Introduction
The full name of HBase is Hadoop Database, which is a distributed, scalable, column-family-oriented database. It is a distributed database solution that uses a large number of inexpensive machines to solve the fast storage and retrieval of massive data. This article will peel off the layers like an onion, peeling away her heart layer by layer.
Features

First, let's take a look at the features of HBase:
•High performance
Based on the LSM tree data structure design, it ensures sequential writes and optimizes read performance through internal optimizations such as bloom filters and compaction, making HBase have high read and write performance.
•High reliability
Before data is written to HBase, it will first write a WAL (Write-Ahead Logging) to prevent the loss of data in memory when the machine fails.
•Easy to expand
The underlying system relies on HDFS, and it can be directly horizontally expanded when the disk space is insufficient.
•Sparsity
Sparsity is an outstanding feature of HBase. In other databases, the handling of null values usually involves filling them, which can cause a lot of space waste, especially for tables with hundreds of millions of columns. If the strategy of filling nulls is used, it is bound to cause a waste of a lot of space. However, for HBase, there is no need to fill nulls for empty values, so sparsity is an important condition for the infinite expansion of HBase's columns.
•Column family storage
Using column family storage allows users to freely choose which columns to place in the same column family.
•Multiple versions
HBase supports the preservation of multiple versions of data, which can be sorted by timestamps. Users can choose the latest version or a specific historical version as needed.
What is column family storage
The previous section mentioned that HBase is stored according toColumn Family StorageTo store data, let's first compare the differences between row storage, column storage, and column family storage.
•Row storage:
Traditional relational databases are stored row-wise, that is, each row of data is stored together.
•Column storage:
Data is stored in columns, meaning that data in each column is stored together. What are the benefits of column storage?
It can save storage space by storing only useful content. Row storage needs to handle null values, while column storage does not require this.
Each column's type is consistent, which can achieve better data compression efficiency when the data falls onto the disk.
3.In most cases, when querying, we do not need to query all the columns of the entire table, but only use some columns. However, because of the row storage method, all fields must be queried first, and then the required fields are filtered out. But column storage is different, it is like eating a buffet, query as needed, and only query what is needed, which can obviously reduce disk IO.
•Column Family Storage:
So what is column family storage? Column storage means that each column is stored separately. For tables with many fields, if too many columns are queried at one time, it will inevitably cause a large amount of disk IO, thus affecting query performance. The meaning of column family storage is that multiple columns can be stored under one column family, and each column family is stored in a file, which can reduce some disk IO and improve query performance.
The data of each column family is stored together, and each column family can freely choose which columns to store. Therefore, column family storage actually gives users the right to choose freely. If all columns are placed in one column family, it is actually equivalent to row storage, where all columns need to be queried each time, while if each column is stored in a separate column family, it is like column storage.
It is not recommended to set too many column families in the current system, as mentioned later. This is because the minimum unit for flush in MemStore is not MemStore itself, but the entire region. Therefore, setting too many column families will consume a lot of energy during flush. However, this architecture provides the most fundamental basis for HBase to evolve into an HTAP (Hybrid Transactional and Analytical Processing) system in the future.
Architecture Principle
The overall architecture of HBase is divided into three parts: ZooKeeper cluster, HMaster, and Region server. The architecture diagram may look quite complex, but the core is the region server. We will gradually uncover its layers from region server -> region -> store -> hfile -> data block.
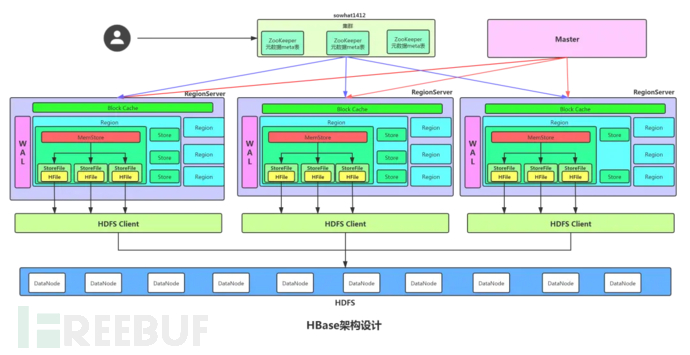
1.Zookeeper
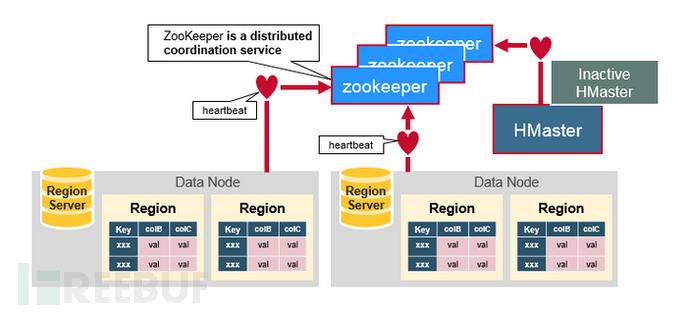
ZooKeeper is a distributed, decentralized metadata storage service used to detect and record the status information of servers in the HBase cluster. The hmaster and region server maintain their relationship by sending heartbeats and communicating with zk at regular intervals.
ZooKeeper stores the hbase:meta table, which maintains all the region information of the entire cluster. The client first accesses zk to query the hbase:meta table information, and caches the hbase:meta table information on the client side to improve query performance.
2.HMaster
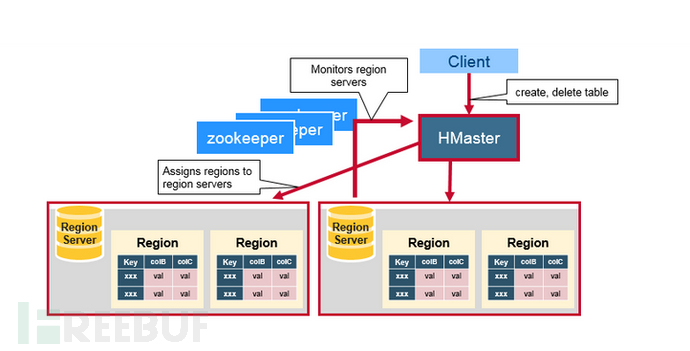
HMaster is a leader role in hbase, which does not participate in the management of specific table data, but is only responsible for macro control. Its main work content includes two aspects: one is to manage Region server, and the other is to execute some high-risk operations, such as executing DDL (table creation, table deletion, etc.).
The function of HBase Master:
• Monitors the status of all RegionServers, and allocates Regions to a certain Region Server when the cluster is in data recovery or dynamic load balancing
• Provides DDL-related APIs, such as creating (create), deleting (delete), and updating (update) table structures
3. Region server
Region server is the most core module in the entire HBase architecture, responsible for actual data read and write. When accessing data, the client communicates directly with the HBase Region server.
HBase tables are divided into multiple Regions according to the regions of Row Key, and each Region contains all the data within this region. The Region server is responsible for managing multiple Regions, responsible for all read and write operations of all regions on this Region server, and a Region server can manage up to 1000 regions.
Each Region server stores its data on HDFS, and if a server is both a Region server and an HDFS Datanode, then the data of this Region server will be stored in the local HDFS, which accelerates access speed.
However, if it is a newly migrated Region server, the data of this region server does not have a local copy. It will not migrate a copy to the local Datanode until HBase runs compaction.
3.1 Architecture diagram of Region server
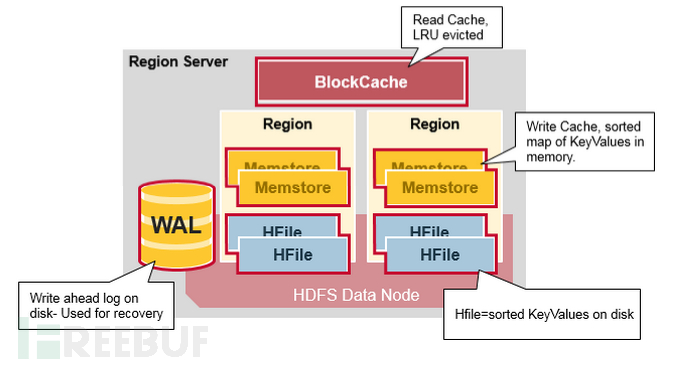
RegionServer is mainly used to respond to user IO requests and is the most core module in HBase, composed of WAL (HLog), BlockCache, and multiple Regions.
3.2 HLog (WAL)
HLog is actually a WAL (Write-Ahead-Log) pre-log, which means that before writing to the memstore, it is first written to HLog to backup the data. HLog is stored on disk, thus ensuring high reliability. HLog is at the level of region server, which means that the entire region server shares one HLog.
HLog has two functions in HBase:
• When a region server crashes, the data that has not been written to disk and is still in memory will not be lost, and it can still be recovered through the HLog logs.
• It is used to implement master-slave replication between HBase clusters, and master-slave replication is achieved by replaying the HLog logs pushed by the master cluster.
The HLog log files are stored in HDFS, and the hbase cluster, by default, will create a hbase folder on hdfs, under which there is a WAL directory, where all related HLog files are stored. HLog does not exist permanently, and the entire HBase HLog will go through the following process:
1. When a write operation occurs, HLog is first constructed.
2. Because HLog is constantly appended, the entire file will become larger and larger, so it is necessary to support rolling log file storage. Therefore, the HBase background process will generate a new HLog file at regular intervals (default one hour), and historical HLog files are marked as historical files.
Once data enters the disk and forms HFile, the data in HLog is no longer necessary because HFile is stored in HDFS, and the HDFS file system guarantees its reliability. Therefore, after all the data in the HLog has been written to disk, the HLog will become invalid, and the corresponding operation is to move the file from WAL to the oldWAL directory. At this time, the file still exists and has not been deleted.
4. hbase has a background process that, by default, checks for invalid log files every minute. If there are no reference operations, the file will be completely deleted physically at this time.
3.3 BlockCache
HBase will cache the data queried from HFile into BlockCache, so that it can be read directly from memory for subsequent operations, reducing disk I/O.
BlockCache is at the region level, and each region has only one BlockCache.
HBase data exists independently only in MemStore and HFile, and the data cached in BlockCache is only part of the hot data in HFile.
3.4 region
Each region is composed of one or more stores, and the region is the basic unit of cluster load balancing and the basic unit for MemStore to flush. The entire region is actually an LSM tree, where memstore corresponds to the C0 tree, stored in memory as write cache, and HFile corresponds to the Cn tree, stored on disk. By ensuring sequential writes, the write performance is greatly improved at the expense of some read performance, and read performance is compensated through internal optimizations such as Bloom filters and compaction, thereby achieving high read and write performance.
3.4.1 store
Each store consists of MemStore and multiple StoreFiles, and the underlying StoreFile is actually HFile. StoreFile is the encapsulation of HFile by hbase. Each column family is stored in a store, so there will be as many stores as there are column families. Too many column families will result in too many MemStores, which will consume too much memory and also cause greater energy consumption during flush.
3.4.1.1 MemStore
MemStore is the write cache of hbase. When write requests are made, after the write to HLog is successful, it is first written to MemStore and sorted by rowkey dictionary order. Only when it reaches a certain threshold will the data be flushed to hdfs to form hfile files. Hbase's MemStore adopts the skip list data structure, which will not be introduced in detail here.
The Role of MemStore:
• Write Cache: Accumulate batch data, write in bulk, reduce disk IO, and improve performance
• Sorting: Maintaining data in alphabetical order according to RowKey
MemStore plays a significant role in both read and write operations, with the largest energy-consuming operation being the flush operation. Below, we will introduce it in detail.
Memstore Flush Trigger Conditions
We know that when the size of MemStore reaches a certain threshold, data will be flushed to HDFS to form hfile files. However, it is important to note that the minimum operation unit for MemStore flush is not MemStore itself, but the entire HRegion. That is to say, if there are too many Memstores in a HRegion, the overhead of each flush will necessarily be large, so each table should not be set with too many column families. Below, we will introduce the specific conditions for triggering flush operations:
1. WhenA certain MemStore in a Regionreacheshbase.hregion.memstore.flush.size(Default value 128MB) will trigger the flush of all MemStores in the Region without blocking write operations.
WhenAll MemStores in a Regionthe total size reacheshbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size(Default value 2 * 128 = 256MB) will trigger the flush of all MemStores in the Region, blocking write operations during this period.
3. Whenwhen a Region is ready to be taken offlinethe total size of MemStorehbase.hregion.preclose.flush.size(Default value 5MB)when, it will trigger the Flush of all MemStore in the Region, and then the Region can be closed.
4. Whenthe total size of all MemStore in a RegionServerthe total size reacheshbase.regionserver.global.memstore.size * HBASE_HEAPSIZE(Default value 0.4 * heap space size)when, it will trigger the Flush of all Regions in the RegionServer starting from the Region with the largest MemStore, and block the write operations of the entire RegionServer until the size of MemStore falls back to the value of the previous parameter.hbase.regionserver.global.memstore.size.lower.limit(Default value 0.95)times, the block will be released.
5. Whenthe WAL in a RegionServer(i.e., HLog)quantity reacheshbase.regionserver.maxlogs(Default value 32)when, HBase will select the earliest WAL corresponding to those Regions for MemStore Flush, and write operations of the corresponding Region will also be blocked during this period.
6. The RegionServer willRegular Flush MemStore,with a period ofhbase.regionserver.optionalcacheflushinterval(Default value 1 hour). To avoid all Regions flushing at the same time, the refresh will have random delays.
7. Users can executeflush [table]orflush [region]commandManual FlushMemStore of a table or a Region.
3.4.1.2 HFile
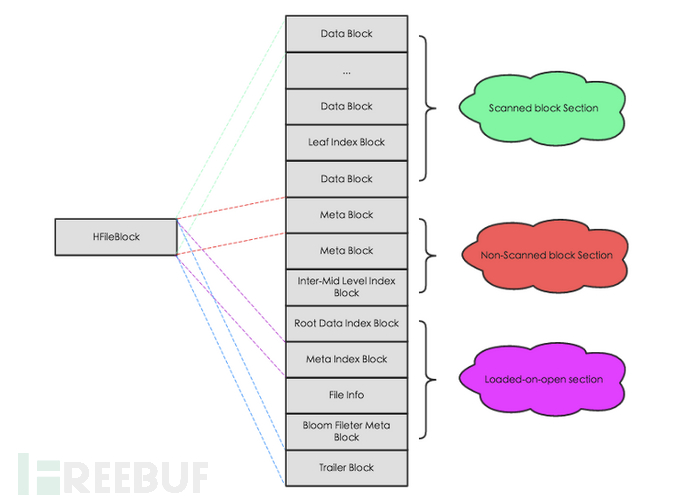
HFile is the file organization form of HBase storing data, which refers to the implementation of SSTable in BigTable and TFile in Hadoop. The following figure is a diagram of the physical structure of HFile, as shown in the figure, HFile will be divided into multiple blocks of equal size, the internal structure of HFile is relatively complex, those who are interested can take a look (http://hbasefly.com/2016/03/25/hbase-hfile/),This article mainly focuses on the storage of actual data in the data block.
3.4.1.2.1 DataBlock
DataBlock is the smallest unit of data storage in HBase. The DataBlock mainly stores the user's KeyValue data (the KeyValue is generally followed by a timestamp, which is not marked in the figure), and the KeyValue structure is the core of HBase storage. Each piece of data is stored in HBase in the form of KeyValue structure. The KeyValue structure on the disk can be represented as:}}
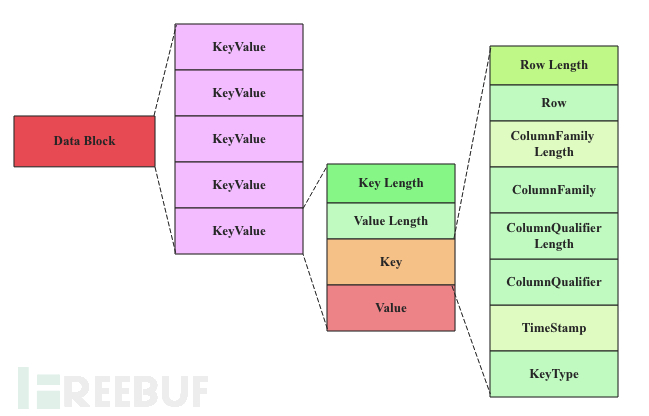
Each KeyValue consists of four parts, namely key length, value length, key, and value. Among them, key length and value length are two fixed-length numbers, while the key is a complex structure. It starts with the length of the rowkey, followed by the rowkey, then the length of the ColumnFamily, then the ColumnFamily, followed by the ColumnQualifier, and finally the timestamp and KeyType (keytype has four types, namely Put, Delete, DeleteColumn, and DeleteFamily). The value is not so complex and is a sequence of pure binary data.
3.4.1.2.2 Basic Concepts
As can be seen from the figure above, some lengths are fixed values, so the key is simplified, and the specific meanings of these contents are focused on. The key consists of RowKey (row key) + ColumnFamily (column family) + Column Qualifier (column qualifier) + TimeStamp (timestamp -- version) + KeyType (type), and the value is the actual value.
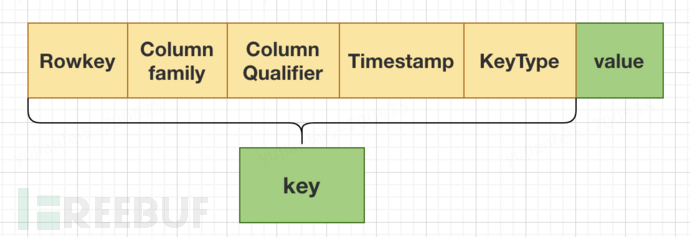
•RowkeyRowkey: The primary key of each row of data, which is the unique query condition in HBase. Therefore, the design of Rowkey is crucial.
•Column familyColumn family: The data of each column family is stored together. Each column family allows users to freely choose which columns to store. All members of the same column family have the same column family prefix. It is common to place columns of the same type under the same column family, but it is important not to set too many column families, which will be discussed later.
•QualifierColumn: It refers to a specific column, prefixed with the column family, in the format of Column family:Qualifier.
•TimestampTimestamp: The timestamp when the cell is inserted, which is used as the version number of the cell by default. Data of different versions are sorted in descending order of timestamp, meaning the latest data is at the front. When data needs to be updated, it is not updated directly like MySQL, but a new record is added. The new data has a larger timestamp and will be placed in front. TTL can be set based on the timestamp, as well as the number of saved versions.
•Type: Data type, used to distinguish whether it is delete data. Delete data and update data will not be directly physically deleted, but a new data record will be inserted, and the type of this data record will be marked as delete. By default, filtering will be performed when querying. Only when executingMajor CompactionData cleaning of delete data will only be performed when an operation is performed.
•Cell: Cell, in HBase, values are stored as units in cells. To locate a unit, it is necessary to meet the five elements of 'rowkey + column family + qualifier + timestamp + KeyType'. Each cell saves multiple versions of the same data. There is no data type in the cell, which is completely byte storage.
4. Read and write process
Before introducing the read and write process, let's first introduce the Meta table. Why introduce it first? Because it is the必经之路 of read and write operations, the guide of rowkey.
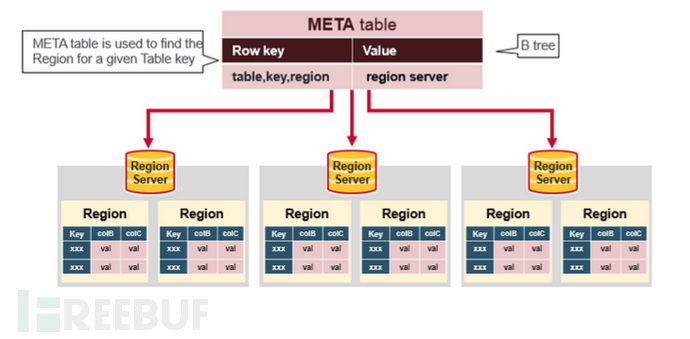
Meta table
The Meta table stores all region information, and the Meta table is stored in zk. When the client accesses for the first time or when a region fails, it will first access zk, obtain the information of the region server according to the rowkey from the Meta table, and then the client will go to access the corresponding region server to perform the corresponding read and write operations.
Write process
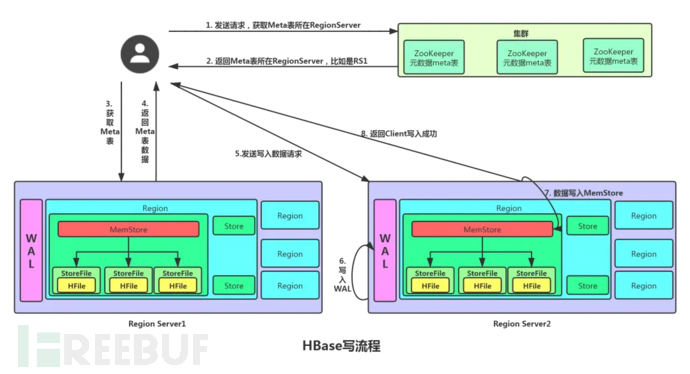
1. The client first accesses zookeeper to obtain the Region Server where the Meta table is located.
2. Access the corresponding Region Server to obtain the Meta table, query the Region Server and Region where the target data is located. And cache the Region information of the table and the location information of the meta table in the client's meta cache for convenient access next time.
3. The client communicates directly with the target Region Server.
4. Write the data in order (append) to HLog (WAL) to prevent data in memory from being lost due to machine failure.
5. Write the data to the corresponding MemStore, and the data will be sorted in the MemStore.
6. Send ack to the client.
7. After reaching the trigger condition of MemStore, flush the data to HFile.
Read process
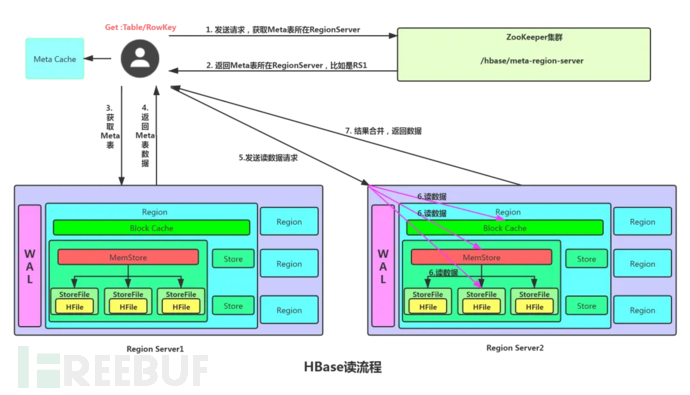
1. The client first accesses zookeeper to obtain the Region Server where the Meta table is located.
2. Access the corresponding Region Server to obtain the Meta table, query the Region Server and Region where the target data is located. And cache the Region information of the table and the location information of the meta table in the client's meta cache for convenient access next time.
3. The client communicates directly with the target Region Server.
4. Read inthe data that has not been written to disk in memoryMemStore andhas already fallen into the diskRead data from the HFile in memory (for HFile data, it is preferred to read from the cached BlockCache in memory, and if the read cache is not found, it will be loaded from the HFile), and merge all the data found. Note that HBase data only exists independently in memory and disk, that is, the data in MemStore and HFile must be full data, while the BlockCache (read cache) is only the part of HFile cached in memory, which is the hot data. The role of BlockCache is to directly read data from memory when reading HFile data, reducing the number of disk I/O operations.
5. Cache the data blocks (Block, HFile data storage unit, default size of 64KB) queried from the file HFile into the Block Cache.
6. Return the merged final result and the latest data to the client.
Read process in detail
Writing operations in HBase are very convenient. Updating data actually just adds a new data record with the latest timestamp, and deleting data is just adding a delete mark. OnlyMajor CompactionPhysical deletion will only occur when this condition is met. Because in HBase, the same rowkey stores multiple versions of data and different keytype data, so the same rowkey will correspond to multiple data records. Therefore, it is not as simple as we think that if the rowkey hits the BlockCache or MemStore, it will be returned directly. It is far from as simple as imagined, and there is no concept of whether to read from BlockCache first or from MemStore first. This statement itself is incorrect.
When reading data, data in both the memory MemStore and the disk HFile need to be read. Two types of Scanners (StoreFileScanner and MemstoreScanner) are created, respectively used to explore the data in HFile and MemStore. Then, some Scanners will be filtered based on the user's selected time range and rowkey range. For the data in HFile, the corresponding Block will be searched first, with priority given to searching from the Blockcache, and if not found, it will be loaded from the HFile. The MemstoreScanner will query data from the Memstore, and finally, the data in memory and disk will be merged to return the latest data to the client. The simplified process is as follows:
1. Construct Scanner
Each StoreScanner will construct a StoreFileScanner for each HFile in the current Store, which is used to actually perform the search of the corresponding file. At the same time, a MemstoreScanner will be constructed for the corresponding Memstore, which is used to perform the data search of the Memstore in the Store.
1. Filter Scanner
Filter the StoreFileScanner and MemstoreScanner according to the Time Range and RowKey Range, and eliminate the Scanner that is definitely not present in the results to be searched.
1.Seek rowkey
All StoreFileScanners start preparing, locating the starting Row that meets the conditions in the responsible HFile. The Seek process (Lazy Seek optimization is omitted here) is also a very core step, which mainly includes the following three steps:
•Locating Block Offset: Read the index tree structure of the HFile in the Blockcache, and retrieve the Block Offset and Block Size corresponding to the RowKey location based on the index tree.
•Load Block: According to the BlockOffset, first search for the Data Block in the BlockCache, and if it is not in the cache, load it from the HFile.
•Seek Key: Locates the specific RowKey within the Data Block through a binary search method.
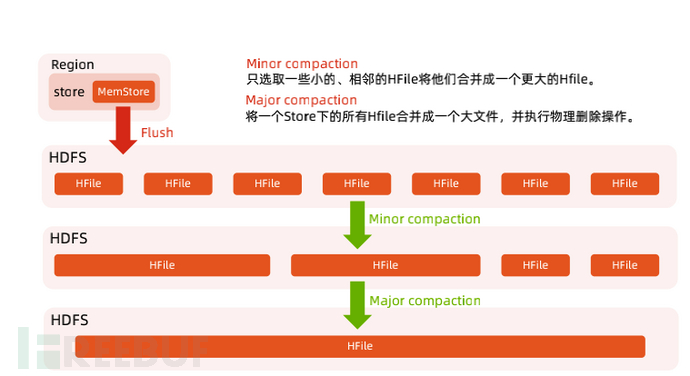
5. HBase Compaction
When the MemStore of HBase reaches the triggering conditions, it will flush the data in the MemStore to HDFS, forming a new HFile file each time. Therefore, with the continuous accumulation of time, the number of HFiles under the same Store will increase, which will reduce the query performance of HBase, mainly reflected in the increase of the number of IO operations for querying data. In order to optimize query performance, HBase will merge small HFiles to reduce the number of files, and this operation of merging HFiles is called Compaction.
•Minor CompactionIt will merge several adjacent HFiles, and during the merging process, it will clean up TTL data, but will not clean up deleted data. Minor Compaction consumes fewer resources, reduces the number of files through a small amount of IO, and improves the performance of read operations, which is suitable for running frequently.
•Major CompactionIt will merge all HFiles under a Store and clean up expired and deleted data, that is, all the data to be deleted will be deleted during Major Compaction. Generally, the time for Major Compaction will be relatively long, and the whole process will consume a large amount of system resources, which has a significant impact on the upper business.Therefore, in the production environment, it is usually recommended to disable the automatic triggering of Major Compaction feature and switch to manual triggering during the off-peak period of business.
Comparison between HBase and traditional relational databases
• Data type:
There are no data types, all are byte arrays (with a utility class Bytes that serializes Java objects into byte arrays), while traditional relational databases have rich data types.
• Data operations:
HBase only has very basic operations such as insertion, query, and deletion, and there is no relationship between tables, while traditional databases generally have many functions, and there are characteristics of association between tables.
• Storage mode:
HBase is based on column family storage, while traditional relational databases are based on row storage.
• Data update:
In HBase, unlike traditional databases, it does not directly modify the record when updating data, but instead inserts a new record with a delete status. The reason for this design is to ensure sequential writing, improve data IO efficiency, and thus improve performance. Old data will not be deleted immediately, but will be deleted during compaction.
• Time version:
When HBase writes data to a cell, it will also attach a timestamp, which is the time of data writing to the RegionServer by default, but it can also specify a different time. Data can have multiple versions, and TTL can be set, as well as the number of retained versions.
• Index: MySQL supports various types of indexes, while HBase only has rowkey
• Scalability
Those who have experienced the sharding and table partitioning of MySQL must have felt its charm, which is very troublesome, but HBase can dynamically expand horizontally, which is very convenient
Design of Rowkey
Access methods
There are only 3 ways to access HBase
1. Access through a single rowkey
2. Access through rowkey range
3. Full table scan
Principles of RowKey design
•Principle of length
RowKey is a binary code stream, which can be any string, with a maximum length of 64kb. In actual applications, it is generally 10-100 bytes, saved in byte[] form, and usually designed to be fixed length. It is recommended to be as short as possible and not exceed 16 bytes.
•Principle of uniqueness
It must be guaranteed that the RowKey is unique in the design. Since data storage in HBase is in Key-Value form, if the same RowKey data is inserted into the same table in HBase, the existing data will be overwritten by the new data.
•Principle of sorting
HBase's RowKey is sorted in ASCII order
•Principle of hashing
RowKey should be evenly distributed across all HBase nodes to prevent hot data from causing data skewing.
Methods to avoid data hotspots
•Reversing
As the name suggests, it means reversing directly. For example, for user id, phone number, etc., if the rowkey has no randomness at the beginning but has good randomness at the end, we can reverse the rowkey directly. Reversing can effectively make the RowKey randomly distributed, but it sacrifices the order of the RowKey. It is beneficial for Get operations but not for Scan operations, because the natural order of the data on the original RowKey has been disrupted.
•Salting
The principle of Salting (adding salt) is to add a fixed-length random number in front of the original RowKey to ensure load balancing of data among all Regions.
•Hashing
Hashing and salting are similar, but hashing requires that the prefix cannot be random and needs to use some hash algorithms, so that the client can reconstruct the rowkey after hashing.
Recommended solution:
In general, you can choose the remainder of the last three digits of the business primary key divided by the HBase partition number as the prefix for salting, and then concatenate the business primary key as the rowkey.
Disadvantages of HBase
•Weak data analysis capability: Data analysis is a weakness of HBase, such as aggregation operations, multi-dimensional complex queries, and multi-table association queries. Therefore, we usually set up components such as Phoenix or Spark on top of HBase to enhance the data analysis and processing capabilities of HBase.
•HBase does not support secondary indexing by default: HBase only does single-column indexing on rowkey, so querying non-rowkey columns is relatively slow under normal circumstances. Therefore, we generally choose a HBase secondary indexing solution, and the currently mature solution is Phoenix. In addition, you can also choose to design and implement your own search engine solutions such as Elasticsearch/Solr.
•Does not support SQL natively: SQL queries are also a weak point of HBase, fortunately, this can be solved by introducing Phoenix, which is a SQL layer designed specifically for HBase.
•HBase does not support global cross-row transactions natively, only supports a single-row transaction model. Similarly, the global transaction model component provided by Phoenix can be used to make up for this deficiency of HBase.
•Fault recovery time is long
Summary of points
1. When designing the table structure, attention must be paid to not setting too many column families, not more than 3, and it is best to have only one.
2. The design of rowkey must pay attention to salting or hash processing to avoid the problem of hot data.
3. Major Compaction is enabled by default and needs to be disabled because it consumes a lot of resources and affects writing, and can be manually executed during the off-peak period of business.
4. The trigger conditions for the flush of MemStore must pay attention to whether all Memstore in the Region Server reach the threshold, because this will affect the entire Region Server's writing.
5. Do not misunderstand BlockCache, the data in HBase, either still in the write cache MemStore that has not been written to disk, or already written to disk data, these two parts must contain all the data, and BlockCache is just the part of HFile cached in memory.
Q&A;
1. It is often said that HBase data reading needs to read Memstore, HFile, and Blockcache, why does the above Scanner only have StoreFileScanner and MemstoreScanner, but not BlockcacheScanner?
Data in HBase exists independently only in Memstore and StoreFile, and the data in Blockcache is only a part of StoreFile (hot data), that is, all the data existing in Blockcache must exist in StoreFile. Therefore, MemstoreScanner and StoreFileScanner can cover all the data. In actual reading, StoreFileScanner locates the block where the key to be searched is located through the index, first checks whether the block exists in Blockcache, if it exists, it is directly taken out, if it does not exist, it reads from the corresponding StoreFile.
2. The data update operation first writes the data to Memstore, and then writes to disk. After writing to disk, is it necessary to update the corresponding kv in Blockcache? If not updated, will dirty data be read?
If the first question is clarified, it is believed that the answer will be easy to obtain: there is no need to update the corresponding kv in Blockcache, and dirty data will not be read. Data writing to Memstore will form a new file, which is independent of the data in Blockcache and exists in a multi-version manner.
References:
https://my.oschina.net/u/4511602/blog/4916109
https://www.jianshu.com/p/f911cb9e42de
https://www.jianshu.com/p/0e178bce8f63
http://hbasefly.com/2016/12/21/hbase-getorscan/
http://hbasefly.com/2017/06/11/hbase-scan-2/
https://zhuanlan.zhihu.com/p/145551967
https://blog.csdn.net/u012151684/article/details/109040581
https://xie.infoq.cn/article/76f8caba743f8be2beb81441d
https://zhuanlan.zhihu.com/p/159052841?utm_id=0
http://hbasefly.com/2016/04/03/hbase_hfile_index/
http://hbasefly.com/2016/03/25/hbase-hfile/
Author: Yu Jianfei, JD Logistics
Source: JD Cloud Developer Community, From the Monkey Say Tech. Please indicate the source when reproduced

评论已关闭