat packet from the other end
channelActive
- The channelActive method of ChannelInboundHandler may be called when registering EventLoop, binding SocketAddress, and connecting ChannelFuture in Channel
- Triggered after TCP three-way handshake is successful, send new HotKeyMsg(MessageType.APP_NAME, Context.APP_NAME) to the other end
channelInactive
- Similar to TCP four-way handshake, wait for 2MSL time after that (about 180s), for example, the channel.close() method will be triggered when the channel is closed, publish ChannelInactiveEvent event, and reconnect after 10s
channelRead0
- Log a message and return when receiving PONG message type
- Publish ReceiveNewKeyEvent event when receiving RESPONSE_NEW_KEY message type
3.3.3 Worker side
1. Entry startup loading: 7@PostConstruct
1) Worker side processing related to etcd: EtcdStarter
① The first@PostConstruct:watchLog()
@PostConstruct
public void watchLog() {
AsyncPool.asyncDo(() -> {
try {
//Get the log configuration status of etcd, address /jd/logOn
String loggerOn = configCenter.get(ConfigConstant.logToggle);
LOGGER_ON = "true".equals(loggerOn) || "1".equals(loggerOn);
} catch (StatusRuntimeException ex) {
logger.error(ETCD_DOWN);
}
//Monitor the etcd address /jd/logOn to check if the log configuration is enabled, and change the switch in real time
KvClient.WatchIterator watchIterator = configCenter.watch(ConfigConstant.logToggle);
while (watchIterator.hasNext()) {
WatchUpdate watchUpdate = watchIterator.next();
List<Event> eventList = watchUpdate.getEvents();
KeyValue keyValue = eventList.get(0).getKv();
logger.info("log toggle changed : " + keyValue);
String value = keyValue.getValue().toStringUtf8();
LOGGER_ON = "true".equals(value) || "1".equals(value);
}
});
}- Execute asynchronously in the thread pool
- Get the log configuration enabled from etcd, address /jd/logOn, default true
- Monitor the etcd address /jd/logOn to check if the log configuration is enabled, and change the switch in real time
- Due to the etcd listener, it will keep executing instead of ending after one execution
② The second@PostConstruct:watch()
/**
* Start the callback listener to monitor rule changes
*/
@PostConstruct
public void watch() {
AsyncPool.asyncDo(() -> {
KvClient.WatchIterator watchIterator;
if (isForSingle()) {
watchIterator = configCenter.watch(ConfigConstant.rulePath + workerPath);
}
watchIterator = configCenter.watchPrefix(ConfigConstant.rulePath);
}
while (watchIterator.hasNext()) {
WatchUpdate watchUpdate = watchIterator.next();
List<Event> eventList = watchUpdate.getEvents();
KeyValue keyValue = eventList.get(0).getKv();
logger.info("rule changed : " + keyValue);
try {
ruleChange(keyValue);
} catch (Exception e) {}}
e.printStackTrace();
}
}
});
}
/**
* Update the cached rule when the rule changes
*/
private synchronized void ruleChange(KeyValue keyValue) {
String appName = keyValue.getKey().toStringUtf8().replace(ConfigConstant.rulePath, "");
if (StrUtil.isEmpty(appName)) {
return;
}
String ruleJson = keyValue.getValue().toStringUtf8();
List<KeyRule> keyRules = FastJsonUtils.toList(ruleJson, KeyRule.class);
KeyRuleHolder.put(appName, keyRules);
}Through the etcd.workerPath configuration, determine whether the worker is serving a single app, the default is ”default”, if it is the default value, it means that the worker participates in the calculation of all app clients on etcd, otherwise, it is only for the calculation of a single app
Use etcd to monitor the change of rule rules, if it is a shared worker, the prefix of the monitoring address is ”/jd/rules/”, if it is for a specific app alone, the monitoring address is ”/jd/rules/”+$etcd.workerPath
If the rule changes, modify the rule cache in the local storage corresponding to the app, and clean up the KV cache in the local storage of the app
KeyRuleHolder: local storage for rule cache
- Map<string, list<keyrule="">> RULE_MAP, this map is a concurrentHashMap, where the kv are appName and the corresponding rule
- The difference between KeyRuleHolder in client: the worker stores all app rules, each app corresponds to a rule bucket, so a map is used
CaffeineCacheHolder: local storage for key cache
- Map<string, cache<string,="" object="">> CACHE_MAP, which is also a concurrentHashMap, where the kv are appName and the corresponding kv's caffeine
- Compared to client's caffeine, the first is that the worker does not have a cache interface like LocalCache, and the second is that the kv of the client's map are the timeout time and the cache bucket corresponding to the key with the same timeout time
Place it in the thread pool for asynchronous execution, since there is etcd monitoring, it will keep executing instead of stopping after one execution
③ The third@PostConstruct:watchWhiteList()
/**
* Start the callback listener to listen to whitelist changes, only listen to the app I am in, and ignore the whitelist key in hotkey calculation
*/
@PostConstruct
public void watchWhiteList() {
AsyncPool.asyncDo(() -> {
//Get all whitelist from etcd configuration
fetchWhite();
KvClient.WatchIterator watchIterator = configCenter.watch(ConfigConstant.whiteListPath + workerPath);
while (watchIterator.hasNext()) {
WatchUpdate watchUpdate = watchIterator.next();
logger.info("whiteList changed ");
try {
fetchWhite();
} catch (Exception e) {}}
e.printStackTrace();
}
}
});
}- Pull and listen to the etcd whitelist key configuration, the address is /jd/whiteList/+$etcd.workerPath
- The key in the whitelist does not participate in hotkey calculation and is ignored directly
- Place it in the thread pool for asynchronous execution, since there is etcd monitoring, it will keep executing instead of stopping after one execution
④ The fourth@PostConstruct:makeSureSelfOn()/** * Check occasionally to see if I am still in etcd */ @PostConstruct public void makeSureSelfOn() { //Open the upload of worker information ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(); scheduledExecutorService.scheduleAtFixedRate(() -> { try { if (canUpload) { uploadSelfInfo(); } } catch (Exception e) {}} //do nothing } }, 0, 5, TimeUnit.SECONDS); }
Execute asynchronously in the thread pool, execute at regular intervals, and the time interval is 5s
Report the hostName, ip+port of the local woker in kv format to etcd at regular intervals, the address is /jd/workers/+$etcd.workPath+”/“+$hostName, and the renewal period is 8s
There is a canUpload switch to control whether the worker should renew the lease with etcd at regular intervals. If this switch is turned off, it means that the worker will not renew the lease with etcd. In this way, when the kv at the above address expires, etcd will delete the node, and the client will continue to judge whether the worker information has changed
2) Push hot keys to dashboard for storage: DashboardPusher
① The fifth@PostConstruct:uploadToDashboard()
@Component
public class DashboardPusher implements IPusher {
/**
* Hot key concentration camp
*/
private static LinkedBlockingQueue<HotKeyModel> hotKeyStoreQueue = new LinkedBlockingQueue<>();
@PostConstruct
public void uploadToDashboard() {
AsyncPool.asyncDo(() -> {
while (true) {
try {
//Either the key reaches 1 thousand or reaches 1 second, then summarize and report to etcd once
List<HotKeyModel> tempModels = new ArrayList<>();
Queues.drain(hotKeyStoreQueue, tempModels, 1000, 1, TimeUnit.SECONDS);
if (CollectionUtil.isEmpty(tempModels)) {
continue;
}
//Push hot keys to dashboard
DashboardHolder.flushToDashboard(FastJsonUtils.convertObjectToJSON(tempModels));
} catch (Exception e) {}}
e.printStackTrace();
}
}
});
}
}When the number of hot keys reaches 1000 or every 1s, send the data of hot keys to the dashboard through the netty channel with the dashboard, the data type is REQUEST_HOT_KEY
LinkedBlockingQueue hotKeyStoreQueue: the concentration camp of hot keys calculated by the worker for the dashboard, all the hot keys pushed to the dashboard are stored inside
3) Push to each client server: AppServerPusher
① The sixth@PostConstruct:batchPushToClient()
public class AppServerPusher implements IPusher {
/**
* Hot key concentration camp
*/
private static LinkedBlockingQueue<HotKeyModel> hotKeyStoreQueue = new LinkedBlockingQueue<>();
/**
* The main difference between the push to the app and the dashboard is that the app is pushed every 10ms, while the dashboard is pushed once every 1s
*/
@PostConstruct
public void batchPushToClient() {}}
AsyncPool.asyncDo(() -> {
while (true) {
try {
List<HotKeyModel> tempModels = new ArrayList<>();
//Push once every 10ms
Queues.drain(hotKeyStoreQueue, tempModels, 10, 10, TimeUnit.MILLISECONDS);
if (CollectionUtil.isEmpty(tempModels)) {
continue;
}
Map<String, List<HotKeyModel>> allAppHotKeyModels = new HashMap<>();
//Split out the hotkey set of each app, grouped by app
for (HotKeyModel hotKeyModel : tempModels) {
List<HotKeyModel> oneAppModels = allAppHotKeyModels.computeIfAbsent(hotKeyModel.getAppName(), (key) -> new ArrayList<>());
oneAppModels.add(hotKeyModel);
}
//Iterate through all apps to perform push
for (AppInfo appInfo : ClientInfoHolder.apps) {
List<HotKeyModel> list = allAppHotKeyModels.get(appInfo.getAppName());
if (CollectionUtil.isEmpty(list)) {
continue;
}
HotKeyMsg hotKeyMsg = new HotKeyMsg(MessageType.RESPONSE_NEW_KEY);
hotKeyMsg.setHotKeyModels(list);
//Send to all apps in the entire app
appInfo.groupPush(hotKeyMsg);
}
//Clear unused memory after pushing
allAppHotKeyModels = null;
} catch (Exception e) {}}
e.printStackTrace();
}
}
});
}
}It will group by the appName of the key, and then push through the corresponding app's channelGroup
When the number of hotkeys reaches 10 or every 10ms, send the data of hotkeys through the app's netty channel to the app, with the data type of RESPONSE_NEW_KEY
LinkedBlockingQueue hotKeyStoreQueue: The camp of hot keys calculated by workers for clients, all hot keys to be pushed to clients are stored inside
4) Client instance node processing: NodesServerStarter
① The seventh@PostConstruct:start()
public class NodesServerStarter {
@Value("${netty.port}")
private int port;
private Logger logger = LoggerFactory.getLogger(getClass());
@Resource
private IClientChangeListener iClientChangeListener;
@Resource
private List<INettyMsgFilter> messageFilters;
@PostConstruct
public void start() {
AsyncPool.asyncDo(() -> {
logger.info("netty server is starting");
NodesServer nodesServer = new NodesServer();
nodesServer.setClientChangeListener(iClientChangeListener);
nodesServer.setMessageFilters(messageFilters);
try {
nodesServer.startNettyServer(port);
} catch (Exception e) {}}
e.printStackTrace();
}
});
}
}Executed asynchronously in the thread pool to start the nettyServer on the client side
Both iClientChangeListener and messageFilters will be passed to the netty message handler, where iClientChangeListener will be used for handling channel offline events to delete the offline or timed-out channels in ClientInfoHolder, and messageFilters will act as the message handling filter (chain of responsibility pattern) for netty receiving event messages
② Dependent bean: IClientChangeListener iClientChangeListener
public interface IClientChangeListener {
/**
* New connection detected
*/
void newClient(String appName, String channelId, ChannelHandlerContext ctx);
/**
* Client offline
*/
void loseClient(ChannelHandlerContext ctx);
}Management of clients, newClient (which triggers netty's connection method channelActive), loseClient (which triggers netty's disconnection method channelInactive()) management
Client connection information is mainly in ClientInfoHolder
List apps, here the AppInfo is mainly appName and corresponding channelGroup
The add and remove of apps are mainly through newClient, loseClient
③ Dependencies: List messageFilters
/**
* Filter messages from netty
* @author wuweifeng wrote on 2019-12-11
* @version 1.0
*/
public interface INettyMsgFilter {
boolean chain(HotKeyMsg message, ChannelHandlerContext ctx);
}Filter and process netty messages sent by client to worker, there are four implementation classes, that is, the four filters below are used to process netty messages sent by the client
④ Types of message handling: MessageType
APP_NAME((byte) 1), REQUEST_NEW_KEY((byte) 2), RESPONSE_NEW_KEY((byte) 3), REQUEST_HIT_COUNT((byte) 7), // Hit rate REQUEST_HOT_KEY((byte) 8), // Hot key, worker->dashboard PING((byte) 4), PONG((byte) 5), EMPTY((byte) 6);
Sequence 1: HeartBeatFilter
- If the message type is PING, return PONG to the corresponding client instance
Sequence 2: AppNameFilter
- When the message type is APP_NAME, it means that the client and worker have successfully established a connection, and then the newClient method of iClientChangeListener is called to increase the apps metadata information
Order 3: HotKeyFilter
Process the received message type as REQUEST_NEW_KEY
Firstly, increase 1 to the atomic class HotKeyFilter.totalReceiveKeyCount, which represents the total number of keys received by the worker instance
The publishMsg method, which sends the message through the self-built producer-consumer model (KeyProducer, KeyConsumer), to distribute and consume the message to the producer
- The List in the received message HotKeyMsg
Firstly, judge whether the key in HotKeyModel is in the whitelist, if it is, skip it, otherwise send HotKeyModel through KeyProducer
Order 4: KeyCounterFilter
- Process the received type as REQUEST_HIT_COUNT
- This filter is specifically designed for the dashboard to aggregate keys, so the appName is directly set to the appName configured by the worker
- The data source of this filter is all from client's NettyKeyPusher#sendCount(String appName, List list), and the data in it is accumulated for 10s by default, which can be configured. This is explained in the client
- The constructed new KeyCountItem(appName, models.get(0).getCreateTime(), models) is placed in the blocking queue LinkedBlockingQueue COUNTER_QUEUE, and then CounterConsumer is used to consume and process it, with the consumption logic being single-threaded
- CounterConsumer: hotkey statistics consumer
- It is placed in a public thread pool to be executed by a single thread
- Data is retrieved from the blocking queue COUNTER_QUEUE, and then the statistics of the key are published to etcd at the path /jd/keyHitCount/+ appName + “/“ + IpUtils.getIp() + “-“ + System.currentTimeMillis(), which is used by the client cluster or default of the worker service to store the path of client hotKey access times and total access times, and then let the dashboard subscribe to and display the statistics
2. Three scheduled tasks: 3@Scheduled
1) Scheduled task 1: EtcdStarter#pullRules()
/**
* Pull all app rules every 1 minute
*/
@Scheduled(fixedRate = 60000)
public void pullRules() {
try {
if (isForSingle()) {
String value = configCenter.get(ConfigConstant.rulePath + workerPath);
if (!StrUtil.isEmpty(value)) {
List<KeyRule> keyRules = FastJsonUtils.toList(value, KeyRule.class);
KeyRuleHolder.put(workerPath, keyRules);
}
}
List<KeyValue> keyValues = configCenter.getPrefix(ConfigConstant.rulePath);
for (KeyValue keyValue : keyValues) {
ruleChange(keyValue);
}
}
} catch (StatusRuntimeException ex) {
logger.error(ETCD_DOWN);
}
}Pull the rule changes at the etcd address /jd/rules/ every 1 minute. If the app or default rule served by the worker changes, update the rule cache and clear the local key cache corresponding to the appName
2) Scheduled task 2: EtcdStarter#uploadClientCount()
/**
* Upload the number of clients to etcd every 10 seconds
*/
@Scheduled(fixedRate = 10000)
public void uploadClientCount() {
try {
String ip = IpUtils.getIp();
for (AppInfo appInfo : ClientInfoHolder.apps) {
String appName = appInfo.getAppName();
int count = appInfo.size();
// Even a full gc cannot exceed 3 seconds, because the given expiration time is 13s, since this scheduled task is executed every 10s, if a full gc or the time reported to etcd exceeds 3s,
// Then the number of clients cannot be queried on the dashboard
configCenter.putAndGrant(ConfigConstant.clientCountPath + appName + "/" + ip, count + "", 13);
}
configCenter.putAndGrant(ConfigConstant.caffeineSizePath + ip, FastJsonUtils.convertObjectToJSON(CaffeineCacheHolder.getSize()), 13);
// Report QPS per second (number of received keys, number of processed keys)
String totalCount = FastJsonUtils.convertObjectToJSON(new TotalCount(HotKeyFilter.totalReceiveKeyCount.get(), totalDealCount.longValue()));
configCenter.putAndGrant(ConfigConstant.totalReceiveKeyCount + ip, totalCount, 13);
logger.info(totalCount + " expireCount:" + expireTotalCount + " offerCount:" + totalOfferCount);
// If the application continuously sends keys stably, it is recommended to enable this monitoring to avoid possible network failures
if (openMonitor) {
checkReceiveKeyCount();
}
// configCenter.putAndGrant(ConfigConstant.bufferPoolPath + ip, MemoryTool.getBufferPool() + "", 10);
}
logger.error(ETCD_DOWN);
}
}Every 10 seconds, the client information calculated and stored by the worker is reported to etcd to facilitate the dashboard to query and display, such as /jd/count/for the number of clients, /jd/caffeineSize/for the size of the caffeine cache, /jd/totalKeyCount/for the total number of keys received and processed by the worker
It can be seen from the code that the lease time of all etcd nodes above is 13s, and this scheduled task is executed every 10s, which means if the full gc or the time to report to etcd exceeds 3s, the client's relevant summary information in the dashboard cannot be queried
If the key is not received for a long time, it is judged that the network status is poor, and the lease renewal of the node with the etcd address /jd/workers/+$workerPath is disconnected for the worker, because the client will cyclically judge whether the node of the address changes, causing the client to reconnect to the worker or disconnect from the disconnected worker
3) Scheduled task 3: EtcdStarter#fetchDashboardIp()
/**
* Fetch the dashboard address every 30 seconds
*/
@Scheduled(fixedRate = 30000)
public void fetchDashboardIp() {
try {
// Get DashboardIp
List<KeyValue> keyValues = configCenter.getPrefix(ConfigConstant.dashboardPath);
// Is empty, give a warning
if (CollectionUtil.isEmpty(keyValues)) {
logger.warn("very important warn !!! Dashboard ip is null!!!");
return;
}
String dashboardIp = keyValues.get(0).getValue().toStringUtf8();
NettyClient.getInstance().connect(dashboardIp);
} catch (Exception e) {}}
e.printStackTrace();
}
}Pull the value of the dashboard connection ip with the etcd prefix of /jd/dashboard/ every 30 seconds, and determine whether DashboardHolder.hasConnected is in the unconnected state. If it is, reconnect the worker with the dashboard's netty channel
3. Self-built producer-consumer model (KeyProducer, KeyConsumer)
A general producer-consumer model includes three major elements: producer, consumer, and message storage queue
The message storage queue here is QUEUE in DispatcherConfig, using LinkedBlockingQueue, with a default size of 2 million
1)KeyProducer
@Component
public class KeyProducer {
public void push(HotKeyModel model, long now) {
if (model == null || model.getKey() == null) {
return;
}
//Messages that have expired 5 seconds ago will not be processed
if (now - model.getCreateTime() > InitConstant.timeOut) {
expireTotalCount.increment();
return;
}
try {
QUEUE.put(model);
totalOfferCount.increment();
}
e.printStackTrace();
}
}
}Determine if the received HotKeyModel exceeds the time configured in the "netty.timeOut". If it does, increment the expireTotalCount and return
2)KeyConsumer
public class KeyConsumer {
private IKeyListener iKeyListener;
public void setKeyListener(IKeyListener iKeyListener) {
this.iKeyListener = iKeyListener;
}
public void beginConsume() {
while (true) {
try {
//It can be seen here that the producer-consumer model used here is still a pull model. The reason why EventBus is not used is that a queue is needed for buffering
if (model.isRemove()) {
iKeyListener.removeKey(model, KeyEventOriginal.CLIENT);
iKeyListener.newKey(model, KeyEventOriginal.CLIENT);
}
//Processing completed, increment the count by 1
}
totalDealCount.increment();
catch (InterruptedException e) {
}
e.printStackTrace();
}
}
}
}
@Override
public void removeKey(HotKeyModel hotKeyModel, KeyEventOriginal original) {
//Key in cache, appName+keyType+key
String key = buildKey(hotKeyModel);
hotCache.invalidate(key);
CaffeineCacheHolder.getCache(hotKeyModel.getAppName()).invalidate(key);
//Push deletion to all clients
hotKeyModel.setCreateTime(SystemClock.now());
logger.info(DELETE_KEY_EVENT + hotKeyModel.getKey());
for (IPusher pusher : iPushers) {
//Here you can see that the netty message for deleting the hot key was only sent to the client sideNo message has been sent to dashboard (the remove method in DashboardPusher is an empty method)
pusher.remove(hotKeyModel);
}
}
@Override
public void newKey(HotKeyModel hotKeyModel, KeyEventOriginal original) {
//Key in cache
String key = buildKey(hotKeyModel);
//Determine if it has been hot recently
//hotCache对应的caffeine有效期为5s,也就是说该key会保存5s,在5s内不重复处理相同的hotKey。
//After all, hotKey is instantaneous traffic, which can avoid repeated delivery to client and dashboard within 5s, avoiding invalid network cost
Object o = hotCache.getIfPresent(key);
if (o != null) {
return;
}
//********** Watch here ************//
//This method will be called simultaneously by InitConstant.threadCount threads, and there may be multi-threading issues.
//The addCount below is locked, representing atomic addition of count to Key, which means it will not cause over-addition or under-addition. It will definitely trigger hot when it reaches the set threshold.
//譬如阈值是2,如果多个线程累加,在没hot前,hot的状态肯定是对的,譬如thread1 加1,thread2加1,那么thread2会hot返回true,开启推送
//但是极端情况下,譬如阈值是10,当前是9,thread1走到这里时,加1,返回true,thread2也走到这里,加1,此时是11,返回true,问题来了
//该key会走下面的else两次,也就是2次推送。
//所以出现问题的原因是hotCache.getIfPresent(key)这一句在并发情况下,没return掉,放了两个key+1到addCount这一步时,会有问题
//测试代码在TestBlockQueue类,直接运行可以看到会同时hot
//那么该问题用解决吗,NO,不需要解决,1 首先要发生的条件极其苛刻,很难触发,以京东这样高的并发量,线上我也没见过触发连续2次推送同一个key的
//2 即便触发了,后果也是可以接受的,2次推送而已,毫无影响,客户端无感知。但是如果非要解决,就要对slidingWindow实例加锁了,必然有一些开销
//所以只要保证key数量不多计算就可以,少计算了没事。因为热key必然频率高,漏计几次没事。但非热key,多计算了,被干成了热key就不对了
SlidingWindow slidingWindow = checkWindow(hotKeyModel, key);//从这里可知,每个app的每个key都会对应一个滑动窗口
//看看hot没
boolean hot = slidingWindow.addCount(hotKeyModel.getCount());
if (!hot) {
//如果没hot,重新put,cache会自动刷新过期时间
CaffeineCacheHolder.getCache(hotKeyModel.getAppName()).put(key, slidingWindow);
}
//这里之所以放入的value为1,是因为hotCache是用来专门存储刚生成的hotKey
//hotCache对应的caffeine有效期为5s,也就是说该key会保存5s,在5s内不重复处理相同的hotKey。
//After all, hotKey is instantaneous traffic, which can avoid repeated delivery to client and dashboard within 5s, avoiding invalid network cost
hotCache.put(key, 1);
//Delete this key
//This key is actually specifically for the sliding window, its combination logic is appName+keyType+key, not the hotKey pushed to client and dashboard
CaffeineCacheHolder.getCache(hotKeyModel.getAppName()).invalidate(key);
//Start pushing
hotKeyModel.setCreateTime(SystemClock.now());
//When the switch is turned on, print the log. Turn off the log during the big promotion and do not print
if (EtcdStarter.LOGGER_ON) {
logger.info(NEW_KEY_EVENT + hotKeyModel.getKey());
}
//Deliver to each client and etcd separately
for (IPusher pusher : iPushers) {
pusher.push(hotKeyModel);
}
}
}"thread.count" configuration is the number of consumers, multiple consumers consume a QUEUE queue together
Producer-consumer model, essentially it is a pull model, the reason why EventBus is not used is that a queue is needed for buffering
According to whether the message type is deleted in the HotKeyModel
Deletes the message type
- Build the newkey in caffeine according to the combination of appName + keyType + key name in HotKeyModel, which is mainly used to correspond to the sliding time window slidingWindow in caffeine
- Deletes the cache of newkey in hotCache, the cached kv pairs are newKey and 1, hotCache is used to store the generated hot key, the effective period of caffeine corresponding to hotCache is 5s, which means that the key will be saved for 5s, and the same hotKey will not be processed repeatedly within 5s. After all, hotKey is instantaneous traffic, which can avoid repeated delivery to client and dashboard within 5s, avoiding invalid network cost
- Deletes the newKey in the CaffeineCacheHolder corresponding to the appName in the caffeine, which stores the sliding window
Delivers to all client instances corresponding to the HotKeyModel, used to let the client delete the HotKeyModel
Non-deletion message type
Build the newkey in caffeine according to the combination of appName + keyType + key name in HotKeyModel, which is mainly used to correspond to the sliding time window slidingWindow in caffeine
Determine whether the newkey is just hot by judging through hotCache, and return if it is
Calculate and judge whether the key is a hotKey according to the sliding time window (here you can learn about the design of sliding time window), and return or generate the sliding window corresponding to the newKey
If it does not meet the hotkey standard
By re-putting in CaffeineCacheHolder, the cache will automatically refresh the expiration time
If it meets the hotkey standard
Add the cache corresponding to newkey to hotCache, and set the value to 1 to indicate that it is a new hotkey.
Delete the sliding window cache corresponding to newkey in CaffeineCacheHolder.
Push netty messages to the client of the app corresponding to the hotKeyModel to indicate the generation of new hotKey, so that the client local cache is updated, but the pushed netty messages only represent hotkeys, and the client local cache does not store the value corresponding to the key. It is necessary to call the api in JdHotKeyStore to assign the value to the local cache.
Push hotKeyModel to dashboard to indicate the generation of new hotKey
3) Design of hotkey sliding window calculation
Due to the limitation of space, this will not be discussed in detail here. The project author's explanation article is directly attached: Java Simple Implementation of Sliding Window
3.3.4 Dashboard side
There is nothing much to say, just connect etcd, mysql, and perform CRUD operations. However, JD's front-end framework is very convenient, and you can return a list directly to form a table.
4 Summary
The second part of the article explains the reasons for the data skew in redis and the corresponding solutions, and makes an in-depth analysis of hot issues, summarizing the two key issues from finding hotkeys to solving them.
The third part of the article is the solution to hotkey issues - the source code analysis of JD's open-source hotkey, which is explained in an all-around manner from the client side, worker side, and dashboard side, including its design, usage, and related principles.
Hoping that through this article, everyone can not only learn the relevant methodology, but also understand the specific implementation plan of the methodology, learn and grow together.
Author: Li Peng

评论已关闭