When enterprises need to build independent data warehouse systems to support BI and business analysis, the hybrid architecture of 'data lake + data warehouse' has emerged. However, the hybrid architecture brings higher construction costs, management costs, and business development costs. With the development of big data technology, by adding distributed transactions, metadata management, extreme SQL performance, and SQL and data API interface capabilities at the data lake layer, enterprises can support data lake and data warehouse business on a unified architecture, which is what we call the lakehouse architecture.


Introduction to Lakehouse Architecture
Traditional enterprise data lakes are mostly built on Hadoop or cloud storage, providing semi-structured and unstructured data capabilities for data science and machine learning tasks. Enterprises require strict consistency guarantees for data processing processes such as BI and business analysis, and excellent SQL performance during the analysis process. Open-source Hadoop or cloud storage does not have these capabilities, so enterprises need to build independent data warehouse systems to support such business, thus giving rise to the hybrid architecture of 'data lake + data warehouse'. The hybrid architecture brings higher construction costs, management costs, and business development costs. With the development of big data technology, by adding distributed transactions, metadata management, extreme SQL performance, and SQL and data API interface capabilities at the data lake layer, enterprises can support data lake and data warehouse business on a unified architecture. The industry and open-source community are exploring related technologies陆续, and Xinghuan Technology began to develop related technologies based on Hadoop in 2014, and provided capabilities such as distributed transactions in the relational analysis engine Inceptor in 2016. In 2017, Uber engineers began to develop the Apache Hudi project, Netflix open-sourced the Iceberg project in 2019, and Databricks launched Delta Lake on its cloud service in 2020. These projects all attempt to address the need for data warehouse capabilities on data lakes and have received extensive participation and strong promotion from the technical community.
The 'Lake-Warehouse Integration Technology Research Report' released by CCID Consulting in July 2022 points out that the main key features of the lake-warehouse integration architecture include:
- Supporting the analysis and exploration of multi-model data, including structured, semi-structured (such as JSON) and unstructured data
- Transaction support, ensuring consistency and accuracy under concurrent data operations.
- BI support, BI tools can be used directly on the source data, without going through a long data chain from complex data warehouse modeling to data mart for business analysis, with high timeliness of business response.
- One copy of data storage, directly doing data governance within the data lake, reducing the computing and storage costs caused by data duplication and redundant flow.
- Separation of storage and computing, data storage is globally shared and can be expanded or reduced in capacity according to requirements, while computing power can be flexibly scaled according to computing needs, with computing and storage expanding independently according to their respective needs.
- Business openness, supporting standardized SQL and API, and can flexibly support various machine learning languages and frameworks.
The 'Lake-Warehouse Integration Technology Research Report' also points out that there are three ways to implement the landing path of lake-warehouse integration in terms of technical implementation paths:
The first methodIt is an extension of the data lake capability based on the Hadoop ecosystem, building a data warehouse directly in the data lake, thereby ultimately evolving into a lake-warehouse integration. This allows for the construction of a data warehouse system on the storage of the relatively low-cost data lake, requiring good transaction support and SQL performance. Some foreign companies that have been successful in digitalization, such as Uber, use these technology routes, adopting new storage formats like Hudi on Hadoop to support the business needs of data warehouses. StarRing Technology, a domestic company, is a major advocate for this technology. StarRing Technology has already implemented distributed transaction support and SQL capabilities based on HDFS and ORC file formats in 2015. Therefore, StarRing products have gone through hundreds of customer production practices and refinements, having a better maturity than open-source technology frameworks and have helped many customers implement the lake-warehouse integration architecture.
The second methodis based on cloud platform storage or third-party object storage, and builds a data lake and warehouse integration architecture on top of it. Some cloud vendors are promoting this route. This route implements storage-level compute-separation based on cloud services, and distributed transactions, metadata management, and other capabilities depend on self-developed technology frameworks or integrated open-source Iceberg.
The third methodis deeply developed based on database technology, further supporting various data models and compute-separation storage technologies to meet the needs of data lakes, represented by Snowflake and Databricks. Below, we will discuss the implementation principles and differences of Apache Hudi, Iceberg, Delta Lake, and StarRocks Inceptor in two parts.
— Apache Hudi—
Hudi is an abbreviation for Hadoop Upserts, Deletes, and Incrementals, as the name implies, it is designed to provide update, delete, and incremental data processing capabilities on Hadoop. Hudi is a data lake project designed by Uber engineers to meet their internal data analysis needs, and its business scenarios mainly involve synchronizing the trip order data generated online to a unified data center, and then providing it to the city operation colleagues for analysis and processing. In 2014, Uber's data lake architecture was relatively simple, business logs were synchronized to S3 via Kafka, and upper-level data analysis was done with EMR; relational databases and NoSQL databases online would be synchronized to the closed-source Vertica analytical database through ETL tasks, and city operation colleagues mainly implemented data aggregation through Vertica SQL, but the high cost of system expansion restricted the development of the business. Later, the Uber team migrated to the open-source Hadoop ecosystem, solving issues such as expansion, but the native Hadoop does not provide high-concurrency distributed transactions and data modification/deletion capabilities. Therefore, Uber's ETL tasks regularly synchronize incremental update data to the analytical tables every 30 minutes, rewriting all existing full data files, resulting in high data latency and resource consumption. In addition, at the downstream of the data lake, a large number of streaming jobs consume new written data incrementally, and the incremental streaming consumption of the data lake is also an essential function for them. Therefore, they hope to solve not only the general data lake needs through the Hudi project but also achieve fast update/delete and streaming incremental consumption. In this way, Uber's data pipeline can be simplified to the form shown in the figure below, where DeltaStreamer is an independent data ingestion service responsible for reading data from upstream and writing it to Hudi.
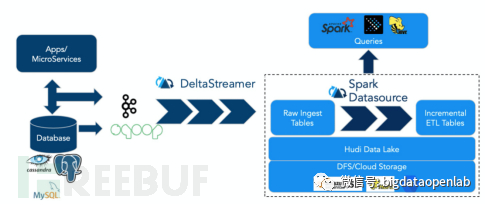
Fast update and delete are core requirements, so the Hudi project has done a lot of system design for this need. If it is necessary to modify the data within the data file, the most original way is to read the initial data file into memory, merge it with the data to be modified in memory, and then write the data back to the data file. This results in all data being read and written once, which is extremely slow if the file is large. The MVCC mechanism can solve this problem, as it writes each incremental update to a separate delta file instead of modifying the initial data file. When reading data, both the initial data and the delta file data are read into memory, and then merged according to the data version and the new and old situations. Hudi further refines the MVCC design, designing two data table formats, Copy on Write and Merge on Read, for different scenarios. The Copy on Write format table generates a full new data version after each transaction operation, so the speed of subsequent data table reads is relatively fast but the transaction operation is slow, which is suitable for some small and medium-sized data tables with low frequency modifications but high frequency reads, such as code tables. The Merge on Read format data table writes an independent delta/delete file during modification operations, and when reading, it reads the base file and delta file into memory together and merges them according to the records. This method is fast for modifications but relatively slow for reads, and is more suitable for large data volume tables or tables with frequent modifications. Developers can choose an appropriate mode for each table according to business needs. It is worth mentioning that most storage engine implementations default to the Merge on Read format.


Columnar storage has better data analysis performance, but because it cannot accurately locate a record line, the point query performance is generally poor. Hudi designs a similar primary key HoodieKey to better query performance, and provides functions like BloomFilter on HoodieKey, so whether it is point query or precise data delete, it can find the data area that needs to be modified faster, thus improving the performance of transaction operations.
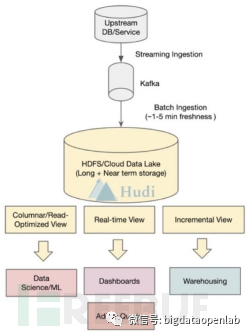
In addition, to support incremental streaming data reading, Hudi supports providing three different reading perspectives to the upper analysis engine: only reading incremental files (Incremental View), only reading initial data (Read-Optimized View), and merging to read all data (Real-time View). For real-time data analysis, it can read only incremental files. For some businesses with low accuracy requirements for data, such as machine learning, it can adopt the method of reading initial data to speed up, while for data warehouse tasks that require data consistency, it needs to adopt the method of merging to read all data.
Different from Apache Delta Lake, which is mainly for structured data ETL and statistical analysis, as well as better real-time calculation effects, all around the SQL business, Apache Hudi is mainly for the ETL and statistical analysis of structured data and better real-time calculation effects, focusing on SQL business, so it does not take much into consideration the needs of machine learning programming languages and frameworks in its design.
— Apache Iceberg—
Netflix's data lake was initially built using Apache Hive, with the underlying data storage based on HDFS, while Hive provides the guarantee of data table schema and limited ACID function support. Since Hive requires an independent metastore to provide data table metadata queries, under the condition of especially large data partition, the performance of metastore is insufficient, which leads to the fact that the query and analysis performance on some data tables with many partitions cannot meet business needs, which was the biggest problem faced by the Netflix team at that time. In addition, Hive's ACID implementation is not complete, and a transaction writing to HDFS and metastore may have insufficient atomicity, and there may be some inconsistencies in data under some failure conditions, requiring additional data verification work. Moreover, Netflix hopes to expand to object storage to achieve the separation of storage and computing. Based on the above reasons, Netflix built the Iceberg project to hope to solve various problems that arise in building a data lake. It should be pointed out especially that Iceberg is a data table storage format designed for data lake systems, not an independent process or service, which is the biggest difference from Delta Lake and Hudi. It requires the computation engine to load the Iceberg library.
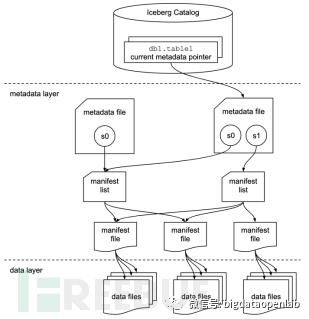
As Iceberg aims to solve various problems caused by a large number of partitions encountered by Netflix, it focuses on designing metadata management of data tables and partition-related functions. Unlike other engines that rely on a single meta service, Iceberg stores metadata directly in files, as shown in the figure above. All states of the table are stored in the metadata file, and any new modifications to the table will generate a new metadata file, which saves the table schema, partition, snapshot, and some other table attribute information. This design is for Iceberg to solve the problem that other engines need to rely on an additional independent meta service, and the meta service may have performance bottlenecks.
The physical data storage of the Iceberg table is saved in the form of data files, which is different from the two-level structure of 'directory-file' adopted by other systems (such as Hive, Hudi, etc.). This is because other systems rely on file directories for partition slicing, and when the SQL optimizer performs partition pruning optimization, it needs to call the remote API of the file system multiple times to determine the status of each directory, thereby determining the partition and performing pruning according to the execution plan. Since the API calls of the file system are relatively slow compared to memory computing, especially when the number of partitions is large, it often takes a lot of time. The method adopted by Iceberg is to use multiple manifest files to directly manage data files, so that the computing engine can directly load the manifest files into the content, thereby only needing to perform partition pruning calculation in memory during optimization, without the need for multiple visits to the file system, thereby improving access speed. The manifest files record and point to the corresponding data files, and each data file is recorded in a line in the manifest file, including partition information and some metrics data, which provides data support for subsequent partition optimization.
Based on this architectural design, every transaction operation on a data table generates a new metadata file. After each commit, the Iceberg catalog points to this new metadata file through an atomic operation. Therefore, in terms of transaction isolation levels, Iceberg can only provide the Serializable isolation level and cannot provide other higher isolation levels. Moreover, all transaction operations are at the table level, while most other storage engines can achieve partition level. This design can lead to more lock conflicts in actual production business under concurrent operations, such as in the wide table of the data warehouse intermediate layer, where multiple data streams are processed simultaneously, resulting in a large number of lock conflicts. Iceberg adopts the optimistic concurrency control (optimistic concurrency) strategy, and after a conflict occurs, the current session's SQL transaction operation will be retried based on the new transaction data. The advantage of this method is that the transaction protocol implementation is relatively simplified, but the disadvantage is that the more concurrent transaction operations on the same table, the higher the transaction abort rate will be, and it will waste SQL computing resources. Therefore, in terms of transaction support, Iceberg is relatively weaker than other projects.
In the implementation of MVCC, Iceberg also adopts the Merge on Read approach. All modification operations within a transaction are stored independently in the delete file. In design, Iceberg fully leverages the idea of database binlog. There are two ways to record actions in the delete file: one is position deletes, which records in detail which data file's row is deleted, and is mainly used for precise deletion of a small amount of data; the other is Equality deletes, which cannot record which specific rows are deleted, but will record the expression used to select these data rows and perform deletion, and is mainly used for batch deletion operations. Since there is no need to directly modify data in the data file, nor is there a need for a random access file, Iceberg has relatively low requirements for the underlying file system, and does not require transaction, random access, or POSIX interfaces at the file system level. Even the simplest S3 object storage can support it, which also ensures that Netflix can build a data lake based on object storage in the future.
In summary, Iceberg adopts a very different architectural design to address some of the issues encountered by Netflix. Its core lies in solving the performance and scalability issues of meta-data in data query scenarios, especially the performance issues under the condition of too many partitions; it can provide ACID functions in data operations but has relatively weak transaction concurrency performance; it can be used to build data lakes based on object storage. Moreover, as Iceberg itself is not a storage engine, it cannot provide functions like primary keys and needs to be used in conjunction with computing engines such as Spark and Presto. Therefore, the characteristics of the corporate groups that are suitable for Iceberg are also very distinctive, such as the marketing and risk control scenarios of typical online internet companies, which have a large amount of real-time data or log-like data, all of which are conducted with fine-grained data analysis along the timeline. The value of recent data is high while the value of medium and long-term data is not significant. The number of data partitions is particularly large, and there is the development and optimization capability of computing engines. Due to its relatively weak transaction capabilities, it is not very suitable for high-concurrency data batch processing and data warehouse modeling work. In addition, extra attention needs to be paid to data security management, as the damage to metadata files may lead to data loss.
Summary
This article introduces two lakehouse architectures, Apache Hudi and Apache Iceberg, and the next article will continue to introduce Xinghuan Technology's Inceptor and Delta Lake technologies.

评论已关闭