I. Introduction to Chaos Engineering
1. What is Chaos Engineering
Chaos engineering is a system stability guarantee method that uses active fault scenarios to determine optimization strategies based on the behavior of the system under various pressures. Simply put, it is to proactively inject faults, find problems in advance, and then solve problems to avoid risks.
2. Why Conduct Chaos Exercise
With the development of Internet business, the widespread popularity of microservice architecture, distributed architecture, and virtualized container technology, the complexity of software architecture is constantly increasing, and the uncertainty brought by the interdependencies between services is growing exponentially. In such a service call network, any normal or abnormal change in any link may have a butterfly effect on other services. At present, the service volume of the marketing system is increasing, the overall chain growth and data flow complexity are increasing, and the challenges to the availability and stability of the entire system are also increasing. Therefore, chaos exercise is introduced to actively find out the vulnerable links in the system, then strengthen and prevent them in a targeted manner, so as to avoid serious consequences caused by failures and further improve the high availability of business systems and enhance the emergency guarantee ability of business systems.
3. Value of Chaos Exercise

Application of chaos exercise can verify and evaluate the ability of the system to resist disturbances and maintain normal operation, identify unknown risks in advance and fix them, so as to better protect the system from uncontrollable conditions in the production environment and improve overall stability.
II. Chaos Exercise Practice
1. Introduction to Exercise Process
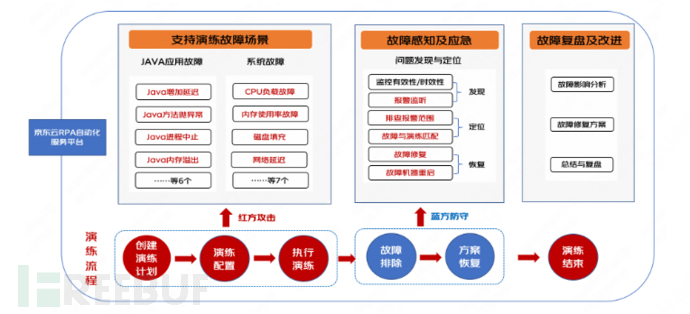
Currently, chaos attack and defense exercises are carried out with the help of the JD Cloud RPA automation service platform. Testers are the Red Team (attackers), and developers are the Blue Team (defenders). The Red Team randomly selects a time period, targets the service system by injecting faults (such as: CPU usage reaches 100%, network latency, JSF interface response delay, etc.), and the Blue Team is responsible for fault perception and emergency response. In this way, the emergency exercise for high availability of the system is achieved.
Red Team:
Create Exercise Plan:By visiting the RPA automation service platform, enter the tool market - exercise type, select different fault plans, and click 'Execute Now';
Exercise Configuration:After clicking execute, enter the configuration page, select the execution environment, select the application to be exercised, and randomly select the instance IP to be exercised;
Execute Exercise:After the exercise task is created, within the corresponding exercise time range, after approval, start executing according to the selected exercise task;
Blue Team:
Fault Investigation:During the exercise, the Blue Team uses alarm information to investigate the simulated fault instance machines first;
Recovery Plan:Problems found during the exercise should be restored in a timely manner. After the exercise, restart and restore the simulated fault instance machines to ensure normal operation of the machines and the recovery of all performance indicators;
2. Initial Practice
2.1 Preparation phase
The preparation phase of chaos engineering exercises is to design exercise strategies, mainly including setting the assessment objectives of the exercise, selecting the exercise scenarios, applications, and machines, generating the corresponding exercise plan, and informing the relevant personnel.
Among them, the most important thing in the preparation phase is to do a good job of risk assessment, according to the level of the system or the maturity of chaos, initially conduct some simple events such as high CPU, high memory, and then gradually increase the resistance of the system, and carry out more advanced events such as network delay, process termination, etc.

2.2 Execution phase
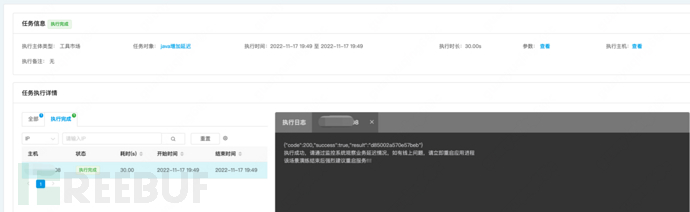
During the exercise scenario execution, execute fault injection, the test personnel should observe the logs and system monitoring, and record the changes in indicators.
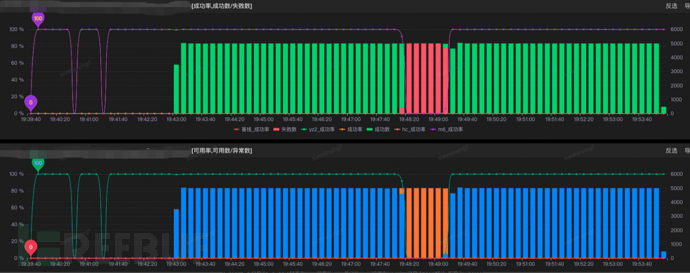
The JSF interface response delay in the execution scenario was 100ms, due to the interface timeout time of 50ms, the failure rate of interface timeout during the fault injection period can be seen as 100% in the monitoring chart;
2.3 Recovery phase
Fault discovery and troubleshooting: during the exercise, the blue team did not know in advance which fault scenarios the exercise would have (currently, through pre-release exercises, the development side can clearly identify the affected machines). The blue team investigates the alarm information received, and the simulation engine system responds and carries out emergency treatment for the alarm information.
The blue team found that the CPU usage rate load fault, the alarm machine was the same as the exercise machine, after restarting the service, the application server responded normally, and the availability was restored;
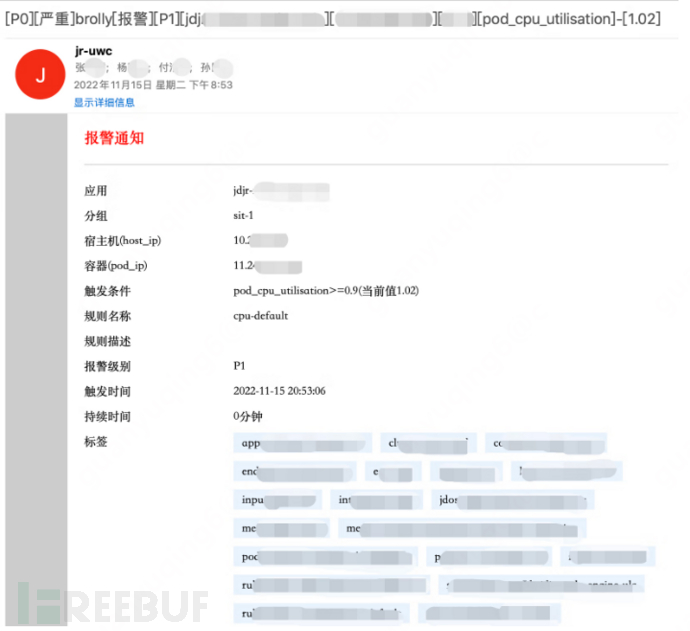
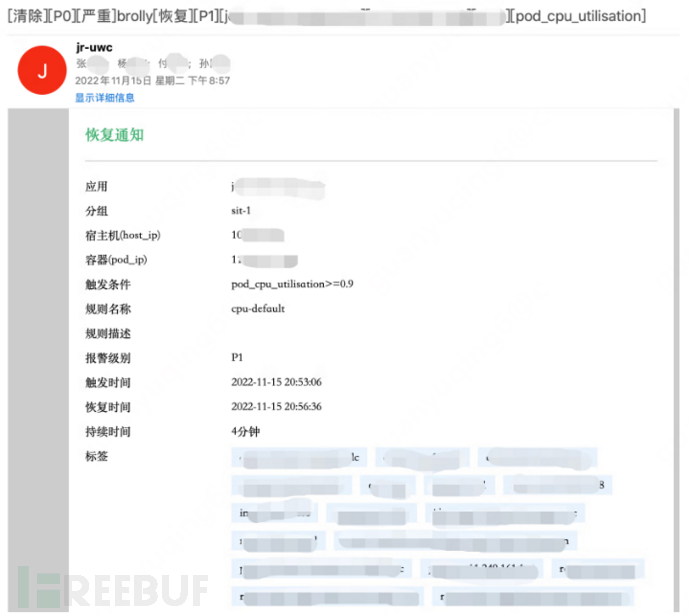
2.4 Review phase
Through this exercise, two points for optimization were found:
1. Exercise scenario of CPU usage load, found that the monitoring alarm email was delayed, and it is recommended to add telephone and Dangdang alarm strategies;
- Simulating the JSF interface response timeout scenario, it was found that there was a lack of failure threshold alarm email, and the corresponding alarm email should be added;
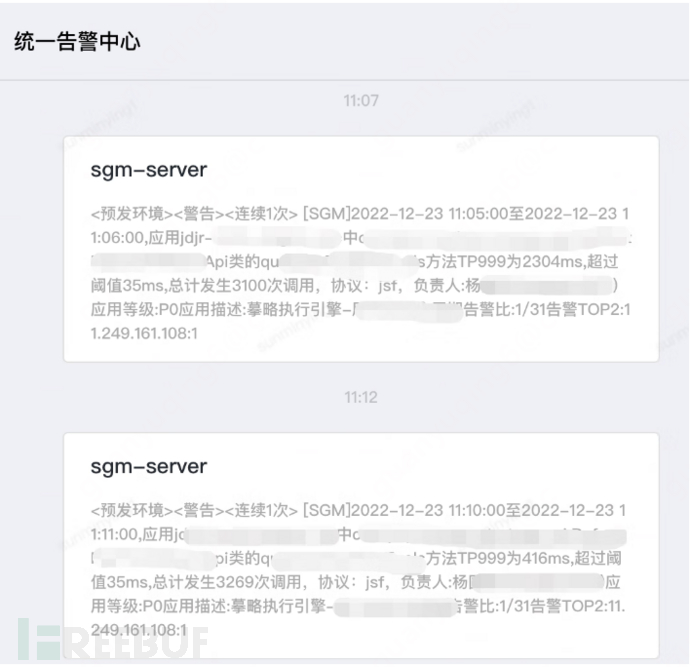
3. Summary of chaos engineering exercises
1. Typical exercise scenarios
With the help of the platform for chaos engineering exercises, the learning cost of the exercises can be reduced, and the efficiency of the exercises can be improved. Currently, the platform supports common exercise scenarios, and everyone can choose the corresponding exercise scenario in the tool market of the platform.
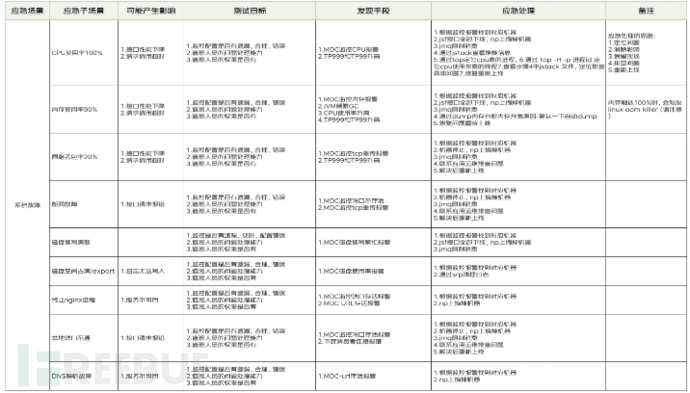
2. Important assessment indicators
After the chaos engineering exercise is completed, it is necessary to record the exercise process and the corresponding changes in monitoring indicators according to the exercise execution process and results. Summarize the existing problems and optimize the exercise report. The main indicators of concern during the exercise are mainly the timeliness indicators of fault discovery, localization, and recovery. The following specifically introduces the key indicators that need to be focused on in the practical exercise, such as whether there is alarm monitoring, the system's fault tolerance, and the response mechanism. The last gray part of the high availability indicators belongs to the exploration part and will change with the current actual situation of the system and different businesses, serving as exploratory indicators.
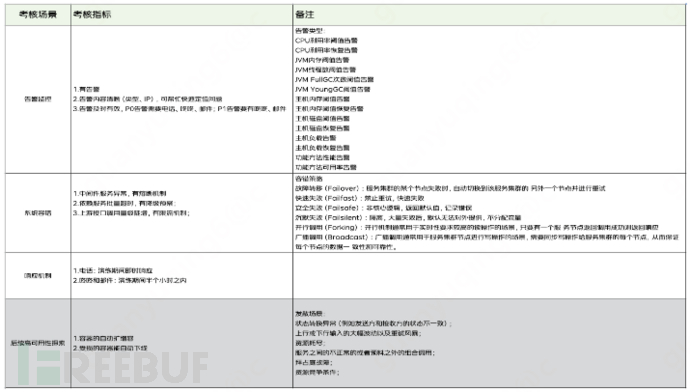
3. Focus on risk control
Chaos engineering exercises can cause destructive effects on business and systems. It is very necessary to do a good job of risk control for chaos engineering to limit the cost of discovering application vulnerabilities, avoid unnecessary damage, and prevent actual losses beyond the reasonable testing allowance. Good risk control keeps the exercise within a smaller scope and avoids larger problems caused by the loss of control over the exercise.
Although the benefits of chaos engineering exercises are evident, it is a practice that should be conducted with caution.
How to conduct offensive and defensive exercise risk assessment for AI systems: Red Teaming Handbook
JAVA Security | In-depth analysis of the underlying mechanism of Runtime.exec command execution
I introduction of black rose Lucy MaaS products
Common methods for reducing costs and increasing efficiency of ElasticSearch
ArchKeeper (Introduction): Issues and concepts of the architecture protection platform

评论已关闭