Author: JD Technology, Kang Zhixing
Application scenarios
Many business scenarios in modern Internet, such as flash sales, placing orders, and querying product details, have the characteristic of high concurrency. However, our system cannot withstand such a large flow of traffic, and many countermeasures have been produced: CDN, message queue, multi-level cache, and异地多活.

However, no matter how optimized, it is ultimately the physical characteristics of the hardware that determine the upper limit of our system performance. If we force to receive all requests, it often causes a avalanche.
At this point, the flow control fuse takes effect, limiting the number of requests, quickly failing, and ensuring that the system is fully loaded without exceeding the limit.
The ultimate optimization is to increase the hardware utilization rate to 100%, but it will never exceed 100%
Common flow control algorithms
1. Counter
Direct counting, simple and forceful, let's take an example:
For example, if the flow control is set to 10 times within 1 hour, then the counter is incremented by one each time a request is received, and it is judged whether the counter exceeds the upper limit of 10 within this hour. If it does not exceed the upper limit, it returns success; otherwise, it returns failure.
This algorithm'sDisadvantagesThis is where there will be a larger instantaneous flow at the critical point in time.
Continuing with the above example, in an ideal state, requests enter uniformly and the system processes requests uniformly:
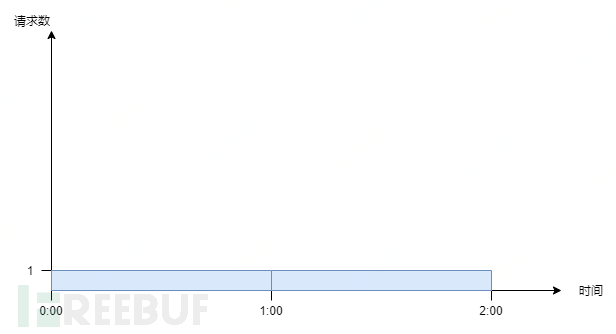
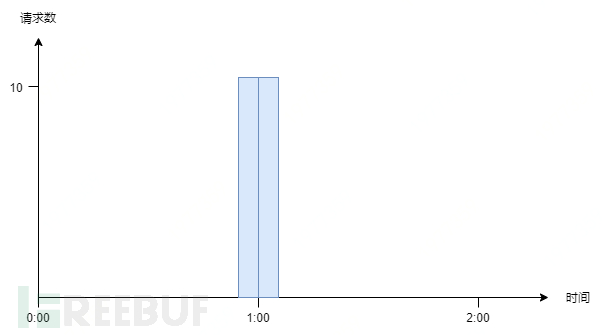
However, in reality, requests often do not enter uniformly. Suppose at 59 minutes and 59 seconds of the nth hour, 10 requests suddenly enter, and all requests are successful, and the counter is refreshed when the next time interval arrives. Then, at the beginning of the (n+1)th hour, another 10 requests enter, which is equivalent to entering 20 requests instantaneously, which certainly does not comply with the rule of '10 times per hour'. This phenomenon is called the 'spike phenomenon'.
To solve this problem, the counter algorithm has been optimized to produceSliding WindowAlgorithm:
We divide the time interval uniformly, for example, dividing a minute into 6 ten-second periods, counting separately within each 10-second period, with the total quantity limit being the sum of these 6 ten-second periods. We call these 6 ten-second periods the “Window”
So every 10 seconds, the window slides forward one step, and the quantity limit becomes the sum of the new 6 ten-second periods, as shown in the figure:
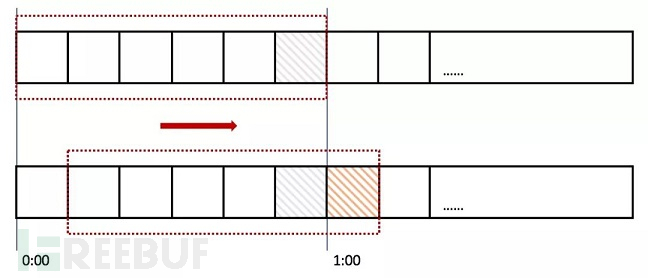
So if at the critical point, 10 requests (gray squares in the diagram) are received, and another 10 requests enter at the start of the next time period, but the window contains the gray part, so the request limit has been reached, and no new requests are accepted.
This isSliding WindowAlgorithm.
However, the sliding window still has flaws. To ensure uniformity, we need to divide the time into as many intervals as possible, and the more intervals, the fewer requests each interval can receive, which limits the system's instantaneous processing capacity.
2. Leaky Bucket
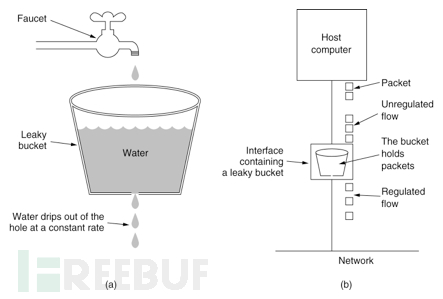
The leaky bucket algorithm is actually quite simple. Suppose we have a bucket with a fixed capacity and a fixed flow rate (system processing capacity). If the water from the faucet flows too much for a period of time, the water overflows (requests are discarded).
In programming terms, each incoming request is placed in a first-in-first-out queue. If the queue is full, a failure is returned directly. Additionally, there is a thread pool that continuously pulls requests from this queue at fixed intervals.
Message queues and JDK thread pools have similar designs.
3. Token Bucket
The token bucket algorithm is slightly more complex than the leaky bucket algorithm.
Firstly, we have a bucket with a fixed capacity, which stores tokens (tokens). Initially, the bucket is empty, and tokens are filled into the bucket at a fixed rate until the capacity of the bucket is reached, and any excess tokens will be discarded. Whenever a request arrives, it attempts to remove a token from the bucket; if there are no tokens, the request cannot pass.
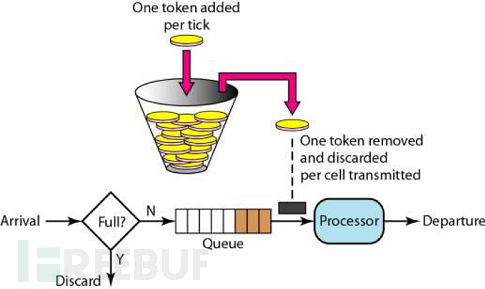
The difference between the leaky bucket and token bucket algorithms is:
The characteristics of the leaky bucket areFixed consumption capacityWhen the request volume exceeds the consumption capacity, it provides certain redundancy, caching the requests and consuming them at a uniform rate. The advantage is that it offers better protection for the downstream.
The token bucket is more accommodating in the face of surging traffic, as long as there are tokens, they can be consumed all at once. It is suitable for traffic with sudden characteristics, such as flash sales scenarios.
Throttling plan
First, container throttling
1. Tomcat
Tomcat can configure the maximum thread number attribute of the connector, this attributemaxThreadsis the maximum thread number of Tomcat, when the concurrent requests are greater thanmaxThreadswhen the request will be queued for execution (Queue size setting: accept-count), thus completing the purpose of throttling.
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
maxThreads="150"
redirectPort="8443" />
2. Nginx
Nginx provides two methods of throttling: one is to control the rate, and the other is to control the number of concurrent connections.
to control the rate
We need to use
limit_req_zoneConfiguration to limit the number of requests within a unit of time, that is, rate limiting, the example configuration is as follows:limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;The first parameter: $binary_remote_addr indicates the restriction by using the identifier remote_addr, the purpose of 'binary_' is to abbreviate the memory usage, and it is to limit the same client IP address.
The second parameter: zone=mylimit:10m indicates the creation of a 10M memory area named one, used to store frequency information of access.
The third parameter: rate=2r/s indicates the frequency of access allowed for clients with the same identifier, here it is limited to 2 times per second, and there can also be like 30r/m.
concurrent connection numbers
Using
limit_conn_zoneandlimit_connTwo commands can control the number of concurrent connections, the example configuration is as followslimit_conn_zone $binary_remote_addr zone=perip:10m; limit_conn_zone $server_name zone=perserver:10m; server { ... limit_conn perip 10; # Limits the same client IP limit_conn perserver 100; }
Only when the request header is processed by the backend, this connection will be counted
Second, server-side throttling
1. Semaphore
provided by the JUC packageSemaphoreTools maintain a synchronized queue internally, and we can try to acquire a semaphore at each request arrival, blocking or failing quickly if we cannot acquire it
Simple example:
Semaphore sp = new Semaphore(3);
sp.require(); // Blocking acquisition
System.out.println("Execute business logic");
sp.release();
2. RateLimiter
A rate-limiting tool based on token bucket in Guava, very simple to use, through the methodcreate()Create a bucket and then throughacquire()ortryAcquire()Token acquisition:
RateLimiter rateLimiter = RateLimiter.create(5); // Initialize the token bucket, placing 5 tokens in the bucket per second
rateLimiter.acquire(); // Spin-block to acquire tokens, return the blocking time, unit is seconds
rateLimiter.tryAcquire(); // Acquire tokens, return boolean result, fail if timeout exceeds (default is 0, unit is milliseconds)
RateLimiter allows the existence of bursty requests in its implementation.
For example, we have a RateLimiter with a rate of 5 tokens per second:
When the token bucket is empty, if one token is continued to be acquired, the result will be returned when the tokens are replenished next time
But if 5 tokens are directly acquired, it is not necessary to wait for the bucket to be replenished with 5 tokens before returning, but it will still be replenished with tokensNextWhen tokens are directly returned, the additional time required for the advance tokens will be compensated in the next request
public void testSmoothBursty() {
RateLimiter r = RateLimiter.create(5);
for (int i = 0; i++ < 2; ) {
System.out.println("get 5 tokens: " + r.acquire(5) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("end");
}
}
/**
* Console output
* get 5 tokens: 0.0s The bucket is empty at initialization, directly obtain 5 tokens from the empty bucket
* get 1 tokens: 0.998068s Lag effect, need to wait for the previous request
* get 1 tokens: 0.196288s
* get 1 tokens: 0.200391s
* end
* get 5 tokens: 0.195756s
* get 1 tokens: 0.995625s Latency effect, needs to wait for the previous request
* get 1 tokens: 0.194603s
* get 1 tokens: 0.196866s
* end
*/
3. Hystrix
A circuit breaker component open-sourced by Netflix, supporting two resource isolation strategies: THREAD (default) or SEMAPHORE
Thread pool: each command runs in a separate thread, and throttling is controlled by the size of the thread pool
Semaphore: the command runs in the calling thread, but is throttled through the semaphore capacity
Thread pool strategy creates a thread pool for each resource to control traffic, the advantage is complete resource isolation, but the disadvantage is that it is easy to cause resource fragmentation.
Example usage:
// HelloWorldHystrixCommand needs to use Hystrix features
public class HelloWorldHystrixCommand extends HystrixCommand {
private final String name;
public HelloWorldHystrixCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
// If it inherits from HystrixObservableCommand, you need to override the Observable construct()
@Override
protected String run() {
return "Hello " + name;
}
}
Call this command:
String result = new HelloWorldHystrixCommand("HLX").execute();
System.out.println(result); // Print out Hello HLX
Hystrix has stopped development in 2018, and the official recommends an alternative projectResilience4j
For more usage instructions, please refer to:The use of Hystrix circuit breaker
4. Sentinel
Alibaba's open-source flow control and circuit breaking component, which uses a sliding window algorithm for underlying statistics. There are two ways to use flow control: API call and annotation, and it uses a slot chain internally to count and execute check rules.
By adding annotations to the method@SentinelResource(String name)Or manually callSphU.entry(String name)Method to enable flow control.
Manual call of flow control using API example:
@Test
public void testRule() {
// Configure rules.
initFlowRules();
int count = 0;
while (true) {
try (Entry entry = SphU.entry("HelloWorld")) {
// Protected logic
System.out.println("run " + ++count + " times");
} catch (BlockException ex) {
// Logic to handle being flow-controlled
System.out.println("blocked after " + count);
break;
}
}
}
// Output result:
// Run 1 times
// Run 2 times
// Run 3 times
For a detailed introduction to Sentinel, please refer to:Sentinel - Traffic sentinel for distributed systems
3. Distributed Flow Control Scheme
In the online environment, if a unified traffic limit is applied to shared resources (such as databases, downstream services), then single-machine flow control is obviously not sufficient, and a distributed flow control scheme is needed.
Distributed flow control mainly adopts the scheme of central system traffic control, with a central system unifiedly controlling the quota of traffic.
The disadvantage of this scheme is the reliability of the central system, so it is generally necessary to have a backup plan. In case the central system is unavailable, it degrades to single-machine flow control.
1. Tair implements simple windowing through the incr method
The implementation is to useincr()Counting by incrementing and comparing with the threshold.
public boolean tryAcquire(String key) {
// Build Tair's key in seconds
String wrappedKey = wrapKey(key);
// Each request increments by 1, with an initial value of 0, and the key's validity set to 5 seconds
Result<Integer> result = tairManager.incr(NAMESPACE, wrappedKey, 1, 0, 5);
return result.isSuccess() && result.getValue() <= threshold;
}
private String wrapKey(String key) {
long sec = System.currentTimeMillis() / 1000L;
return key + ":" + sec;
}
【Note】Explanation of the parameters of the incr method
// Method definition:
Result incr(int namespace, Serializable key, int value, int defaultValue, int expireTime)
/* Parameter meaning:
namespace - The namespace allocated when applying
key - Key list, not exceeding 1k
value - The increment amount
defaultValue - The initial count value of the key when 'incr' is called for the first time, the first returned value is defaultValue + value.
expireTime - Data expiration time, in seconds, can be set as relative time or absolute time (Unix timestamp).
*/
2. Redis implements simple window through Lua scripts
Similar to the Tair implementation, but Redis'sincr()The method cannot set the expiration time atomically, so Lua scripts need to be used. The expiration time is set to 1 second when the first call returns 1.
local current
current = redis.call("incr",KEYS[1])
if tonumber(current) == 1 then
redis.call("expire",KEYS[1],1)
end
return current
3. Redis implements the token bucket through Lua scripts
The implementation idea is to record the 'request time' and 'remaining token quantity' after obtaining the token using SET.
Each time a token is requested, calculate whether the token acquisition is successful based on these parameters, the request time, and the flow rate.
Token acquisition Lua script:
local ratelimit_info = redis.pcall('HMGET',KEYS[1],'last_time','current_token')
local last_time = ratelimit_info[1]
local current_token = tonumber(ratelimit_info[2])
local max_token = tonumber(ARGV[1])
local token_rate = tonumber(ARGV[2])
local current_time = tonumber(ARGV[3])
local reverse_time = 1000/token_rate
if current_token == nil then
current_token = max_token
last_time = current_time
else
local past_time = current_time-last_time
local reverse_token = math.floor(past_time/reverse_time)
current_token = current_token+reverse_token
last_time = reverse_time*reverse_token+last_time
if current_token>max_token then
current_token = max_token
end
end
local result = 0
if(current_token>0) then
result = 1
current_token = current_token-1
end
redis.call('HMSET',KEYS[1],'last_time',last_time,'current_token',current_token)
redis.call('pexpire',KEYS[1],math.ceil(reverse_time*(max_token-current_token)+(current_time-last_time)))
return result
Initialize token bucket lua script:
local result=1
redis.pcall("HMSET",KEYS[1],"last_mill_second",ARGV[1],"curr_permits",ARGV[2],"max_burst",ARGV[3],"rate",ARGV[4])
return result
评论已关闭