Web Crawler
Web Crawler: It is a program or script that automatically captures information from the World Wide Web according to certain rules.
There are many technologies and frameworks related to web crawlers. Different web crawling technologies can be chosen according to different scenarios.
Scrapy Framework (Python)
2.1. Scrapy Architecture
2.1.1. System Architecture
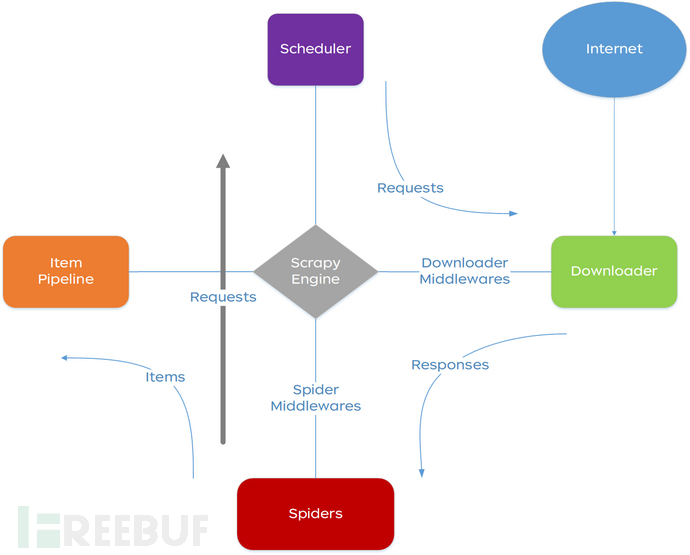
2.1.2. Execution Process
Summarizing the development process of the crawler, the simplified execution process of the crawler is shown in the figure below:
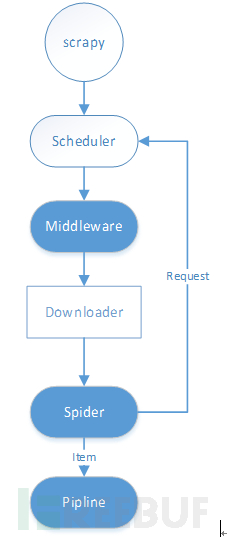
The main running process of the crawler is as follows:
(1) After Scrapy starts the Spider, load the Spider's start_url, and generate the request object;
(2) After middleware optimization, enhance the request object (add IP proxy, User-Agent);
(3) The Downloader object downloads the page according to the request object;
(4) Pass the response result to the parser method of the spider for parsing;
(5) The spider encapsulates the data obtained into an item object and passes it to the pipline, and the parsed request object will return to the scheduler for a new round of data crawling;
2.2. Introduction to core framework files
2.2.1. scrapy.cfg
scrapy.cfg is the entry file of the scrapy framework, the settings node specifies the configuration information of the crawler, and the deploy node is used to specify the deployment path of the scrapyd service.
[settings] default = sfCrawler.settings [deploy] url = http://localhost:6800/ project = jdCrawler |
2.2.2. settings.py
Settings is mainly used to configure crawler start-up information, including: the number of concurrent threads, middleware used, items, etc.; it can also be used as a global configuration file in the system.
Note:Currently mainly added related configuration information such as redis, database connection, etc.
2.2.3. middlewares.py
Middleware defines multiple interfaces, which are called in different situations such as crawler loading, input, output, request, and request exceptions.
Note:Currently mainly used for adding User-Agent information and IP proxy information to the crawler, etc.
2.2.4. pipelines.py
Used to define Pipline objects for data processing, the scrapy framework can configure multiple pipline objects in the settings.py file, and the process of processing data will be executed in the order of priority as configured in settings.py.
Note:Each item object generated in the system will go through all pipeline objects configured in settings.py.
2.2.5. items.py
Used to define data dictionaries of different data types, each attribute is of Field type;
2.2.6. spider directory
Used to store the definition of Spider subclasses, during the start-up process of the scrapy crawler, it will load and call according to the name attribute in the spider class.
2.3. Description of crawler function expansion
2.3.1. user_agents_middleware.py
Through the procces_request method, add header information to the request object, randomly simulating information of various browsers' User-Agent for network requests.
2.3.2. proxy_server.py
Through the procces_request method, add network proxy information to the reques object, randomly simulating multi-IP calls.
2.3.3. db_connetion_pool.py
File location
db_manager/db_connetion_pool.py, the file defines the basic data connection pool, facilitating the operation of the database by various links of the system.
2.3.4. redis_connention_pool.py
File location db_manager/redis_connention_pool.py, the file defines the basic Redis connection pool, facilitating the operation of Redis cache by various links of the system.
2.3.5. scrapy_redis package
The scrapy_redis package is an extension of the scrapy framework, using Redis as the request queue to store spider task information.
spiders.py file: Defines a distributed RedisSpider class, obtaining initial request list information from the Redis cache by overriding the start_requests() method of the Spider class. The RedisSpider subclass needs to assign a value to redis_key.
pipelines.py file: Defines a simple data storage method, which can directly serialize the item object and save it to the Redis cache.
dupefilter.py file: Defines a data deduplication class, using Redis caching to add saved data to the filter queue.
queue.py file: Defines several different queuing and dequeuing orders of queues, using Redis for storage.
2.4. Example of Weibo Spider Development
2.4.1. Finding the Spider Entry
2.4.1.1. Site Analysis
Websites are generally divided into Web端 and M端, with significant differences in design and architecture between the two. In most cases, the Web端 is more mature, with restrictions such as User-Agent check, forced Cookie, and login redirection, making it relatively difficult to crawl, with HTML content as the main return result; the M端 site usually adopts a front-end and back-end separation design, and most provide independent data interfaces. Therefore, it is prioritized to search for the M端 site entry during the site analysis process. The effect of Weibo Web端 and M端 is shown in the figure below:
Weibo Web page address: https://weibo.com/, the page display effect is shown in the figure below:
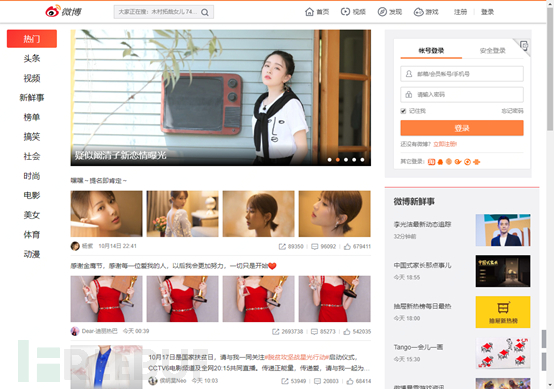
Note: The picture is from the screenshot of the Weibo PC page
Weibo M page address: https://m.weibo.cn/?jumpfrom=weibocom, the page display effect is shown in the figure below:
Note: The picture is from the screenshot of the Weibo M page
2.4.1.2. HTML Source Code Analysis
The return results of both the Web page station and the M page station are in HTML format. Some stations dynamically generate HTML pages through dynamic JavaScript execution and other methods to improve the speed of page rendering or to increase the difficulty of code analysis. Since the web crawler lacks the execution and rendering process of JS, it is difficult to obtain real data. The HTML code snippet of the Weibo Web page station is as follows:

The main content in the script:

HTML content of the M page station:

The HTML content of the M page does not show the key information of the page, which can be determined as a front-end and back-end separation design, and through the Chrome browser development mode, all request information can be viewed. By the type of request and the return results, the interface address can be basically determined, and the search process is shown in the figure below:
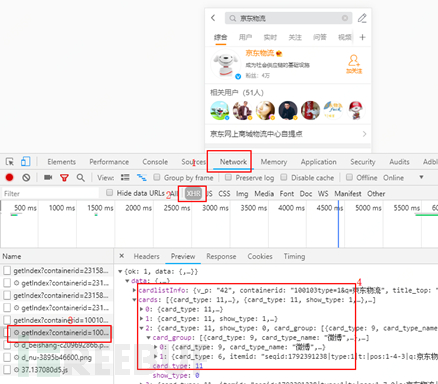
Note: The picture is from the screenshot of the Weibo M page
(1) Open the Chrome Developer Tools, refresh the current page;
(2) Modify the request type to XHR, and filter Ajax requests;
(3) View all request information, ignoring interfaces without return results;
(4) Search for relevant content in the interface return results.
2.4.1.3. Interface Analysis
The interface analysis mainly includes: analysis of request address, request method, parameter list, and return results.
The request address, request method, and parameter list can be obtained from the network request Header information in the Chrome Developer Tools, as shown in the figure below:
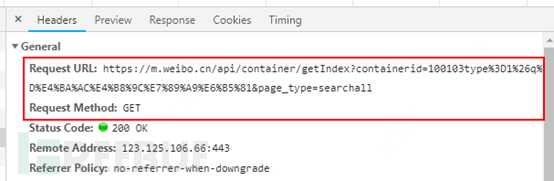
In the figure above, the interface address uses the GET method for the request, the request address is encoded in Unicode, and the parameter content can be viewed in the Query String Parameters list to check the request parameters, as shown in the figure below:

The analysis of the request result mainly focuses on the characteristics of the data structure, searches for data structures identical to the main content, and also checks whether all results are consistent with the main content to avoid special return results affecting the data parsing process.
2.4.1.4. Interface Verification
Interface verification usually requires two steps:
(1) Use a browser (it is best to open a new browser, such as Chrome's incognito mode) to simulate the request process, enter the request address with parameters in the address bar to view the returned results.
(2) Use tools such as Postman to simulate the browser request process, mainly to simulate network requests other than Get methods, and can also verify whether the site forces the use of Cookie and User-Agent information, etc.
2.4.2. Define Data Structure
The definition of the crawler data structure is mainly designed in combination with business requirements and the results of data capture. Microblog data is mainly used by domestic public opinion systems, so in the development process, the data of related sites is defined as the OpinionItem type uniformly. In the process of saving data on different sites, data is assembled according to the characteristics of the OpinionItem data structure. The public opinion data structure is defined as follows in the items.py file:
class OpinionItem(Item):
rid = Field()
pid = Field()
response_content = Field() # All information returned by the interface
published_at = Field() # Publication time
title = Field() # Title
description = Field() # Description
thumbnail_url = Field() # Thumbnail
channel_title = Field() # Channel name
viewCount = Field() # Number of views
repostsCount = Field() # Number of reposts
likeCount = Field() # Number of likes
dislikeCount = Field() # Number of dislikes
commentCount = Field() # Number of comments
linked_url = Field() # Link
updateTime = Field() # Update time
author = Field() # Author
channelId = Field() # Channel ID
mediaType = Field() # Media type
crawl_time = Field() # Capture time
type = Field() # Information type: 1 Main post, 2 Comments of the main post2.4.3. Crawler Development
The microblog crawler uses Distributed RedisSpider as the superclass, and the crawler definition is as follows:
class weibo_list(RedisSpider):
name = 'weibo'
allowed_domains = ['weibo.cn']
redis_key = 'spider:weibo:list:start_urls'
def parse(self, response):
a = json.loads(response.body)
b = a['data']['cards']
for j in range(len(b)):
bb = b[j]
try:
for c in bb['card_group']:
try:
d = c['mblog']
link = 'https://m.weibo.cn/api/comments/show?id={}'.format(d['mid'])
# yield scrapy.Request(url=link, callback=self.parse_detail)
# Content parsing code snippet
opinion['mediaType'] = 'weibo'
opinion['type'] = '1'
opinion['crawl_time'] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
yield opinion
except Exception as e:
print(e)
continue
except Exception as e:
print(e)
continueCode Analysis:
Line 1: Define the weibo_list class, inheriting from the RedisSpider class;
Line 2: Define the crawler name, which is used when the crawler starts;
Line 3: Add the list of allowed access domain names;
Line 4: Define the Redis key for the starting request address of the microblog;
Line 6: Define the parsing method of the crawler, which is called by default after the crawler downloads the page;
Lines 7~21: Parse the downloaded result content and assemble it into the item object;
Line 22: The yield keyword is used to generate a Python-specific generator object, which can be used by the caller to traverse all results.
2.4.4. Data Storage
Data storage is mainly realized by defining a Pipline class, which saves the data parsed by the crawler. Microblog data requires an additional process for sentiment analysis. During the development process, the microblog data is first saved to the Redis service, and then processed and saved to the database through the subsequent sentiment analysis service. The data saving code is as follows:
class ShunfengPipeline(object):
def process_item(self, item, spider):
if isinstance(item, OpinionItem):
try:
print('===========Weibo query results============')
key = 'spider:opinion:data'
dupe = 'spider:opinion:dupefilter'
attr_list = []
for k, v in item.items():
if isinstance(v, str):
v = v.replace(''', '\\'')
attr_list.append("%s:'%s'" % (k, v))
data = ",".join(attr_list)
data = "{%s}" % data
# Use data source, type, and unique ID as duplicate identification
single_key = ''.join([item['mediaType'], item['type'], item['rid']])
if ReidsPool().rconn.execute_command('SADD', dupe, single_key) != 0:
ReidsPool().rconn.execute_command('RPUSH', key, data)
except Exception as e:
print(e)
pass
return itemKey code explanation:
Line 1: Define the Pipline class;
Line 2: Define the process_item method to receive data;
Line 3: Process items according to the Item type separately;
Lines 4~17: Assemble the Item object into a JSON string;
Lines 18~21: Perform duplicate check on the data and save it to the redis queue;
Line 26: Return the item object for other Pipline operations;
After the Pipline definition is completed, it needs to be configured in the settings.py file of the project, as shown below:
# Configuration of item pipelines ITEM_PIPELINES = { "sfCrawler.pipelines.JdcrawlerPipeline": 401, "sfCrawler.pipelines_manage.mysql_pipelines.MySqlPipeline": 402, "sfCrawler.pipelines_manage.shunfeng_pipelines.ShunfengPipeline": 403, } |
Crawler入门地址:
https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
3 WebMagic Framework (Java)
3.1 Preface
Summarize the problems existing in the use of Scrapy, as well as the considerations for the later launch of the crawler system, and adopt Java language for the design and development of crawlers. The specific reasons are as follows:
(1) On-line basic environment dependency: It is necessary to use online basic environments such as Clover, JimDB, MySQL, etc.;
(2) Strong Extensibility: Based on the existing framework, encapsulate the Request request object twice to realize the development of general-purpose network crawlers, providing easily extensible address generation and web parsing interfaces.
(3) Centralized Deployment: By deploying general-purpose crawlers, it captures crawlers for all supported websites, solving the problem of one deployment per site in the Scrapy framework.
(4) Anti-anti-crawling: Some websites implement anti-crawling strategies for the request characteristics of the Scrapy framework (such as Taobao), refusing all crawling requests. WebMagic simulates browser requests and is not subject to the crawling restrictions.
3.2 Overview of WebMagic
(Content Source: https://webmagic.io/docs/zh/posts/ch1-overview/architecture.html)3.2.1 Overall Architecture
The structure of WebMagic is divided into four major components: Downloader, PageProcessor, Scheduler, and Pipeline, which are organized by Spider. These four components correspond to the functions of downloading, processing, managing, and persisting in the lifecycle of a crawler. WebMagic's design refers to Scapy, but the implementation is more Java-oriented.
Spider organizes these components, allowing them to interact with each other and execute in a process-oriented manner. It can be considered that Spider is a large container and it is also the core of WebMagic's logic.
The overall architecture diagram of WebMagic is as follows: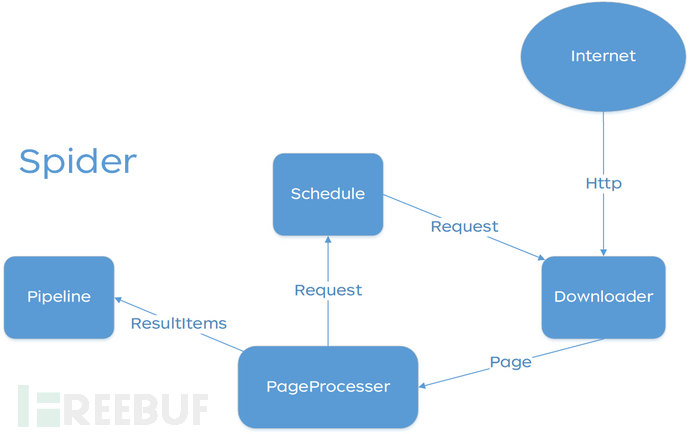
3.1.2 The Four Components of WebMagic
3.1.2.1 Downloader
Downloader is responsible for downloading pages from the internet for subsequent processing. WebMagic uses Apache HttpClient as the default download tool.
3.1.2.2 PageProcessor
PageProcessor is responsible for parsing the page, extracting useful information, and discovering new links. WebMagic uses Jsoup as the HTML parsing tool and has developed Xsoup, a tool for parsing XPath, based on it.
Among these four components, PageProcessor is different for each site and each page, and it is the part that needs to be customized by the user.
3.1.2.3 Scheduler
Scheduler is responsible for managing the URLs to be crawled and some deduplication work. WebMagic provides a JDK memory queue for managing URLs by default, and uses a set for deduplication. It also supports distributed management using Redis.
Unless the project has some special distributed requirements, there is no need to customize Scheduler yourself.
3.1.2.4 Pipeline
Pipeline is responsible for processing the extracted results, including calculation, persistence to files, databases, etc. WebMagic provides two default result processing solutions: 'output to console' and 'save to file'.
Pipeline defines the way to save results. If you want to save to a specified database, you need to write the corresponding Pipeline. For general needs, you usually only need to write one Pipeline.
3.1.3 Objects for data flow
3.1.3.1 Request
Request is a layer of encapsulation for URL addresses, with one Request corresponding to one URL address.
It is the carrier for the interaction between PageProcessor and Downloader, and the only way for PageProcessor to control Downloader.
In addition to the URL itself, it also includes a field with Key-Value structure called extra. You can save some special properties in extra and read them elsewhere to complete different functions. For example, you can add some information about a page.
3.1.3.2 Page
Page represents a page downloaded by the Downloader, which could be HTML, JSON, or other text format content.
Page is the core object in the WebMagic extraction process, providing some methods for extraction and result saving. We will introduce its usage in detail in Chapter 4.
3.1.3.3 ResultItems
ResultItems is equivalent to a Map, which saves the results processed by PageProcessor for use by Pipeline. Its API is very similar to that of Map, and it is worth noting that it has a field called skip. If it is set to true, it should not be processed by Pipeline.
3.1.4 Engine for Controlling Crawler Operation --Spider
Spider is the core of the internal process of WebMagic. Downloader, PageProcessor, Scheduler, and Pipeline are all properties of Spider, which can be freely set. By setting this property, different functions can be realized. Spider is also the entry point for operating WebMagic, encapsulating the creation, start, stop, and multi-threading functions of the crawler. Here is an example of setting up components, multi-threading, and starting. For detailed Spider settings, please refer to Chapter 4 - Configuration, Start, and Termination of the Crawler.
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//Start crawling from https://github.com/code4craft
.addUrl("https://github.com/code4craft")
//Set Scheduler, use Redis to manage the URL queue
.setScheduler(new RedisScheduler("localhost"))
//Set Pipeline, save the results in json format to the file
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//Open 5 threads to execute simultaneously
.thread(5)
//Start the crawler
.run();
}3.3 Analysis and Design of General-purpose Crawler
3.2.1 Analysis of General-purpose Crawler Functionality
(1) Support data crawling from multiple sites simultaneously for a single application;
(2) Support cluster deployment;
(3) Easy to expand;
(4) Support repeated crawling;
(5) Support scheduled crawling;
(6) Have the capability to expand big data analysis;
(7) Reduce the complexity of integrating big data analysis and improve code reusability;
(8) Support online deployment;
3.2.2 Design of General-purpose Crawler
The design idea of the general-purpose crawler is to customize Scheduler, Processor, and Pipeline based on the WebMagic framework, as shown in the following figure:
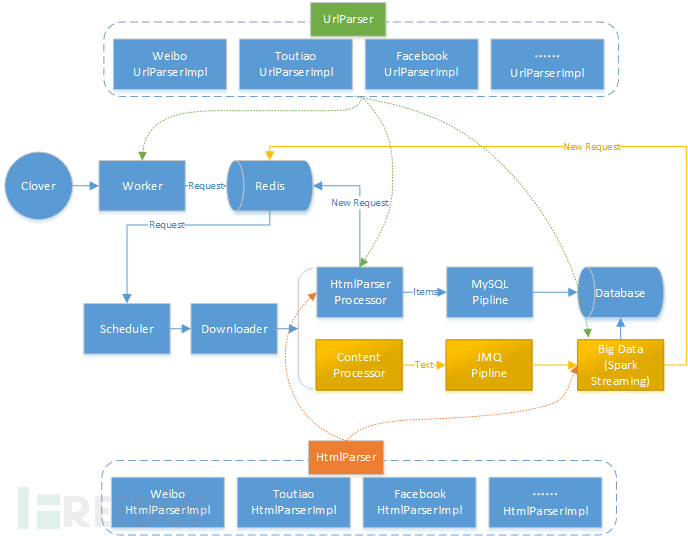
In the design process, according to the characteristics of spider development, the implementation process of the spider is divided into two phases: generating requests and content parsing.
(1) Generating Requests (UrlParser): According to the request address and parameter characteristics of different sites (such as Get/Post request methods, URL parameter concatenation, etc.) and business needs (such as using domestic proxy or foreign proxy), the site parameters are assembled into a universal Request request object to guide Downloader to download web pages.
(2) Content Parsing (HtmlParser): According to the characteristics of parsing web page content, the extraction process of page content is performed through XPATH, JSON, and other methods. Each content parser is only responsible for parsing the same page content, and when the content contains requests for deep page crawling, a new request object is generated by UrlParser and returned to the scheduler.
3.2.3 Task Scheduling Design
In order to achieve the distributed nature of the spider, the Scheduler function is weakened, and the process of adding Clover, Worker, and Redis elements is increased. Clover is responsible for scheduling Worker at regular intervals to generate default request objects (usually for search function, home page repeated crawling tasks, etc.), adding the generated request objects to the Redis queue, and the Scheduler is only responsible for obtaining the request address from the Redis queue.
3.2.4 Processor Design
Processor is used to parse the web page content downloaded by Downloader. In order to make full use of the server network and computing resources, the design initially considers the possibility of splitting the web page download and content parsing to different services for processing, in order to avoid the waste of network bandwidth caused by the excessive CPU time of the crawling node. Therefore, the design process is carried out in two ways: internal parsing of the spider and external platform integration parsing.
(1) Internal Parsing of the Spider: The page parsing process is directly completed by the Processor, generating Items objects and depth Request objects. In order to simplify the parsing process of content from multiple sites, the Processor is mainly responsible for organizing the data structure and calling HtmlParser, and realizing the integration process of multiple site HtmlParsers through the Spring IOC method.
(2) External Platform Integration: Capable of integrating the content crawled by the spider through MQ and other methods, realizing the connection process with other platforms or services. During the implementation process, the crawled web page content can be organized into text type, and the data can be sent to JMQ through the Pipline method, and the connection process with other services and platforms can be realized in accordance with the JMQ method. Other services can reuse HtmlParser and UrlParser to complete the content parsing process.
3.2.5 Pipline design
Pipline is mainly used for data storage, in order to be applicable to the two schemes of Processor, two implementation methods, MySQLPipeline and JMQPipeline, are designed.
3.4 General crawler implementation
3.4.1 Request
The Request class provided by WebMagic can meet the basic needs of network requests, including URL address, request method, Cookies, Headers, and other information. In order to realize general network requests, the existing request objects are extended for business, adding whether to filter, filter token, request header type (PC/APP/WAP), proxy IP country classification, number of failed retries, and other extensions. The extension content is as follows:
/**
* Site
*/
private String site;
/**
* Type
*/
private String type;
/**
* Whether to filter default:TRUE
*/
private Boolean filter = Boolean.TRUE;
/**
* Unique token, used for deduplication of URL addresses
*/
private String token;
/**
* Parser name
*/
private String htmlParserName;
/**
* Whether to fill in Header information
*/
private Integer headerType = HeaderTypeEnums.NONE.getValue();
/**
* Country type, used to distinguish the use of proxy type
* Default is domestic
*/
private Integer nationalType = NationalityEnums.CN.getValue();
/**
* Maximum page crawling depth, used to limit the depth of list page drilling, decreasing in order of access times
* <p>Default: 1</p>
* <p>depth = depth - 1</p>
*/
private Integer depth = 1;
/**
* Number of failed retry times
*/
private Integer failedRetryTimes;3.4.2 UrlParser & HtmlParser
3.4.2.1 Implementation of UrlParser
UrlParser is mainly used to generate fixed request objects according to the parameter list, in order to simplify the development process of Workder, a method for generating initial requests is added to the interface.
/**
* URL address conversion
* @author liwanfeng1
*/
public interface UrlParser {
/**
* Get the list of scheduled task initialization request objects
* @return List of request objects
*/
List<SeparateRequest> getStartRequest();
/**
* Generate Request object according to parameters
* @param params
* @return
*/
SeparateRequest parse(Map<String, Object> params);
}3.4.2.2 HtmlParser Implementation
HtmlParser mainly parses Downloader content and returns the data list and the depth-crawled Request object. Implementation as follows:
/**
* HTML code conversion
* @author liwanfeng1
*/
public interface HtmlParser {
/**
* HTML formatting
* @param html Crawled web page content
* @param request Network request's Request object
* @return Data parsing result
*/
HtmlDataEntity parse(String html, SeparateRequest request);
}
/**
* @author liwanfeng1
* @param <T> Data type
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class HtmlDataEntity<T extends Serializable> {
private List<T> data;
private List<SeparateRequest> requests;
/**
* Add data object
* @param obj Data object
*/
public void addData(T obj){
if(data == null) {
data = new ArrayList<>();
}
data.add(obj);
}
/**
* Add Request object
* @param request Request object
*/
public void addRequest(SeparateRequest request) {
if(requests == null) {
requests = new ArrayList<>();
}
requests.add(request);
}
}3.4.3 Worker
The role of Workder is to generate request objects at regular intervals, combined with the application of the UrlParser interface, designing a unified WorkerTask implementation class, as follows:
/**
*
* @author liwanfeng1
*/
@Slf4j
@Data
public class CommonTask extends AbstractScheduleTaskProcess<SeparateRequest> {
private UrlParser urlParser;
private SpiderQueue spiderQueue;
/**
* Get the task list
* @param taskServerParam Parameter list
* @param i Number
* @return Task list
*/
@Override
protected List<SeparateRequest> selectTasks(TaskServerParam taskServerParam, int i) {
return urlParser.getStartRequest();
}
/**
* Execute the task list, organize Google API request addresses, and add them to the YouTube list crawler queue
* @param list Task list
*/
@Override
protected void executeTasks(List<SeparateRequest> list) {
spiderQueue.push(list);
}
}
Add Worker configuration as follows:
<!-- Facebook start -->
<bean id="facebookTask" class="com.jd.npoms.worker.task.CommonTask">
<property name="urlParser">
<bean class="com.jd.npoms.spider.urlparser.FacebookUrlParser"/>
</property>
<property name="spiderQueue" ref="jimDbQueue"/>
</bean>
<jsf:provider id="facebookTaskProcess"
interface="com.jd.clover.schedule.IScheduleTaskProcess" ref="facebookTask"
server="jsf" alias="woker:facebookTask">
</jsf:provider>
<!-- Facebook end -->3.4.4 Scheduler
Scheduling is mainly used for pushing, pulling the latest tasks, and auxiliary methods such as pushing duplicate verification and queue length acquisition, the interface design is as follows:
/**
* Crawler task queue
* @author liwanfeng
*/
public interface SpiderQueue {
/**
* Add to queue
* @param params Crawler address list
*/
default void push(List<SeparateRequest> params) {
if (params == null || params.isEmpty()) {
return;
}
params.forEach(this::push);
}
/**
* Add SeparaterRequest address to Redis queue
* @param separateRequest SeparaterRequest address
*/
void push(SeparateRequest separateRequest);
/**
* Pop from queue
* @return SeparaterRequest object
*/
Request poll();
/**
* Check if separateRequest is duplicated
* @param separateRequest Encapsulated crawler URL address
* @return Whether duplicated
*/
boolean isDuplicate(SeparateRequest separateRequest);
/**
* Default URL address generation Token<br/>
* It is recommended that different URLParsers generate shorter tokens according to the characteristics of the site address
* Default uses site, type, and URL address for underline separation
* @param separateRequest Encapsulated crawler URL address
*/
default String generalToken(SeparateRequest separateRequest) {
return separateRequest.getSite() + "_"+ separateRequest.getType() + "_" + separateRequest.getUrl();
}
/**
* Get the total length of the queue
* @return Queue length
*/
Long getQueueLength();
}4 Browser calling crawler (Python)
The browser calls the crawler mainly relies on Selenium and ChromeDriver technology, loads and parses the page content through the local browser calling method, and realizes data collection. The main solution of browser calling is to solve the data collection of complex sites, some sites increase the complexity of code analysis through process decomposition, logic encapsulation, code decomposition, code obfuscation and other ways, combined with request splitting, data encryption, client behavior analysis and other ways to carry out anti-crawling operations, so that the crawler program cannot simulate the client request process to initiate requests to the server.
This method is mainly applied to the process of Shunfeng express single number query, order query adopts Tencent sliding verification code plug-in for human-computer verification. The basic process is shown in the figure below:

Firstly, configure the ChromeDriver component to the operating system, component download address:
https://chromedriver.storage.googleapis.com/index.html?path=2.44/, save the file to any path specified under the system environment variable "PATH", recommended: C:\Windows\system32 directory.
Component verification addition: Enable the command line window -> run "ChromeDriver.exe" at any path, the program will run as a service.
The implementation process of the crawler is as follows:
(1) Start the browser: To achieve the concurrency of the crawler, it is necessary to optimize the browser settings through parameters;
Start the browser
def getChromeDriver(index):
options = webdriver.ChromeOptions()
options.add_argument("--incognito") # Incognito mode
options.add_argument("--disable-infobars") # Close the menu bar
options.add_argument("--reset-variation-state") # Reset verification state
options.add_argument("--process-per-tab") # Run each tab page as a separate process
options.add_argument("--disable-plugins") # Disable all plugins
options.add_argument("headless") # Hide the window
proxy = getProxy()
if proxy is not None:
options.add_argument("--proxy-server==http://%s:%s" % (proxy["host"], proxy["port"])) # Add proxy
return webdriver.Chrome(chrome_options=options)(2) Load page: Call the browser to access the specified address page and wait for the page to load completely;
driver.get('http://www.sf-express.com/cn/sc/dynamic_function/waybill/#search/bill-number/' + bill_number)
driver.implicitly_wait(20) # Maximum waiting time of 20 seconds for loading(3) Switch Frame: The captcha is loaded into the current page using the IFrame method, and the next step is to operate on the page elements, so the driver needs to be switched to the iframe;
driver.switch_to.frame("tcaptcha_popup")
driver.implicitly_wait(10) # Wait for the switch to complete, where the iframe loading may have a delay(4) Sliding module: Slide the slider on the page to the specified position to complete the verification process;
The operation process of the sliding captcha is shown in the following figure:

The sliding module's execution distance is within 240 pixels, the entire sliding process takes 14 samples, simulates the parabolic execution process to control the sliding speed, divides this sliding process into 20 moves (to avoid the same sampling results each time), as shown in the following figure:

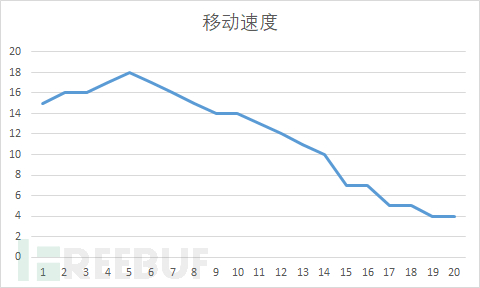
The code is as follows:
# Randomly generate the slider drag trajectory
def randomMouseTrace():
trace = MouseTrace()
trace.x = [20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 9, 9, 8, 8, 7, 7, 6, 6, 5, 5]
trace.y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
trace.time = [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]
return trace
# Drag the slider
def dragBar(driver, action):
dragger = driver.find_element_by_id("tcaptcha_drag_button")
action.click_and_hold(dragger).perform() # Hold down the left mouse button without releasing
action.reset_actions()
trace = randomMouseTrace()
for index in range(trace.length()):
action.move_by_offset(trace.x[index], trace.y[index]).perform() # Move a displacement
action.reset_actions()
time.sleep(trace.time[index]) # Wait for the pause time
action.release().perform() # Release the left mouse button
action.reset_actions()
return driver.find_element_by_id("tcaptcha_note").text == ""(4) Data parsing and storage: The data parsing process is mainly to locate elements by id or class to obtain text content, and insert the results into the database to complete the data crawling process.
(5) Other: Use Python's threading for multi-threaded calls, save the order number to Redis to implement the distributed task acquisition process, and pick up an order number each time it is executed.
待改进:
(1) The module sliding speed and time are fixed, and random optimization can be performed;
(2) Unrecognized slider release position, currently using the slider update method to retry, with a certain error rate;
(3) If the proxy IP is not switched, the browser startup needs to be optimized to reduce the number of startups and improve the crawling speed;
5 gocolly framework (Go)
Concurrency execution with multiple threads is one of the advantages of the Go language. The Go language achieves concurrency operations through 'goroutines', and when a goroutine encounters I/O blocking, a dedicated goroutine will manage the blocking task, which reduces the dependency on server resources and improves the crawling efficiency.
(Content transferred from: https://www.jianshu.com/p/23d4ecb8428f)
5.1 Overview
gocolly is a network crawling framework implemented in go, gocolly is fast and elegant, and can initiate more than 1K requests per second on a single-core; it provides a set of interfaces in the form of callback functions to implement any type of crawler; it depends on the goquery library and can select web elements like jQuery.
The official website of gocolly is http://go-colly.org/, which provides detailed documentation and example code.
5.2 Installation and Configuration
Installation
go get -u github.com/gocolly/colly/Import package
import "github.com/gocolly/colly"5.3 Process Description
5.3.1 Usage Process
The usage process mainly explains the preparation work before using colly to scrape data
- Initialize the Collector object, which is the global handle of colly
- Set global settings, mainly setting the proxy settings of the colly handle
- Register scraping callback functions, mainly used to extract data and initiate other operations in various data processing processes after scraping data
- Set auxiliary tools, such as the storage queue for scraping links, data cleaning queue, etc.
- Register scraping links
- Start the program to begin scraping
5.3.2 Scraping Process
Each node in the data scraping process will try to trigger the user registered scraping callback function to complete data extraction and other needs, and the scraping process is as follows.
- It will be called before preparing to scrape data according to the link each time, registering the OnRequestPreprocessing work before each scraping
- It will be called when scraping data failsOnErrorError handling
- It will be called after the data is scrapedOnResponse, to handle the data just scraped
- Then the analysis of the scraped data will trigger according to the dom nodes on the pageOnHTMLCallback for data analysis
- It will be called after the data analysis is completed OnScrapedFunctions perform cleanup work after each scraping
5.4. Auxiliary Interfaces
colly also provides some auxiliary interfaces to assist in the data scraping and analysis process. The following lists some of the main supported ones.
- queue is used to store links waiting to be scraped
- proxy is used to initiate scraping from an agent
- thread supports concurrent processing with multiple goroutines
- filter supports filtering special links
- depth can be set to control the scraping depth
5.5. Example
More examples can be found in the source code link (https://github.com/gocolly/colly/tree/master/_examples)
Git leak && AWS AKSK && AWS Lambda cli && Function Information Leakage && JWT secret leak
Defense world web guidance mode framework summary
Aftermath: A free and open-source event response framework for macOS
Four. Java Web Application Server (such as Tomcat)
Introduction to Java Agent Memory Horses
Enhanced plugin framework design based on SPI
Improving Threat Detection Capabilities with the MITRE ATT&CK Security Knowledge Framework

评论已关闭