I. What is SQL
sql (Structured Query Language: Structured Query Language) is a high-level procedural programming language that allows users to work on high-level data structures, it is a data query and programming language, and it is also a standard computer language of (ANSI). But... There are still many different versions of SQL language, in order to be compatible with the ANSI standard, they must support some major commands in a similar way together (such as SELECT, UPDATE, DELETE, INSERT, WHERE, etc.).
In standard SQL, SQL statements include four types
DML (Data Manipulation Language): Data manipulation language, used to define database records (data).
DCL (Data Control Language): Data control language, used to define access permissions and security levels.
DQL (Data Query Language): Data query language, used to query records (data).
DDL (Data Definition Language): Data Definition Language, used to define database objects (databases, tables, columns, etc.)
Second, how to execute SQL
2.1 mysql
Taking mysql as an example, the execution process of SQL is roughly divided into the following nodes (mysql server layer code, excluding engine layer transactions/log operations):

mysqlLex: The lexical analysis program of mysql itself, developed in C++, based on the input statements for tokenization, and parsing the meaning of each token. The essence of tokenization is the process of regular expression matching. The source code is in sql/sql_lex.cc
Bision: According to the syntax rules defined by mysql, perform syntax parsing, and the process of syntax parsing is to generate a syntax tree. The core is how to involve appropriate storage structures and related algorithms to store and traverse all information
In the process of syntax parsing, generate the syntax tree:
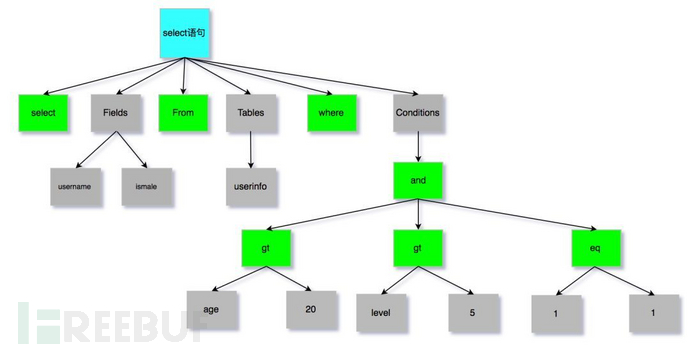
mysql analyzer: SQL parsing, extracts and parses keywords/non-keywords, and generates a parsing syntax tree. If a syntax error is encountered, an exception will be thrown: ERROR: You have an error in your SQL syntax. At this stage, some checks will also be performed, such as throwing an exception if a field does not exist: unknow column in field list.
Derivative point:
a. Syntax tree generation rules
b. Optimization rules of mysql
2.2 hive sql
Hive is a data warehouse analysis system built on Hadoop, which provides rich SQL query methods to analyze data stored in the Hadoop Distributed File System. It can map structured data files to a database table and provide complete SQL query functions. It can convert SQL statements into MapReduce tasks for execution, query and analyze the required content through its own SQL, and this SQL is abbreviated as Hive SQL, making it convenient for users unfamiliar with MapReduce to query, summarize, and analyze data using SQL language
Hive architecture diagram:
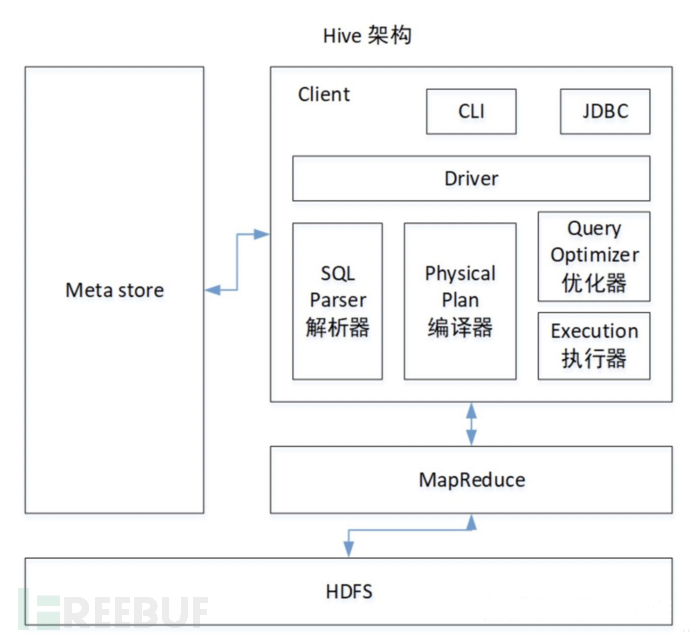
Driver:
After inputting the SQL string, parse the SQL string into an abstract syntax tree, then convert it into a logical plan, and then use optimization tools to optimize the logical plan, finally generating a physical plan (serialization/deserialization, UDF functions), and handing it over to the Execution engine to submit it to MapReduce for execution (input and output can be local or HDFS/Hbase). See the hive architecture in the following figure
The execution process of hiveSql is as follows: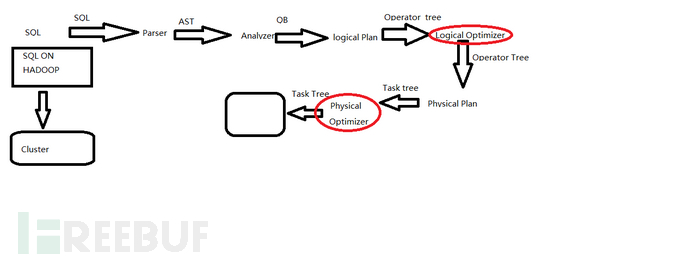
After writing SQL, it is just a concatenation of some strings, so it needs a series of parsing and processing to ultimately become a job that can be executed on the cluster
(1)Parser: Parses SQL into AST (Abstract Syntax Tree), performs syntax verification, and the essence of AST is still a string
(2)Analyzer: Syntax parsing, generates QB (query block)
(3)Logical Plan: Parses the logical execution plan, generates a set of Operator Trees
(4)Logical optimizer: Performs logical execution plan optimization, generates a set of optimized Operator Trees
(5)Physical plan: Parses the physical execution plan, generates tasktree
(6)Physical Optimizer: Performs physical execution plan optimization, generates an optimized tasktree, which is the job executed on the cluster
Conclusion: After the above six steps, a common string SQL is parsed and mapped to an execution task on the cluster. The most important two steps are logical execution plan optimization and physical execution plan optimization (indicated by the red circle in the figure).
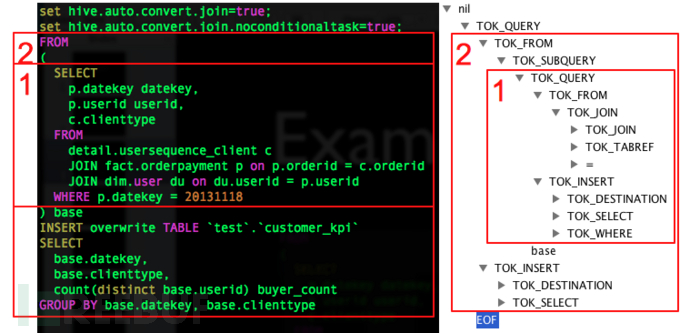
Antlr: Antlr is a language recognition tool, developed based on Java, which can be used to construct domain-specific languages. It provides a framework that allows the construction of language recognizers, compilers, and interpreters through syntax descriptions that include Java, C++, or C# actions (actions). Antlr completes the process of lexical analysis, syntactic analysis, semantic analysis, and intermediate code generation for Hive.
Example of AST Syntax Tree:
Derived learning:
a. From the execution mechanism of HiveSQL, it can be seen that Hive is not suitable for online transaction processing, and cannot provide real-time query functions; it is most suitable for batch processing jobs based on a large amount of immutable data.
b. Antlr Parsing Process
c. Hive Optimization Rules
2.3 Flink SQL
Flink SQL is the highest level of abstraction in Flink and can be divided into SQL --> Table API --> DataStream/DataSet API --> Stateful Stream Processing
Flink SQL includes DML (Data Manipulation Language), DDL (Data Definition Language), and DQL (Data Query Language), but does not include DCL (Data Control Language).
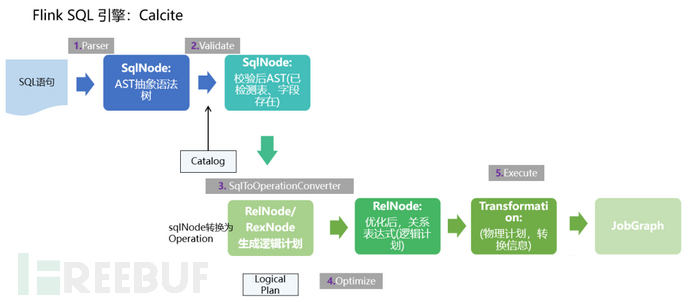
(1) Firstly, FlinkSQL uses the Apache Calcite engine to process SQL statements. Calcite uses javaCC for SQL parsing, and javaCC generates a series of Java code based on the Parser.jj file defined in Calcite, which converts SQL into an Abstract Syntax Tree (AST) of type SQLNode.
(2) The generated SqlNode abstract syntax tree is an unverified abstract syntax tree. At this time, the SQL Validator will obtain metadata information from the Flink Catalog to verify the SQL syntax, including checks on table names, field names, function names, data types, and other metadata information. Then, a verified SqlNode is generated.
(3) At this step, the SQL is only parsed to a fixed node of the Java data structure, without providing the association relationship between related nodes and the type information of each node.
Therefore, it is necessary to convert SqlNode to a logical plan, that is, LogicalPlan. During the conversion process, the SqlToOperationConverter class is used to convert SqlNode to Operation. Operation will execute operations such as creating or deleting tables based on SQL syntax, and at the same time, the FlinkPlannerImpl.rel() method will convert SQLNode to a RelNode tree and return RelRoot.
(4) The Optimize operation is executed, optimizing the logical plan according to the predefined optimization rules RelOptRule.
There are two optimizer RelOptPlanner in Calcite: one is HepPlanner based on rule optimization (RBO), and the other is VolcanoPlanner based on cost optimization (CBO). Then, the optimized RelNode is obtained, and the optimized logical plan is converted into a physical plan based on the rules inside Flink.
(5) The execute operation is performed, which generates a transformation through code, then recursively traverses each node, converting DataStreamRelNode to DataStream. During this period, the translateToPlan method in DataStreamUnion, DataStreamCalc, and DataStreamScan classes is called recursively. The recursive call to each node's translateToPlan actually utilizes CodeGen to generate various operators for Flink, which is equivalent to directly using Flink's DataSet or DataStream to develop programs.
(6) Finally, further compile into an executable JobGraph for submission and execution.
Flink SQL uses Apache Calcite as the parser and optimizer
Calcite : A dynamic data management framework that has many typical database management system functions such as SQL parsing, SQL validation, SQL query optimization, SQL generation, and data connection queries, but also omits some key functions such as Calcite does not store related metadata and basic data, and does not completely contain related data processing algorithms, etc.
Derived learning:
a. Flink SQL optimization rules
3. Common SQL Parsing Engines
| Parsing engine | Development language | Use cases | Summary |
| antlr | java | presto | 1. Contains three major functions: lexer, parser, and tree parser 2. Supports defining domain-specific languages |
| calcite | javaCC | flink | 1. Abstract Syntax Tree 2. Supports using FreeMarker template engine to expand syntax 3. Can create queries with the database |
Continuously supplementing...
4. Summary
In the actual work process, it will involve relevant SQL optimization, such as automatically changing the complex nested SQL written by non-research and development business teachers to non-nested execution in the background, improving query performance. It supports redisSQL, which can parse standard SQL into executable redis commands. Currently, the open-source jsqlparser framework is used to implement syntax tree parsing, which is simple to operate, only splits SQL statements, parses them into a hierarchical structure of Java classes, supports visitor mode, and is database-independent. The disadvantage is that it only supports common SQL syntax sets, and if you want to expand the syntax, you need to modify the source code, which affects the invasiveness and maintainability of the code. To do a good job in SQL parsing optimization, it is necessary to understand the execution principle of SQL and the characteristics and advantages of various SQL engines, and to think about the problem from the perspective of architecture.
If you want to do a good job, you must first sharpen your tools.
Author: JD Technology Li Danfeng
Source: JD Cloud Developer Community. Please indicate the source when转载.

评论已关闭