A simple understanding
Web cache deception: Web cache deception
By exploiting the Web cache deception vulnerability, attackers can deceive Web caches to store sensitive dynamic content through this vulnerability, and the core cause is the difference in the way cache servers and source servers handle requests
Attack process

The following is a diagram provided by portswigger
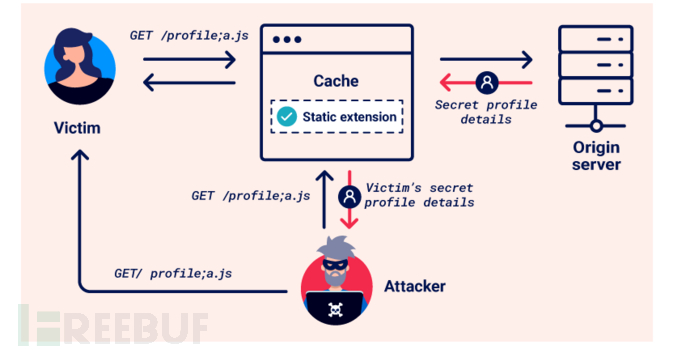
The overall attack process of Web cache deception is roughly as follows
Firstly, the attacker induces the victim to visit the malicious URL, which is also shown in the figure
GET/profile;a.jsAfter successful induction, the victim's browser initiated a fuzzy request to the URL for sensitive content
During the process of parsing the request on the server side, the cache server mistakenly identifies such requests as requests for static resources, and stores the response after processing the request
After that, the attacker can obtain the cached response by requesting the same URL, and the response contains the victim's private information
Web caches
This is also a diagram illustrating the role of web caches servers
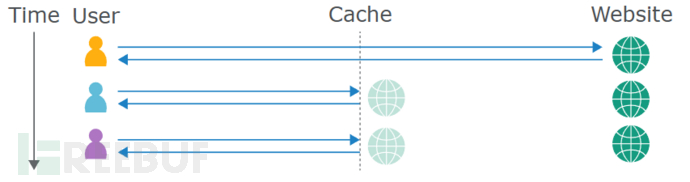
Among them, Web caches are a system between the user and the source server, in order to reduce the pressure on the server, resource requests such as static resources are all designed with caching mechanisms. The general process is:
When the user first accesses the static resources, there is no backup of this resource in the Cache, at this time, the request will be redirected to the source server to process the request and respond
During the response process, the Cache will cache the static resources and respond to the user
When the user accesses the static resources that have been responded to again, there will be no request processing and response from the source server, but the Cache will provide the response directly to the user
Especially, there is a set of pre-configured rules for Cache to determine which type of resources to respond to.
Cache Keys
How does the cache server understand that it has cached resources? One by one matching?
There is a Cache Keys mechanism, the Cache generates so-called Cache Key from some element in the HTTP request to determine whether to respond directly from the Cache when a similar resource request is received next time, or to forward the request to the source server for processing and response.
Generally, such Cache Keys are information such as URL paths, query parameters, etc., of course, they may also be request headers, specific content, etc., for example, the Web cache poisoning vulnerability attack method is to inject malicious content into the cache by controlling the Cache Keys.
Cache rules
As mentioned earlier, whether the resources of the cached response are determined by a series of predefined cache rules
It can determine what content can be cached and how long this content can be cached
Below are some common rules based on the string defined in the request URL path
Static resource extension name rules: This rule matches the file extension of the requested resource, for example
.css / .jsAnd so onStatic directory rules: This rule directly matches all URL paths that start with a specific prefix, for example
/staticAnd/assetsAnd so onFilename rules: This rule matches specific filenames with target files, for example
robots.txtAndfavicon.icoAnd so onOther custom rules
Implement a Web cache poisoning attack
There are roughly the following steps:
Identify the target endpoints that return dynamic responses containing sensitive information. Check the responses in Burp, as some sensitive information may not be visible on the presented page. Focus on endpoints that support GET, HEAD, or OPTIONS methodsBecause requests that change the state of the source server are usually not cached.
Determine that there are differences in the way the cache and source server parse URL paths. This may be a difference in their methods
Differences in the mapping of URLs and resources
Differences in handling delimiters
Normalization differences in URL paths
Create a malicious URL that uses this difference to deceive the cache into storing dynamic responses. When the victim accesses this URL, their response will be stored in the cache. Then, you can use Burp to send a request to the same URL to obtain a cached response containing the victim's data.
Small tool
According to the cache rules mentioned earlier, in most cases, both the URL path and query parameters are included in the Cache Keys. Therefore, to ensure that each request sent has a different Cache Key, which means the request packet has a slight difference, to avoid receiving cached responses during the probe process rather than the source server processing and responding
There is a burpsuit plugin - "Param Miner"
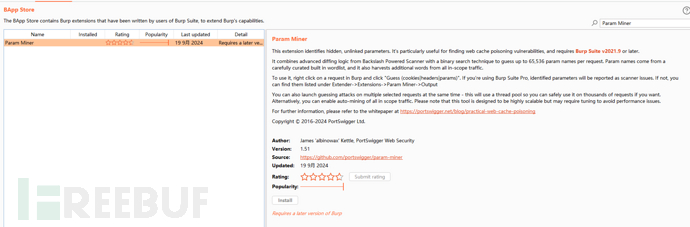
After downloading, check the plugin settingsAdd dynamic cachebuster
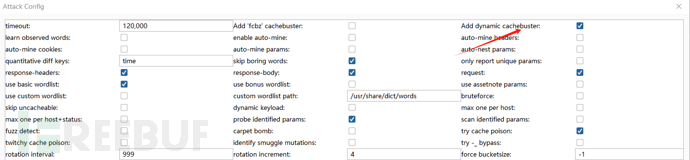
After that, this plugin can automatically add a unique query key for each request, which can be seen in the Logger table

Identify cached responses
By checking the response headers and response time, you can determine and identify whether the response is a cached response. Below are some common headers:
X-CacheHeader: This header provides information on whether the response is provided by the cache server:X-Cache: hitIt indicates that the response is provided by the cacheX-Cache: missThe response does not contain query key, and the request is processed and responded to by the source server.X-Cache: dynamicThe header indicates that the content is dynamically generated by the source server. Usually, such headers are due to the response not being suitable for cachingX-Cache: refreshThe header indicates that the content in the Cache has expired and needs to be refreshed or re-validated
Cache-ControlThe header contains instructions indicating the Cache:
At the same time, it can be judged by the difference in the response time of the agreed request, for the agreed request, if there is a significant difference in the response time, it may indicate that the Cache provides a faster response speed.
Utilizing static extension cache rules
Path mapping differences
URL path mapping is the process of associating URL paths with resources on the server
There are two mapping methods
Traditional method:
http://example.com/path/in/files/resource.html
/path/in/files/It indicates the directory path on the serverresource.htmlIt is a specific filename
RESTful style method:
http://example.com/path/resource/param1/param2
/path/resource/It indicates an endpoint of a resourceparam1 / param2It is a path parameter used for processing by the server
Examples of Web Cache deception caused by mapping differences:
http://example.com/user/123/profile/wcd.css
For a source server that uses RESTful style, it will
/user/123/profileAs an endpoint, and returns the information of user 123, ignoring the subsequent wcd.css as a useless parameterFor a Cache server that uses traditional path mapping, it parses the request as: a named
wcd

评论已关闭