Preface
Redis, for a Java developer, is actually not a complex or novel technology, but it may also be that few people go deep to understand and learn its underlying things. Below, we will learn about Redis's memory model through four modules: memory statistics, memory partitioning, storage details, object types & internal encoding, learning and practicing with meticulous writing.
1. Redis memory statistics
The info memory command to view memory usage: Basic server information, CPU, memory, persistence, client connection information, etc., as shown in the following figure:
used_memory: Total memory allocated by the Redis allocator + virtual memory (disk)
used_memory_rss: The memory occupied by the Redis process in the operating system + the memory required for the process itself to run + memory fragmentation, etc. (*: Note that used_memory_rss does not include virtual memory)
The difference between them:
① Perspective: used_memory: Redis perspective, used_memory_rss: Operating system perspective
② The size may not always be the latter greater than the former: Memory fragmentation and the memory required for the Redis process to run may make the former smaller than the latter. On the other hand, the existence of virtual memory may make the former larger than the latter
(2) mem_fragmentation_ratio
Memory fragmentation ratio, equal to used_memory_rss / used_memory
mem_fragmentation_ratio > 1 : The higher the value, the greater the memory fragmentation ratio
mem_fragmentation_ratio < 1: indicates that Redis is using virtual memory
*: Since the medium of virtual memory is disk, it is much slower than memory. When this situation occurs, it should be checked in time. If memory is insufficient, it should be handled in time, such as increasing Redis nodes, increasing the memory of Redis servers, optimizing applications, etc.
Under normal circumstances: mem_fragmentation_ratio = about 1.03 (healthy: for jemalloc)
In the above situation: no data has been stored in Redis, and the memory used by the Redis process itself makes used_memory_rss much larger than used_memory
(3) mem_allocator:
The memory allocator used by Redis, specified at compile time, can be libc, jemalloc, or tcmalloc, with jemalloc as the default
(4) used_memory_peak:
Redis memory consumption peak
(5) used_memory_human and used_memory_peak_human:
Literally, returning in a way readable by humans
Part II: Redis memory partitioning
Data: The most important part, which is counted in used_memory. In fact, within Redis, each type may have 2 or more internal encoding implementations. In addition, when Redis stores objects, it does not directly put the data into memory, but wraps the objects in various ways: such as RedisObject, SDS, etc.
Process Memory: The Redis main process itself needs to occupy memory, such as code, constant pools, etc. This part of memory is about a few megabytes and can be ignored compared to the memory used by Redis data in most production environments. This memory is not allocated by jemalloc, so it is not counted in used_memory.
Buffer Memory: Includes client buffers, replication backlog buffers, and AOF buffers
Client Buffer: Stores the input and output buffers of client connections
Replication Backlog Buffer: Used for the partial replication feature
AOF Buffer: Used to save the latest write commands during AOF rewriting
Memory fragmentation: Memory fragmentation is generated by Redis during the allocation and recycling of physical memory.
Part III: Details of Redis data storage
When we execute a Redis command, such as: set hello world, what does the Redis underlying storage do?
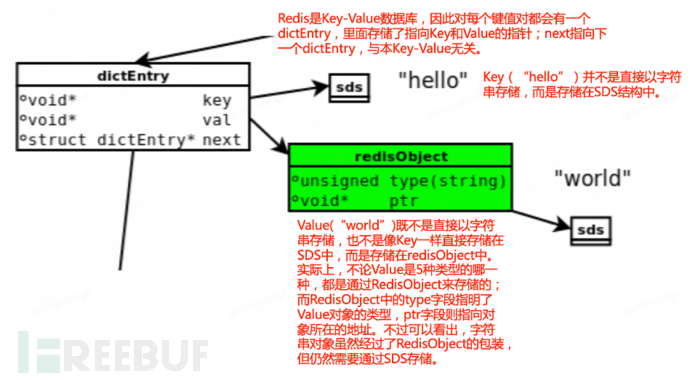
The above involves two concepts: jemalloc and RedisObject
(1) jemalloc
Memory allocator: can be libc, jemalloc, or tcmalloc, with jemalloc as the default
jemalloc memory partition: small, large, huge, each of which is divided into many small memory block units
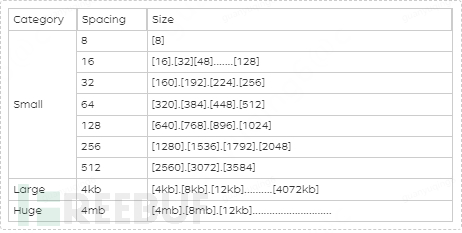
(For example, if an object of 130 bytes needs to be stored, jemalloc will put it into a 160-byte memory unit.)
(2) RedisObject (core data structure)
Redis' five types are all stored through RedisObject, and the type, internal encoding, memory recycling, shared object and other functions of RedisObject need to be supported by RedisObject objects.
typedef struct redisObject{
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
}
type: It represents the data type of the object, occupies 4 bits.
encoding: It represents the internal encoding of the object, occupies 4 bits, and for each data type of redis, there are at least two
Internal encoding. For example, the string type has: int, embstr, raw.
lru: It records the time when the object was last accessed by the command program, and the number of bits occupied is different for different versions (such as 24 bits for version 4.0 and 22 bits for version 2.6).
refcount:
1. Concept: refcount records the number of times the object is referenced, and the type is currently only integer.
2. Function: The main function of refcount is the reference count of objects and memory recycling:
① When a new object is created, refcount is initialized to 1;
② When a new program uses the object, refcount increases by 1;
③ When the object is no longer used by a new program, refcount decreases by 1;
④ When refcount becomes 0, the memory occupied by the object will be released.
3. Why only support string objects with integer values? A balance between memory and CPU (time):
① For integer values, the complexity of the judgment operation is O(1);
② For ordinary strings, the complexity of judgment is O(n);
③ For hash, list, set, and sorted set, the complexity of judgment is O(n^2).
4. The current implementation: When the Redis server initializes, it creates 10,000 string objects with integer values ranging from 0 to 9999; the number 10,000 can be changed by adjusting the value of the parameter REDIS_SHARED_INTEGERS (in version 4.0, it is OBJ_SHARED_INTEGERS). (The reference count of shared objects can be viewed with the object refcount command:)
ptr: The ptr pointer points to specific data, such as in the example set hello world, ptr points to the SDS containing the string world
(3) SDS
1. Concept: Redis does not use C strings (i.e., character arrays ending with a null character ‘\0’) as the default string representation, but uses SDS. SDS is the abbreviation for Simple Dynamic String.
2. Structure:
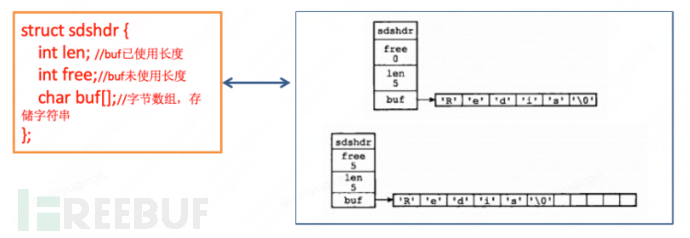
3. Related calculations:
*: The length of buf array = free + len + 1 (where 1 represents the null character at the end of the string)
The space occupied by a SDS structure = the length of free + the length of len + the length of buf array = 4 + 4 + free + len + 1 = free + len + 9.
4. The purpose of adding "\0": So that simple strings can call C string functions
Four, Redis object type & internal encoding
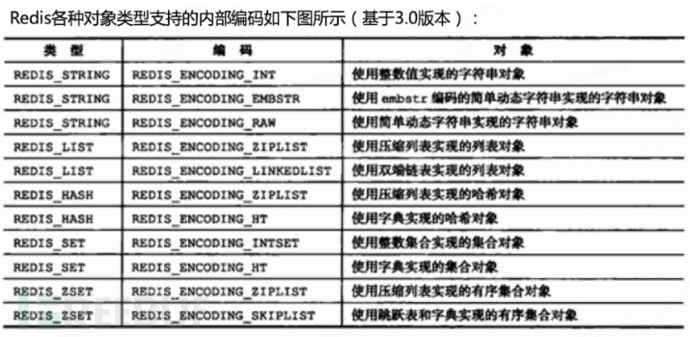
(1) String
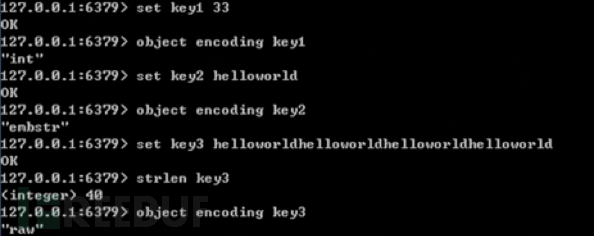
1. String length does not exceed 512MB
2. There are three internal encodings: int, embstr, raw
3. Encoding conversion relationship:
int: Integer
embstr: Strings less than or equal to 39 bytes
raw: Strings longer than 39 bytes
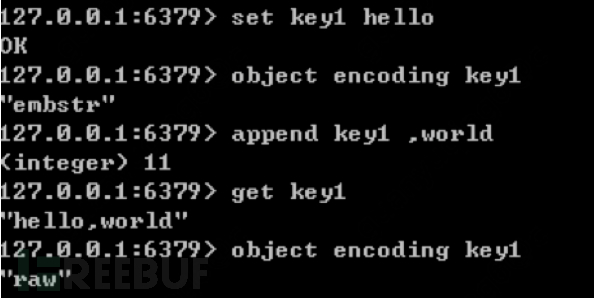
4. Differences between embstr and raw:
①embstr all use redisObject and sds structures for storage
②emstr creates only one memory space allocation (redisObject and sds are allocated together because it is continuous)
Disadvantages: Both creation and deletion require the entire redisObject and sds to be reallocated, so emstr is implemented as read-only.
③raw requires two allocations
5. When emstr is modified, it will first become raw, then modified, regardless of whether it reaches 39 bytes
This is to avoid creating the entire redisObject and sds
(2) List
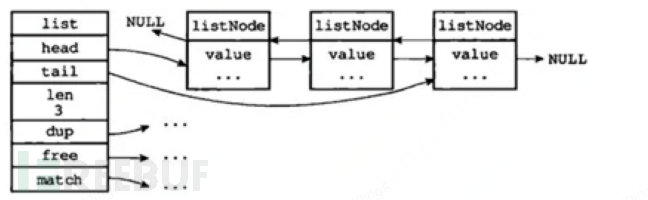
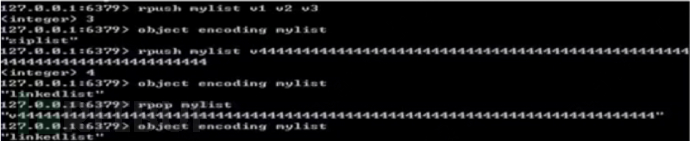
1. Internal encoding: ziplist and linkedlist: (each node points to redisObject)
2. Compressed list: Save space, continuous memory blocks
3. Encoding conversion: In what situations should the compressed list be used?
①List elements < 512
②All string objects in the list are less than 64 bytes (string length)
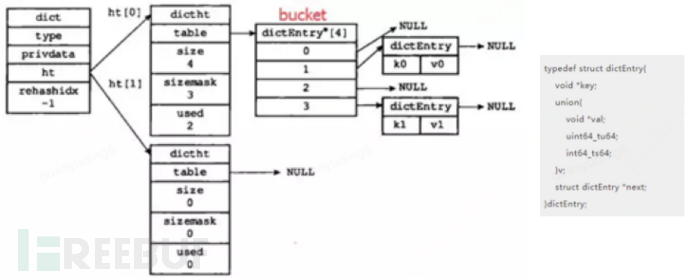
**(3) hash:**Inner hash and outer hash
Inner hash: ziplist, hashtable
Outer hash: hashtable
4.3. List API: Display all objects (object) that a user can access
1.1 Create user objects from the Active Directory Users and Computers console
2.1 Find the location and the root cause of the problem in the code for the large object
2. The related concepts and demands extended from the identified subject

评论已关闭