1. Architecture and working principle of Hive
Hive architecture
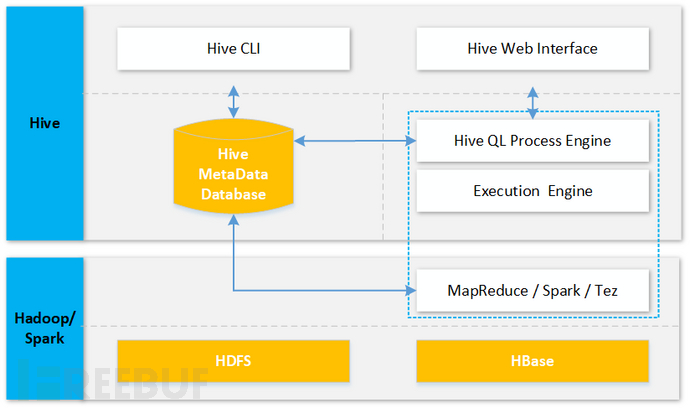
Hive is a data warehouse based on Hadoop, which is convenient for users to perform data analysis based on SQL (Hive QL), and its architecture diagram is as follows:

From the above figure, it can be seen that Hive is mainly used to establish the mapping between structured databases and backend distributed structured files, and to convert SQL statements into MapReduce (currently also supports Spark and other execution engines) tasks for distributed query and analysis.
The specific storage of distributed files and the execution of distributed computations are all undertaken by the backend Hadoop, as shown in the following figure:
2. Hive migration plan
Based on the Hive architecture diagram, when migrating between the new and old Hive clusters, it is necessary to migrate Hive metadata and the file data stored in HDFS/HBase, and adjust the metadata to adapt to the new cluster environment. This article mainly discusses the migration of Hive metadata and HDFS. The description of the two parts of data is as follows:
1. Hive metadata: used to store the mapping relationship between Hive relational database and HDFS;
2. HDFS files: used to save actual data files;
It is necessary to consider the migration plan separately for the above two parts of data.
2.1 Preparation for migration
2.1.1 Network打通
Establish a network connection between the source cluster and the target cluster through a dedicated line or VPN, so that all servers in the source cluster can communicate with all servers in the target cluster, facilitating subsequent data copying.
2.2 Migration steps
2.2.1 Migrating HDFS files first
Since the HDFS data volume is usually large and the migration time is long, it is recommended to migrate the HDFS files first
2.2.2 Migrating Hive metadata again
After the HDFS files are completed with full migration, it is advisable to stop new data writing to the big data cluster. After stopping data writing, you can start migrating Hive metadata and incremental HDFS data (there may be new data writing during the full HDFS migration period, and the business team evaluates based on the data writing situation)
2.3 Migration plan:
2.3.1 Migrating HDFS data
(1) Introduction to migration tools
Use HDFS DistCp to remotely distribute and replicate data to the target new cluster. DistCp is a tool specifically designed for internal and cross-cluster data services in clusters, which uses MapReduce at the bottom to break the data copy into Map tasks for distributed copying. Official documentation for version 2.8.5: https://hadoop.apache.org/docs/r2.8.5/hadoop-distcp/DistCp.html
When HDFS DistCp performs cross-cluster data replication, the main command parameters to be specified and their functions are as follows:
- i Ignore the failed MR tasks during copying, allowing the remote copy to complete successfully. It will also save the logs of the failed copy.
- log <logdir> DistCp will record all copied files in the map output, when the map task fails and is executed again, the file record will not be saved in the log; (the -log parameter does not take effect in the current hadoop 2.8.5 version - tested)
- filters filter out certain files, supporting regular expressions
- update
1) The source and target files have different lengths or contents: the source file overrides the target file;
2) The file does not exist on the target side: copy the source file to the target cluster
-delete deletes files that exist on the target end but not on the source end, and -delete only takes effect when used with –update or –overwrite.
(2) Preparation for migration
1) Stop the write operation of related files in the source and target HDFS.
The prerequisite for using DistCp for data replication is that files in both the source and target HDFS cannot be in a writable state; otherwise, the DistCp copy may fail.
2) This plan assumes that all HDFS data corresponding to Hive is stored in the directory /apps/hive/warehouse/ under HDFS, if Hive involves external tables or files not stored in the /apps/hive/warehouse/ path, please migrate according to the same method.
(3) Full migration
Log in to the Master node and switch to the hadoop user:
su hadoop
Execute remote distributed full data copy:
hadoop distcp -i -log /home/hadoop/logs Source HDFS cluster access domain name or IP:port/apps/hive/warehouse/ Target HDFS cluster access domain name or IP:port/apps/hive/warehouse/
(4) Incremental migration
Log in to the Master node and switch to the hadoop user:
su Hadoop
Execute remote distributed incremental data copy:
hadoop distcp -i -delete -log /home/hadoop/logs -update Source HDFS cluster access domain name or IP:port/apps/hive/warehouse/ Target HDFS cluster access domain name or IP:port/apps/hive/warehouse/
2.3.2 HDFS Data Consistency Verification
After the HDFS data migration, the consistency of the data can be verified at three levels using HDFS:
a. Verify if the number of HDFS data directory and files is consistent
If the number of directories, files, and bytes are all consistent, it can be considered that the HDFS files corresponding to Hive have been migrated and the data is consistent
b. Verify if the HDFS data directory and file list are consistent
If you want to further verify whether all files have been migrated, you can output the list of HDFS data directories and files corresponding to Hive and compare whether they are consistent
c. Verify if the content of the HDFS files is consistent
In some cases, it is necessary to perform consistency checks on the content of individual files. At this time, you can use the HDFS built-in checksum tool for verification. If the checksum of the source and target files is the same, the migration is complete and the data is consistent; otherwise, you need to analyze the cause and perform the migration again.
(1) Verify if the overall HDFS data is consistent
Check if the number of directories, files, and bytes of the source and target HDFS clusters are consistent:
Use the hadoop fs –count command to count the number of directories, files, and bytes. In this scenario, the following command parameters can be used:
-v displays a header line
-x excludes snapshots from the result calculation
The command is: hadoop fs -count -v -x /apps/hive/warehouse
(2) Verify if the HDFS directory and file list are consistent
Check if the directory and file list of the source and target HDFS clusters are consistent:
Use hadoop fs –ls to output the directory and file list, and use the diff tool to compare whether they are consistent. The parameters that can be used with the hadoop fs –ls command in the current scenario are as follows:
-R: Recursively list subdirectories encountered. Recursively subdirectories, list all subdirectories and files
-C: Display the paths of files and directories only. The output does not show columns unrelated to the file list such as time, replication number, etc.
# Official reference document (Hadoop2.8.5): https://hadoop.apache.org/docs/r2.8.5/hadoop-project-dist/hadoop-common/FileSystemShell.html#ls
Execute the following commands separately in the source and target clusters:
Switch to the root user in the source cluster and execute: hadoop fs -ls -R -C /apps/hive/warehouse > srcfilelist
Switch to the root user in the target cluster and execute: hadoop fs -ls -R -C /apps/hive/warehouse > dstfilelist
After obtaining the file and directory list, place them on the same machine and use the diff command to compare them:
The following important parameters related to the diff command that can be used in the current scenario:
-s --report-identical-files Report when two files are the same
--normal Output a normal diff.
# When the source and target cluster file lists are the same
[root@P4anyrQH-Master1 ~]# diff srcfilelist dstfilelist -s --normal
Files srcfilelist and dstfilelist are identical
# When the source and target cluster file lists are different
[root@P4anyrQH-Master1 ~]# diff srcfilelist dstfilelist -s --normal
65,66c65
< /apps/hive/warehouse/user_info_db.db/user_tbl_ext_skewed_list_bucketing/age=34/000000_1
< /apps/hive/warehouse/user_info_db.db/user_tbl_ext_skewed_list_bucketing/age=35
---
> /apps/hive/warehouse/user_info_db.db/user_tbl_ext_skewed_list_bucketing/age=40
In '65,66c65', the c before and after represents the line number of the line where the content of the source file and the target file is different
< Represents the content that is different between the source file and the target file
> Represents the content that is different between the target file and the target file
(3) Verify whether the content of HDFS files is consistent
Compare the content of the source and target HDFS files to see if they are consistent:
Use the checksum command built into HDFS, hadoop fs -checksum, to verify the checksum of a single file
# Official reference document (Hadoop2.8.5): https://hadoop.apache.org/docs/r2.8.5/hadoop-project-dist/hadoop-common/FileSystemShell.html#checksum
For example:
# Check the MD5 value of the source end file
[hadoop@P4anyrQH-Master1 logs]$ hadoop fs -checksum /apps/hive/warehouse/user_info_db.db/user_tbl_ext/000000_0
/apps/hive/warehouse/user_info_db.db/user_tbl_ext/000000_0 MD5-of-0MD5-of-512CRC32C 0000020000000000000000000a59f8a9ab89996e42566969734e21ee
# Check the MD5 value of the target end file
[root@iQotdoaa-Master1 ~]# hadoop fs -checksum /apps/hive/warehouse/user_info_db.db/user_tbl_ext/000000_0
/apps/hive/warehouse/user_info_db.db/user_tbl_ext/000000_0 MD5-of-0MD5-of-512CRC32C 0000020000000000000000000a59f8a9ab89996e42566969734e21ee
#MD5 values are the same
2.4 Hive Metadata Migration Plan
Since Hive metadata stores information related to HDFS paths, the migration of Hive metadata is divided into two parts:
1. Migrate Hive metadata data to the new cluster;
2. Correct the information related to HDFS paths in Hive metadata;
2.4.1 Migrating Hive Metadata
1) Migrate Hive metadata
Hive's metadata is usually stored in MySQL, and there are mainly the following two ways to migrate
(1) Online migration:
The migration scheme of master-slave synchronization solves the full and incremental problems of metadata migration
(2) Offline migration: Use mysqldump for import and export
The brief operation steps for offline migrating MySQL are as follows:
(1) Before using the offline migration, it is necessary to ensure that the source cluster no longer writes metadata. That is, stop the write operations related to the Hive library, table, view, etc.
(2) Export metadata from the source cluster
mysqldump -hlocalhost -uhive -p --databases hive > hive_bk.sql
(3) Import metadata into the target cluster
mysql -hlocalhost -uhive –p
mysql> source hive_bk.sql
2) Verify the consistency of the old and new cluster Hive metadata
Using MySQL's built-in table-level checksum tool, it is recommended to use it between the same versions, and performing checksum on large tables will have a certain impact on the database performance, so it is recommended to use it after testing and evaluation. Here, the JD Cloud team has encapsulated the checksum tool, which can facilitate database-level comparison. The usage instructions are as follows:
# Download checksum tool
wget "https://mysql-documents.s3.cn-north-1.jdcloud-oss.com/checksum_table" -O https://www.freebuf.com/articles/database/checksum_table
Note: This tool needs to be installed on a server and ensure that this server can communicate with both the source and target MySQL
# Authorization
chmod +x checksum_table
# Data verification
# --ws concurrency level
https://www.freebuf.com/articles/database/checksum_table --src-host mysql-xxx.rds.jdcloud.com --src-user 'user-xxx' --src-pass 'password-xxx' --dest-host mysql-xxx.rds.jdcloud.com --dest-user 'user-xxx' --dest-pass 'password-xxx' --ws 30 --database 'dbname-xxx'
eg:
# source checksum: Checksum value of the source table
# dest checksum: Checksum value of the destination table
# result: Checksum result
+--------+-------+-----------------+---------------+--------+
| schema | table | source checksum | dest checksum | result |
+--------+-------+-----------------+---------------+--------+
| dbtest | tb_1 | 1081724441 | 1081724441 | true |
+--------+-------+-----------------+---------------+--------+
If the checksum result of the database table is false, you can use the following method to repair the data:
# Download mysqldump tool
# mysql-5.5
wget "https://mysql-documents.s3.cn-north-1.jdcloud-oss.com/mysqldump55" -O https://www.freebuf.com/articles/database/mysqldump55
# mysql-5.6
wget "https://mysql-documents.s3.cn-north-1.jdcloud-oss.com/mysqldump56" -O https://www.freebuf.com/articles/database/mysqldump56
# mysql-5.7
wget "https://mysql-documents.s3.cn-north-1.jdcloud-oss.com/mysqldump57" -O https://www.freebuf.com/articles/database/mysqldump57
# mysql-8.0
wget "https://mysql-documents.s3.cn-north-1.jdcloud-oss.com/mysqldump80" -O https://www.freebuf.com/articles/database/mysqldump80
# Repair data
https://www.freebuf.com/articles/database/mysqldump57 -hhost -P3306 -uuser -p'' --set-gtid-purged=OFF database table | mysql -hhost -uuser -p'' -D database
2.4.2 Correct the information related to HDFS paths in Hive metadata
1) Tables related to HDFS paths in metadata
After investigation, the metadata information related to HDFS paths is mainly stored in the following metadata tables:
(1) DBS
This table stores the basic information of all databases in Hive, including the storage location of the database
mysql> select * from dbs;
+-------+-----------------------+-------------------------------------------------------------------------------+--------------+------------+------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE |
+-------+-----------------------+-------------------------------------------------------------------------------+--------------+------------+------------+
| 1 | Default Hive database | HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse | default | public | ROLE |
| 6 | NULL | HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse/user_info_db.db | user_info_db | root | USER |
+-------+-----------------------+-------------------------------------------------------------------------------+--------------+------------+------------+
2) rows in set (0.00 sec)
(2) SDS
This table stores the basic information of file storage: including the storage location of table/partition table/clustered table
#Query the storage information of the files, here only showing Location
mysql> select * from SDS;
+------------------------------------------------------------------------------------------------------------------------------------------------+-
| LOCATION |
+------------------------------------------------------------------------------------------------------------------------------------------------+-
| HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse/user_info_db.db/user_tbl_internal |
| HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse/user_info_db.db/user_tbl_ext |
+------------------------------------------------------------------------------------------------------------------------------------------------+-
(3) SKEWED_COL_VALUE_LOC_MAP
This table stores the file paths corresponding to the skewed columns of the table and partition.
#Query the storage path information of the skewed column of the skewed table:
mysql> select * from SKEWED_COL_VALUE_LOC_MAP;
+-------+--------------------+---------------------------------------------------------------------------------------------------------------------+
| SD_ID | STRING_LIST_ID_KID | LOCATION |
+-------+--------------------+---------------------------------------------------------------------------------------------------------------------+
| 38 | 11 | HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse/user_info_db.db/user_tbl_ext_skewed_list_bucketing/age=34 |
| 38 | 12 | HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse/user_info_db.db/user_tbl_ext_skewed_list_bucketing/age=23 |
+-------+--------------------+---------------------------------------------------------------------------------------------------------------------+
(4) SERDE_PARAMS
This table stores some attributes of serialization, and the KV attribute information PARAM_VALUE may involve storage path information, default is none
(5) TABLE_PARAMS
This table stores some attributes of serialization, and the KV attribute information PARAM_VALUE may involve storage path information, default is none
2) Methods for correcting Hive metadata
(1) Metadata correction method one
Manually update the HDFS path-related content in the MySQL table of the metadata database (recommended). The specific operation is to execute the following SQL statement in the MySQL where the Hive metadata database is located:
update SDS set location = (select replace(location, '<old path prefix>', '<new path prefix>')) where location like '%<old path prefix>%';
update DBS set DB_LOCATION_URI = (select replace(DB_LOCATION_URI, '<old path prefix>', '<new path prefix>')) where DB_LOCATION_URI like '%<old path prefix>%';
update SKEWED_COL_VALUE_LOC_MAP set LOCATION = (select replace(LOCATION, '<old path prefix>', '<new path prefix>')) where LOCATION like '%<old path prefix>%';
update SERDE_PARAMS set PARAM_VALUE = (select replace(PARAM_VALUE, '<old path prefix>', '<new path prefix>')) where PARAM_VALUE like '%<old path prefix>%';
update TABLE_PARAMS set PARAM_VALUE = (select replace(PARAM_VALUE, '<old path prefix>', '<new path prefix>')) where PARAM_VALUE like '%<old path prefix>%';
(2) Metadata correction method two
If mysqldump outputs an x.sql file and the file is not large, you can use a text editor to directly batch replace <old path prefix> with <new path prefix>
(3) Third way of metadata correction
Use hive metatool to update HDFS path in metadata
Reference materials: https://cwiki.apache.org/confluence/display/Hive/Hive+MetaTool
hive --service metatool -updateLocation <new-loc> <old-loc>
#This command only updates the HDFS path-related information in the DBS/SDS tables; it lacks the modification of SKEWED_COL_VALUE_LOC_MAP/SERDE_PARAMS/TABLE_PARAMS.
Suitable for scenarios without using skewed table and without HDFS path information in SERDE_PARAMS/TABLE_PARAMS attributes;
2.5 Migration verification
2.5.1 Basic verification
Construct basic query statements for verification, for example:
select * from 表名 limit 100;
You can construct a batch of select statements and store them in sel.sql for batch execution, and write the results to the file result for verification:
hive -f sel.sql > result
2.5.2 Business verification
Select a batch of commonly used Hive statements and store them in test.sql, then execute them in the new and old clusters respectively and output the results to files.
hive -f test.sql > result_src
hive -f test.sql > result_dst
Example of test.sql:
[hadoop@P4anyrQH-Master1 ~]$ cat test.sql
use user_info_db;
select * from user_tbl_ext;
select * from user_tbl_internal;
Use diff to compare whether the execution results of two Hive clusters are the same:
[root@P4anyrQH-Master1 ~]# diff result_src result_dst -s –normal
When files are the same, the output of the diff command is:
Files result_src and result_dst are identical

评论已关闭