Recently, some database tables have been added due to the change of requirements, but when defining the table structure, there are some uncertainties about the specific column attribute selection, and there are omissions and irregularities in the addition of indexes. Therefore, I intend to write a special topic in the form of practice to create a high-performance table, in order to learn and consolidate these knowledge.
1. Practical
I use MySQL version 5.7, and the DDL statement for creating the table is as follows: create according to the requirement Interface call logDatabase table, please browse the specific field attribute information, among which there are many points that can be optimized.

CREATE TABLE `service_log` (
`id` bigint(100) NOT NULL AUTO_INCREMENT COMMENT '主键'
`service_type` int(10) DEFAULT NULL COMMENT '接口类型'
`service_name` varchar(30) DEFAULT NULL COMMENT '接口名称'
`service_method` varchar(10) DEFAULT NULL COMMENT '接口方式'
`serial_no` int(10) DEFAULT NULL COMMENT 'Message serial number'
`service_caller` varchar(15) DEFAULT NULL COMMENT 'Caller',
`service_receiver` varchar(15) DEFAULT NULL COMMENT 'Recipient',
`status` int(3) DEFAULT '10' COMMENT 'Status 10-Success 20-Exception',
`error_message` varchar(200) DEFAULT NULL COMMENT 'Exception information',
`message` text DEFAULT NULL COMMENT 'Message content',
`create_user` varchar(50) DEFAULT NULL COMMENT 'Creator',
`create_time` datetime NOT NULL COMMENT 'Creation time',
`update_user` varchar(50) DEFAULT NULL COMMENT 'Updater',
`update_time` datetime NOT NULL COMMENT 'Update time',
`is_delete` tinyint(1) NOT NULL DEFAULT '0' COMMENT 'Deletion flag',
`ts` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Timestamp',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Interface call log';
I will explain the problems contained in it and the places that can be optimized one by one in the following text, mainly referring to the book 'High Performance MySQL, 4th Edition', and also hope that everyone has the energy to read the original book.
2. Optimization and improvement
Generosity is not wise.
Generally, it is advisable to use the smallest data type that can correctly store and represent data. Smaller data types are usually faster because they occupy less disk, memory, and CPU cache space, and require fewer CPU cycles for processing. However, this also ensures that the range of values to be stored is not underestimated, otherwise data loss may occur due to failed entry, and the process of modifying the table structure also requires cumbersome approval procedures.
We take the table as an example: idand By doing this, we save storage space and it also helps with performance.Take the column as an example:
idas the primary key column, it uses the integer type BIGINT (64 bits), in addition to TINYINT (8 bits), SMALLINT (16 bits), MEDIUMINT (24 bits), and INT (32 bits), which can store a value range from -2(N - 1)to 2(N - 1)so the maximum value of the BIGINT type is 9223372036854775808 (19 digits).
It is obviously a bit 'dumb' to define the primary key width as 100 bits, and it is also meaningless: because It does not limit the valid range of values, even if BIGINT(100) is defined, it is not possible to store a number with a width of 100, and in fact, BIGINT(1) and BIGINT(20) are Storage space is the samewhich defines the number of characters displayed by some MySQL interaction tools (MySQL command-line client).
Integer types have an optional UNSIGNED attributewhich means it does not allow negative values, which can approximately double the upper limit of positive integers. For example, TINYINT UNSIGNED can store values ranging from 0 to 255, while the storage range of TINYINT values is -128 to 127. Since our ID column starts from 0 and increments, we can choose this attribute.
Then, we should consider idThe definition of the column is as follows:
`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'Primary Key'
By doing this, we save storage space and it also helps with performance.The column saves the interface interaction message content, and the defined type is TEXT. It also has some related types, as follows (L represents the byte length of the string, and the number represents the number of bytes for the storage byte length of the string):
| Data Type | Storage Required(Bytes) |
|---|---|
| TINYTEXT | L + 1, L < 28 |
| TEXT | L + 2, L < 216 |
| MEDIUMTEXT | L + 3, L < 224 |
| LONGTEXT | L + 4, L < 232 |
If each character in the message content occupies only 1 byte, then the TEXT type can store up to approximately 65535 characters, but the actual message content is far from this length, and the TEXT type is designed as a string data type for storing large amounts of data.
We can adjust it to VARCHAR type and specify its character count as 1000, based on the actual message length not exceeding 1000, to avoid the situation where data cannot be saved due to the message length being too long.通常情况下MySQL会在内容分配固定大小的内存来保存值In most cases, MySQL allocates a fixed-size memory to store values.
By doing this, we save storage space and it also helps with performance.message
The modified definition is as follows:
`message` varchar(1000) DEFAULT NULL COMMENT 'message content'
VARCHAR type also needs an additional 1 or 2 bytes to record the length of the string: if the maximum length of the column is less than or equal to 255 bytes, only 1 byte is used to represent; otherwise, 2 bytes are used.
MySQL defines the length of a string not in bytes but in characters. Character sets like UTF-8 may require multiple bytes to store a single character.
Smaller is usually better
CHAR type is suitable for storing very short strings or strings with almost the same length for all values. However, it should be noted that MySQL will allocate the space defined for CHAR type, so it is fixed length. It performs better than VARCHAR when dealing with frequently modified data because fixed-length columns are less likely to have memory fragmentation, and for CHAR(1) such very short columns, it is more efficient than VARCHAR(1) because the former only occupies 1 byte of space, while the latter occupies 2 bytes (1 byte for the length). Trailing spaces are removed.
service_methodThe field actually stores the interface protocol, which is either HTTP or TCP. We can modify the definition as follows:
`service_method` char(4) DEFAULT NULL COMMENT 'interface method'
However, in reality,Integer data comparison operations are less costly than character dataIf it is allowed to change the field type, we can modify it to TINYINT, and using enumeration values to represent different protocols will be more efficient.
`service_method` tinyint DEFAULT NULL COMMENT 'interface method 1-HTTP 2-TCP'
service_callerand service_receiverThe same principle applies to fields; these values are fixed enumerations, and they should initially be defined as TINYINT as well, as shown below
`service_caller` tinyint DEFAULT NULL COMMENT 'caller',
`service_receiver` tinyint DEFAULT NULL COMMENT 'receiver'
service_typeThe field stores the encoding value of the corresponding interface, and they are all integer data with a width of 4, and the maximum value will not exceed 9999. Therefore, it is more appropriate to modify it to SMALLINT type according to its value range, as follows
`service_type` smallint DEFAULT NULL COMMENT 'Interface Type'
service_nameThe length of the field 'interface name' will not exceed 15 characters, so we modify the VARCHAR definition character length as follows:
`service_name` varchar(15) DEFAULT NULL COMMENT 'Interface Name'
statusThe field only has two values, 10 and 20, which is more suitable than INT to use TINYINT.
`status` tinyint DEFAULT 10 COMMENT 'Status 10-Successful 20-Exception'
DATETIME and TIMESTAMP
These two types are very similar, and for most systems, both types are acceptable, although they also have some differences.
DATETIME can save a larger date range, from 1000 to 9999, with a precision of 1 microsecond. The non-decimal part occupies 5 bytes of storage space, and the decimal part occupies 0 to 3 bytes according to the precision. Moreover, it Time zone independentBy default, MySQL displays time in the format of yyyy-MM-dd HH:mm:ss, and if you need to specify the precision, you can use .datetime(6)
The TIMESTAMP type stores the number of seconds since January 1, 1970, Greenwich Mean Time (with a precision of 1 microsecond), where the non-decimal part occupies 4 bytes of storage space, and the decimal part follows the same space rule as the DATETIME type, so its value range is smaller than that of DATETIME, and it can only represent the time range from January 19, 1970, to January 19, 2038. Moreover, this type is defined in the form specified by the MySQL service. Time zone related, which makes the timestamp be converted to the time in the local time zone before being displayed in the query, so the actual time displayed for the same timestamp in different regions is different.
MySQL can use the FROM_UNIXTIME() function to convert UNIX timestamp to date, and use the UNIX_TIMESTAMP() function to convert date to UNIX timestamp.
It needs to consider the following issues when using DATETIME type or TIMESTAMP type:
Is storage space important to us?
How much time range of dates and times do we need to support?
Does the saved date data have accuracy requirements?
Is it handled in MySQL or in the code?
For our application, the DATETIME type may be more appropriate:
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Update time',
`ts` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'timestamp'
If you want to record timestamps, consider using the BIGINT type, which will not encounter the year 2038 problem.
Avoid using NULL
In most cases, it is better to specify columns as NOT NULL unless it is explicitly needed to store NULL values. Columns that can be NULL require more storage space and special handling in MySQL; Queries containing nullable columns are more difficult to optimize in MySQL because nullable columns make indexing, index statistics, and value comparisons more complex.
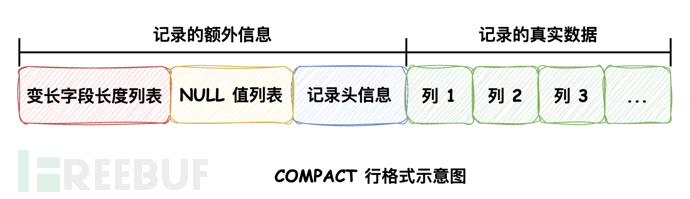
MySQL's default row format is DYNAMIC, which records additional information in each row of data, including the record of NULL value lists. If all columns are NOT NULL, this additional information is not needed.
Understanding: The COMPRESSED row format, different from DYNAMIC, compresses the pages of stored data to save space; The COMPACT row format, different from DYNAMIC and COMPRESSED, stores part of the overflow column data, and the remaining data is stored in other data pages, and records the pointers to the pages where these data are saved. DYNAMIC and COMPRESSED store all the data of the column in other data pages, and only save the address of the corresponding overflow page at the location of the column data.
However, the performance improvement brought by changing the column definition to NOT NULL is not significant, so this optimization will not be the preferred choice. Instead, this point will be considered during the initialization of the table structure.
The final DDL statement for initializing the table structure after modification is as follows:
CREATE TABLE `service_log` (
`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'primary key',
`service_type` smallint NOT NULL DEFAULT -1 COMMENT 'interface type',
`service_name` varchar(30) DEFAULT '' COMMENT 'interface name',
`service_method` tinyint NOT NULL DEFAULT -1 COMMENT 'Interface method 1-HTTP 2-TCP'
`serial_no` int DEFAULT -1 COMMENT 'Message sequence number',
`service_caller` tinyint DEFAULT -1 COMMENT 'Caller',
`service_receiver` tinyint DEFAULT -1 COMMENT 'Recipient',
`status` tinyint DEFAULT 10 COMMENT 'Status 10-Success 20-Exception',
`error_message` varchar(200) DEFAULT '' COMMENT 'Exception information',
`message` varchar(1000) DEFAULT '' COMMENT 'Message content',
`create_user` varchar(50) DEFAULT '' COMMENT 'Creator',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time',
`update_user` varchar(50) DEFAULT '' COMMENT 'Updater',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Update time',
`is_delete` tinyint NOT NULL DEFAULT 0 COMMENT 'Deletion flag',
`ts` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Timestamp',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Interface Call Log';
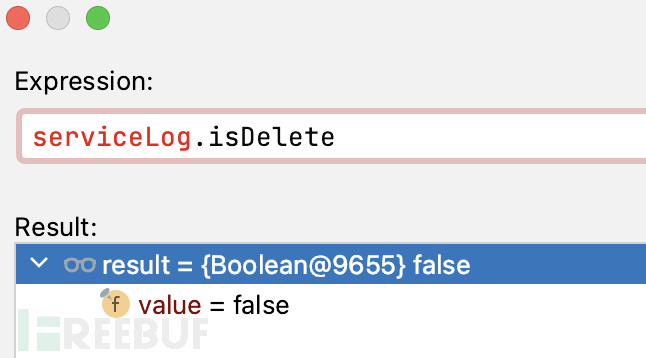
TINYINT represents Boolean type
Note that the Boolean type values in MySQL are mapped by TINYINT. If the value is 0 in the database, it will be mapped to False in the Java object, as shown below:
Real number type
The real number type is not introduced here because it is not used in the table structure, so we will supplement it here.
MySQL supports both precise calculationtypes (DECIMAL), also supports Approximate calculationfloating-point types (FLOAT and DOUBLE).
FLOAT uses 4 bytes of storage space, DOUBLE uses 8 bytes of storage space, you can specify the precision of the column, but it is usually recommended Specify only the data type, not the precisionOtherwise, MySQL will round them based on precision automatically, and they will also be affected by platform or implementation dependencies.
Let's look at the following example:
CREATE TABLE `real_number` (
`f1` float(7, 4) NOT NULL,
`f2` float NOT NULL,
`d1` double(7, 4) NOT NULL,
`d2` double NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Real Numbers';
# Insert data
INSERT into real_number values (
3.1415926535,
3.1415926535,
3.1415926535,
3.1415926535
);
# Query result
select * from real_number;
| f1 | f2 | d1 | d2 |
|---|---|---|---|
| 3.1416 | 3.14159 | 3.1416 | 3.1415926535 |
From the result value, we can find that the floating-point types with specified precision are rounded, the FLOAT types without specified precision default to retaining 5 decimal places after the decimal point, and automatic rounding may cause confusion.
In most cases, we ensure the maximum implementation PortabilityCode that needs to store approximate numerical data values should use FLOAT or DOUBLE, without specifying precision or digits.
There is also a situation that needs attention, if we insert an integer beyond the specified precision range, it will cause the failure of data entry, as follows:
# Specify the integer width of the f1 column as 4, the actual maximum width defined is 3
INSERT into real_number values (
3210.1415926535,
3.1415926535,
3.1415926535,
3.1415926535
);
# Result
SQL error [1264] [22001]: Data truncation: Out of range value for column 'f1' at row 1
If the precision range is not specified, the decimal part will be compressed, the precision will be reduced, rather than prompting the failure of entry, as follows:
# Insert the value into the f2 column and check the result
INSERT into real_number values (
3.1415926535,
3210.1415926535,
3.1415926535,
3.1415926535
);
| f1 | f2 | d1 | d2 |
|---|---|---|---|
| 3.1416 | 3210.14 | 3.1416 | 3.1415926535 |
DECIMAL is different from FLOAT and DOUBLE, and it is used for precise decimal calculations.its precision needs to be specified, otherwise, the default is DECIMAL(10, 0)Only the integer part is saved. And it will occupy more space when storing values in the same range, so for the consideration of additional space requirements and calculation costs, we only use this type when precise calculation of decimals is required.
The maximum number of digits for DECIMAL is 65, and if the number of decimal places specified for the DECIMAL column exceeds the precision range, the value will be rounded to the precision range. Similarly, if the width of the integer part is greater than the specified precision range, an out-of-range exception will occur, resulting in the inability to enter the data normally, as follows:
create table `decimal_t` (
`d1` decimal(7, 4) NOT NULL
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='DECIMAL';
INSERT INTO decimal_t values (3.1415926535);
# The result value is 3.1416
INSERT INTO decimal_t values (1234.1415926535);
# Data truncation: Out of range value for column 'd1' at row 1
In addition, in some large-scale scenarios, consider using BIGINT instead of DECIMAL. Multiply the corresponding multiples according to the number of decimal places during storage. This can avoid the problems of inaccurate floating-point calculations, high cost of precise DECIMAL calculations, and limitations on the range of numerical accuracy at the same time.
Shoulder of the Giant
High Performance MySQL, 4th Edition: Chapter 6
11.1.4 Floating-Point Types (Approximate Value) - FLOAT, DOUBLE
How MySQL Works: Chapter 4
Author: JD Logistics, Wang Yilong
Source: JD Cloud Developer Community, From Monkey to Man. Please indicate the source of reprinting.

评论已关闭