1 Introduction
Redis is a non-relational K-V database based on memory. Due to its fast read and write response, atomic operations, and a variety of data types such as String, List, Hash, Set, Sorted Set, it is widely used in projects. Today, let's discuss how Redis implements its data structure.
2 Data storage
2.1 RedisDB
Redis stores data in redisDb, with a default of 0~15, a total of 16 db. Each database is an independent space, and there is no need to worry about key collision issues. You can switch db through the select command. Cluster mode uses db0
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
...
}
dict: Database key space, saving all key-value pairs in the database
expires: The expiration time of the key, the dictionary key is the key, and the dictionary value is the expiration event UNIX timestamp
2.2 Implementation of Redis hash table
2.2.1 Hash dictionary dict
K-V storage, the first thing we think of is map, in Redis, it is implemented through dict, the data structure is as follows:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing is not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
}
type: A type-specific function is a pointer to a dictType structure, each of which saves a set of functions used to operate on specific type key-value pairs. Redis sets different type-specific functions for dictionaries with different purposes.
privdata: Private data saves optional parameters that need to be passed to those type-specific functions
ht[2]: An array containing two items, each of which is a dictht hash table. Generally, the dictionary only uses the ht[0] hash table, and the ht[1] hash table is only used when rehashing the ht[0] hash table
rehashidx: rehash index, when rehash is not in progress, the value is -1
Hash data has two characteristics:
Any identical input must always yield the same data
Different inputs may result in the same output
Due to the characteristics of hash data, there is a problem of hash collision. dict can solve this problem through the functions in dictType
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
...
}
hashFunction: The method used to calculate the hash value of the key
keyCompare: The method for comparing the value of the key
2.2.2 Hash table dictht
dict.h/dictht represents a hash table, the specific structure is as follows:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
}
table: Array pointer, each element of the array is a pointer to the dict.h/dictEntry structure, and each dictEntry structure saves a key-value pair.
size: Records the size of the hash table, which is also the size of the table array, and the size is always 2^n
sizemask: Always equals size - 1, this attribute, together with the hash value, determines which index of the table array a key should be placed in.
used: Records the number of nodes (key-value pairs) currently existing in the hash table.
Key-value pair dict.h/dictEntry
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
key: Stores the key of the key-value pair (an SDS type object)
val: Stores the value of the key-value pair, which can be a uint64_t integer, or an int64_t integer, or a pointer to a value wrapped by redisObject
next: Points to the next hash table node, forming a pointer that points to another hash table node, which can connect multiple key-value pairs with the same hash value, thereby solving the problem of key collision (collision)
Using a hash table will inevitably lead to hash collisions. After a hash collision, a linked list is formed at the current array node. When the amount of data exceeds the length of the hash table, a large number of nodes will form a linked list, and in the extreme case, the time complexity will change from O(1) to O(n); if the data in the hash table continues to decrease, it will cause a waste of space. Redis will perform expansion and shrink operations for these two situations based on the load factor:
Load factor: the number of saved nodes in the hash table divided by the size of the hash table, load_factor = ht[0].used/ht[0].size
Expansion operation:
The server is currently not executing the BGSAVE command or the BGREWRITEAOF command, and the load factor of the hash table is greater than or equal to 1;
The server is currently executing the BGSAVE command or the BGREWRITEAOF command, and the load factor of the hash table is greater than or equal to 5;
Shrink operation:
When the load factor of the hash table is less than 0.1, the program will automatically start to perform shrink operations on the hash table.
When Redis expands, if a full expansion is used, it may cause client operations to be unable to be processed in a short time due to the amount of data, so progressive rehash is adopted for expansion, and the steps are as follows:
At the same time, hold two hash tables.
Setting the value of rehashidx to 0 indicates that the rehash work officially begins.
During the rehash process, each time the dictionary is executed for adding, deleting, finding, or updating operations, the program, in addition to executing the specified operation, will also automatically rehash all key-value pairs at the rehashidx index of the ht[0] hash table to ht[1]. After the rehash work is completed, the program will increase the value of the rehashidx attribute by one.
At a certain point in time, all key-value pairs in ht[0] will be rehashed to ht[1], at this time, the program sets the value of the rehashidx attribute to -1, indicating that the rehash operation is completed.
During the progressive rehash, the dictionary's operations such as delete, find, and update are performed on two hash tables; when searching for a key in the dictionary, the program first searches in ht[0], and if it is not found, it continues to search in ht[1]; all newly added key-value pairs to the dictionary are saved in ht[1], and ht[0] no longer performs any addition operations: this measure ensures that the number of key-value pairs contained in ht[0] will only decrease and not increase (if the operation is performed by the event loop for a long time), and it will eventually become an empty table with the execution of rehash operations.
dict.h/redisObject
Typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
}
type:4: constraints on the data type stored during client operations, the type of existing data cannot be modified, 4bit
encoding:4: value encoding mode in Redis, 4bit
lru:LRU_BITS: memory淘汰策略
refcount: manages memory through reference counting, 4byte
ptr: points to the address where the actual storage value is located, 8byte
The complete structure diagram is as follows: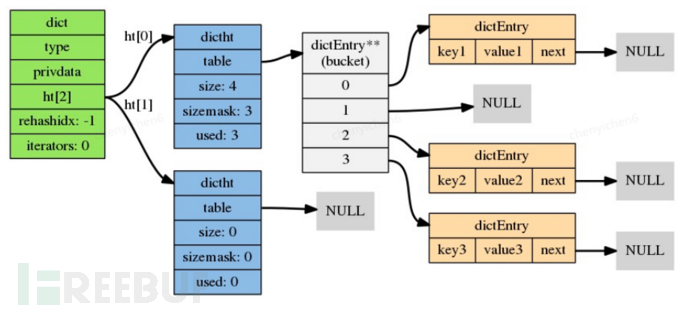
3 String type
3.1 Usage scenarios of String type
There are three types of String: string, integer, and floating-point. The main usage scenarios are as follows
1) Page Dynamic Caching
For example, when generating a dynamic page, the backend data can be generated and stored in a Redis string for the first time. When visiting again, the page is no longer requested from the database, but directly read from Redis. The characteristic is: the first visit is slower, and subsequent visits are faster.
2) Data Caching
In the development of front-end and back-end separation, some data is stored in the database, but changes are very few. For example, there is a national region table. If the back-end reads from the relational database every time the front-end initiates a request, it will affect the overall performance of the website.
We can store all regional information in a Redis string during the first visit, and when the request is made again, directly read the JSON string of the region from the database and return it to the front-end.
3) Data Statistics
Redis integer type can be used to record the number of visits to a website, or the number of downloads for a file (atomic increment and decrement).
4) Limit the number of requests within a certain time period
For example, when a logged-in user requests a SMS verification code, the code is valid for 5 minutes. When a user first requests the SMS interface, the user ID is stored in the Redis string of sent SMS records, and the expiration time is set to 5 minutes. When the user requests the SMS interface again, if there is already a record of the user sending an SMS, the SMS will not be sent again.
5) Distributed session
When using nginx for load balancing, if each backup server stores its own session, then when switching servers, the session information will be lost due to non-sharing, and we have to consider the third-party application to store the session. Through the use of relational databases or non-relational databases such as redis. The storage and read performance of relational databases is far inferior to that of non-relational databases such as redis.
3.2 Implementation of String Type - SDS Structure
Redis does not directly use C strings to implement the String type. Before version 3.2 of Redis, it was implemented through SDS.
Typedef struct sdshdr {
int len;
int free;
char buf[];
};
len: allocated memory space
free: remaining available allocated space
char[]: actual data value
3.3 Differences between SDS and C Strings
3.3.1 Query Time Complexity
The complexity of getting the length of a C string is O(N). While SDS records the length through len, changing from C's O(n) to O(1).
3.3.2 Buffer Overflow
C strings do not record their own length, which is easy to cause buffer overflow (buffer overflow). The space allocation strategy of SDS completely eliminates the possibility of buffer overflow. When modifying an SDS, it will first check if the space of SDS meets the requirements for modification. If it does not meet the requirements, the space of SDS will be expanded to the size required for the modification before executing the actual modification operation, so using SDS does not require manual modification of the space size of SDS, and it will not cause a buffer overflow problem.
In SDS, the length of the buf array is not necessarily one more than the number of characters, and the array can contain unused bytes, and the number of these bytes is recorded by the free attribute of SDS. Through the unused space, SDS implements two optimization strategies: space pre-allocation and lazy space release:
Space pre-allocation: When modifying an SDS and requiring space expansion for the SDS, the program not only allocates the space required for the modification, but also allocates additional unused space. Before expanding the SDS space, it will first check if the unused space is sufficient. If it is sufficient, it will directly use the unused space without executing memory reallocation. If it is not enough, it will expand the capacity according to the formula (len + addlen(new bytes)) * 2. When the size exceeds 1M, it will only increase by 1M each time. Through this pre-allocation strategy, the number of memory reallocations required for SDS to grow N times in a row is reduced from a certain N times to at most N times.
Lazy space release: Lazy space release is used to optimize the string shortening operation of SDS: When the SDS needs to shorten the string stored, the program does not immediately use memory reallocation to reclaim the extra bytes after shortening, but uses the free attribute to record the number of these bytes and wait for future use.
3.3.3 Binary Safety
Characters in C strings must conform to some encoding (such as ASCII, and the string cannot contain null characters except at the end, otherwise the first null character read by the program will be mistakenly considered as the end of the string.
SDS APIs are binary-safe (binary-safe): They will process the data stored in the buf array in a binary manner, and the program will not impose any restrictions, filters, or assumptions on the data - the data is what it is when written, and it is what it is when read. Redis does not use this array to save characters, but to save a series of binary data.
3.4 SDS Structure Optimization

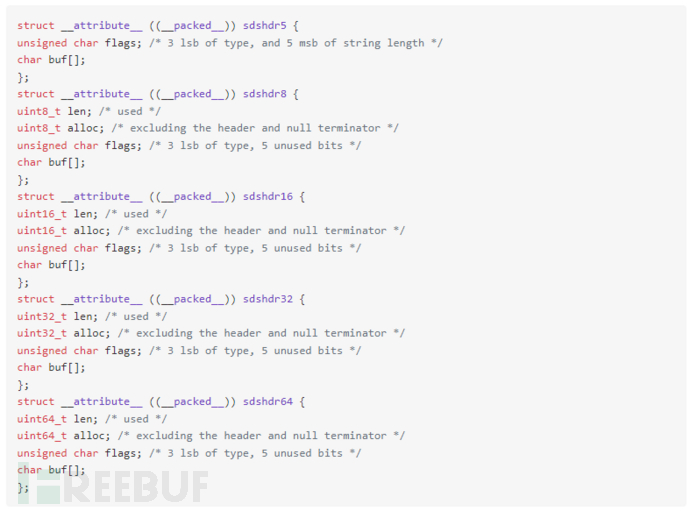
unsign char flags: 3 bits represent the type, and 5 bits represent the unused length
len: Represents the used length
alloc: Represents the allocated space size, and the remaining space size can be obtained using alloc - len
3.5 Character Set Encoding
The redisObject wraps the stored value, optimizes data storage through character set encoding, and there are three encoding methods for string types as follows:
embstr:
The CPU reads data 64 bytes at a time in Cache Line, and a redisObject object is 16 bytes. To fill the 64-byte size, an additional 48 bytes of data will be read after that. However, to get the actual data, it is still necessary to read the data at the corresponding memory address through the *ptr pointer. An sdshdr8 attribute occupies 4 bytes, and the remaining 44 bytes can be used to store data. If the value of value is less than 44 bytes, it can be obtained by reading the cache line once.
int:
If the SDS is less than 20 characters and can be converted to an integer, the redisObject's *ptr pointer will directly store it.
raw:
SDS
4 Summary
Redis, as a key-value data storage, is optimized due to its O(1) time complexity for both search and operation, as well as its rich data types and data structures. Understanding these data types and structures is more beneficial for our daily use of Redis.
In the next issue, we will further introduce the ZipList, QuickList, and SkipList used for other commonly used data types such as List, Hash, Set, and Sorted Set, and welcome everyone to discuss and communicate about any unclear or inaccurate parts in the article.
Author: Sheng Xu

评论已关闭