Authors: Xiang Qiang, Huang Wei, Zhang Junjie, JD Retail
Background
The department maintains an old system, where all the functions are coupled in a monolithic application (300+ interfaces), and the tables are also placed in the same database (200+ tables), which leads to many risks and defects in the system. Frequent problems occur: such as single points in the database, performance issues, limited expansion of applications, and high complexity, etc.

As can be seen from the following figure, the various businesses are coupled without clear boundaries, and the calling relationship is complex.
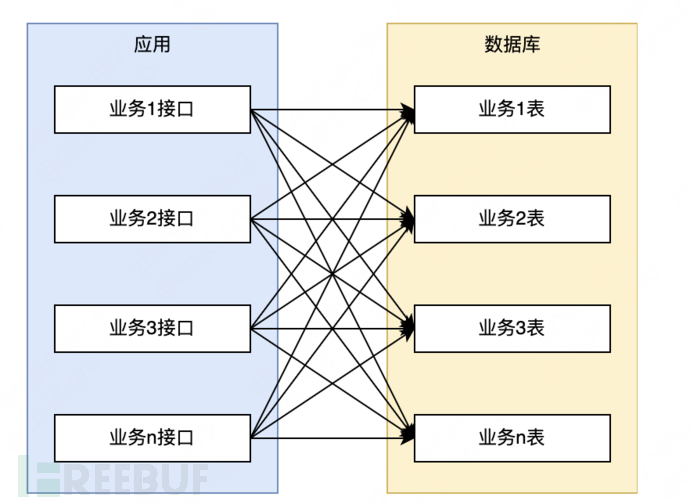
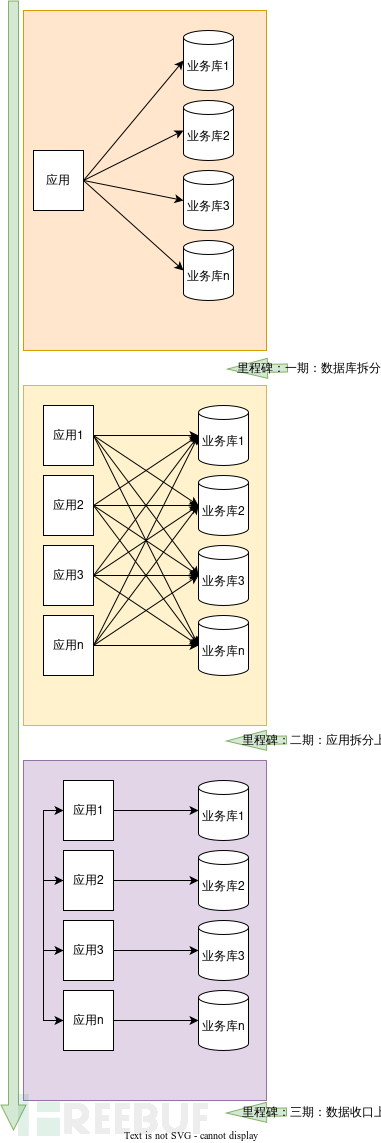
With the rapid development of the business, various problems become more and more obvious, and it is urgent to optimize the system through microservice transformation. After thinking, the overall transformation will be carried out in three stages:
Database splitting: databases are split vertically according to business.
Application splitting: applications are split vertically according to business.
Data access permission control: data permissions are classified according to their respective business domains and belong to their respective applications. Applications are one-to-one with databases, and cross-access is prohibited.
Database splitting
Pains of a monolithic database: no business isolation, a slow SQL can easily cause the overall system to have problems; high throughput, high read and write pressure, performance decline;
Database modification

According to business division, we plan to split the database into 9 business databases. The data synchronization method adopts master-slave replication, and the corresponding tables and data are synchronized to the corresponding new databases through binlog filtering.
Code modification plan
If multiple tables are operated in an interface, and these tables previously belonged to the same database, after the database is split, they may belong to different databases. Therefore, it is necessary to make corresponding modifications to the code.
The location of the existing problem:
Data Source Selection: The system previously supported multi-data source switching, and annotations were added to the service to select the data source. After the database splitting, the situation is that multiple mappers operated in the same service belong to different databases.
Transaction: The transaction annotation currently exists on the service, and the transaction caches the database connection, and it is not supported to operate multiple databases at the same time within a transaction.
Sorting of Transformation Points:
Interfaces writing to multiple databases and in the same transaction 6: data source transformation is required, transaction transformation is required, and attention needs to be paid to distributed transactions;
Interfaces writing to multiple databases and not in the same transaction more than 50: data source transformation is required, and transaction transformation is required, but there is no need to pay attention to distributed transactions;
Interfaces reading multiple databases or reading one database and writing to another database more than 200: data source transformation is required, but there is no need to pay attention to transactions;
The joint query of tables involving multiple databases 8: code logic transformation is required
Sorting Method:
Using the aspect tool in the department, capture the entry and table call relationship (recognizable table read/write operations), find an interface that operates multiple tables, and the tables are distributed among different business databases;
Distributed Transactions:
After the application splitting and data collection, there is no problem of distributed transactions because the operation of the second database will call the RPC interface of the corresponding system for operation. Therefore, this time we will not officially support distributed transactions, but will adopt a way to ensure consistency through code logic to solve it;
Scheme 1
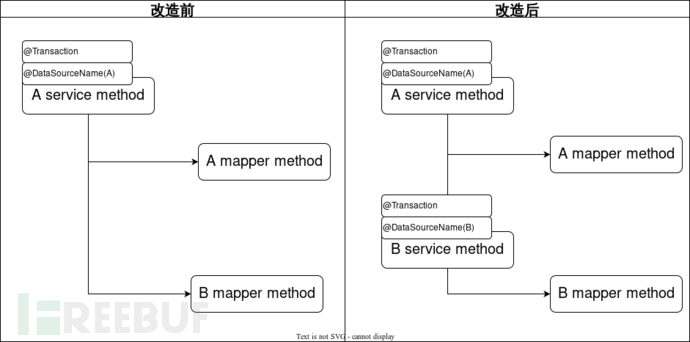
Extract the mappers that operate multiple databases in the service into multiple Services. Add the data source switching annotation and transaction annotation separately.
Problem: The modification involves many locations, and each modified method needs to sort out the historical business logic; there are many nested calls in the service, which are sometimes difficult to understand logically; modifying more than 200 locations requires a lot of work and high risk;
Scheme 2

As shown in the figure, the second scheme moves the data source annotation to the Mapper and uses a custom transaction implementation to handle transactions.
The benefit of placing the multi-data source annotation on the Mapper is that it is not necessary to sort out the code logic, but only add the corresponding data source name on the Mapper. However, new problems will arise in this way.
Problem 1: As shown in the figure, the transaction is configured in the Service layer. When the transaction is opened, the connection of the data source is not obtained because the actual data source configuration is on the Mapper. Therefore, an error will occur, which can be solved by the default data source function of the multi-data source component.
Problem 2: MyBatis implements transactions by caching database connections. After the first cache of the database connection, subsequent configuration of the data source annotation on the mapper will not re-fetch the database connection, but will directly use the cached database connection. If the subsequent mapper needs to operate other databases, it may encounter the situation where the table cannot be found. In view of the above problem, we have developed a custom transaction implementation class to solve this problem.
The following will briefly explain the principles of the two components that appear in the plan.
Multi-datasource component
The multi-datasource component is a tool used when a single application connects to multiple data sources. Its core principle is to initialize the database connections through a configuration file at the start of the program. When executing a method with annotations, the aspect is used to obtain the current data source name to switch the data source. When a single call involves multiple data sources, the stack's properties are used to solve the problem of data source nesting.
/**
* Aspect method
*/
public Object switchDataSourceAroundAdvice(ProceedingJoinPoint pjp) throws Throwable {
// Get the name of the data source
String dsName = getDataSourceName(pjp);
boolean dataSourceSwitched = false;
if (StringUtils.isNotEmpty(dsName)
&& !StringUtils.equals(dsName, StackRoutingDataSource.getCurrentTargetKey())) {
// See the next piece of code
StackRoutingDataSource.setTargetDs(dsName);
dataSourceSwitched = true;
}
try {
// Execute aspect method
return pjp.proceed();
}
throw e;
}
if (dataSourceSwitched) {
StackRoutingDataSource.clear();
}
}
}
public static void setTargetDs(String dbName) {
if (dbName == null) {
throw new NullPointerException();
}
if (contextHolder.get() == null) {
contextHolder.set(new Stack<String>());
}
contextHolder.get().push(dbName);
log.debug("set current datasource is " + dbName);
}
StackRoutingDataSource inherits the AbstractRoutingDataSource class, which is an abstract class provided by the spring-jdbc package that implements the AbstractDataSource abstract class. It implements the DataSource interface's method for obtaining database connections.
Custom transaction implementation
From the figure of Plan Two, it can be seen that the default transaction implementation uses MyBatis's SpringManagedTransaction.
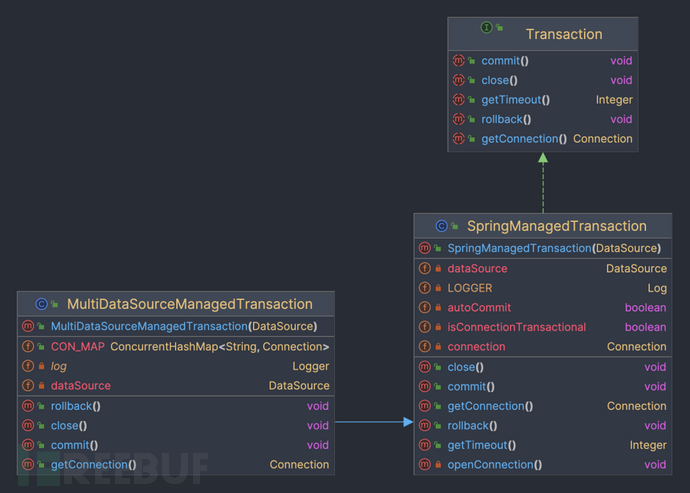
As shown in the figure above, both Transaction and SpringManagedTransaction are classes provided by MyBatis, which provide interfaces for SqlSession to use and handle transaction operations.
From the following code, it can be seen that there is a connection variable in the transaction object. After obtaining the database connection for the first time, all subsequent database operations within the current transaction will not retrieve a new database connection, but will use the existing database connection, thereby not supporting cross-database operations.
public class SpringManagedTransaction implements Transaction {
private static final Log LOGGER = LogFactory.getLog(SpringManagedTransaction.class);
private final DataSource dataSource;
private Connection connection;
private boolean isConnectionTransactional;
private boolean autoCommit;
public SpringManagedTransaction(DataSource dataSource) {
notNull(dataSource, "No DataSource specified");
this.dataSource = dataSource;
}
// Omitted
}
MultiDataSourceManagedTransaction is our custom transaction implementation, inheriting from the SpringManagedTransaction class and supporting the maintenance of multiple database connections internally. Each time a database operation is executed, it will determine the data source name and if the current data source does not have a cached connection, it will retrieve a new one. This means that the transaction annotation on the service actually controls multiple single-database transactions with the same scope, which are submitted or rolled back together.
The code is as follows:}
public class MultiDataSourceManagedTransaction extends SpringManagedTransaction {
private DataSource dataSource;
public ConcurrentHashMap<String, Connection> CON_MAP = new ConcurrentHashMap<>();
public MultiDataSourceManagedTransaction(DataSource dataSource) {
super(dataSource);
this.dataSource = dataSource;
}
@Override
public Connection getConnection() throws SQLException {
Method getCurrentTargetKey;
String dataSourceKey;
try {
getCurrentTargetKey = dataSource.getClass().getDeclaredMethod("getCurrentTargetKey");
getCurrentTargetKey.setAccessible(true);
dataSourceKey = (String) getCurrentTargetKey.invoke(dataSource);
}
log.error("MultiDataSourceManagedTransaction invoke getCurrentTargetKey exception", e);
return null;
}
if (CON_MAP.get(dataSourceKey) == null) {
Connection connection = dataSource.getConnection();
if (!TransactionSynchronizationManager.isActualTransactionActive()) {
connection.setAutoCommit(true);}
}
connection.setAutoCommit(false);
}
CON_MAP.put(dataSourceKey, connection);
return connection;
}
return CON_MAP.get(dataSourceKey);
}
@Override
public void commit() throws SQLException {
if (CON_MAP == null || CON_MAP.size() == 0) {
return;
}
Set<Map.Entry<String, Connection>> entries = CON_MAP.entrySet();
for (Map.Entry<String, Connection> entry : entries) {
Connection value = entry.getValue();
if (!value.isClosed() && !value.getAutoCommit()) {
value.commit();
}
}
}
@Override
public void rollback() throws SQLException {
if (CON_MAP == null || CON_MAP.size() == 0) {
return;
}
Set<Map.Entry<String, Connection>> entries = CON_MAP.entrySet();
for (Map.Entry<String, Connection> entry : entries) {
Connection value = entry.getValue();
if (value == null) {
continue;
}
if (!value.isClosed() && !value.getAutoCommit()) {
entry.getValue().rollback();
}
}
}
@Override
public void close() throws SQLException {
if (CON_MAP == null || CON_MAP.size() == 0) {
return;
}
Set<Map.Entry<String, Connection>> entries = CON_MAP.entrySet();
for (Map.Entry<String, Connection> entry : entries) {
DataSourceUtils.releaseConnection(entry.getValue(), this.dataSource);
}
CON_MAP.clear();
}
}
Note: The above is not a distributed transaction. Before the data is collected, it only exists within the same JVM. If the project allows, consider using the Atomikos and Mybatis integrated solution.
Data Security
Many code modifications have been made in this iteration. How to ensure data security and prevent data loss? Our mechanism is as follows, and we discuss three scenarios:
Cross-database transaction: 6 locations, adopts code modification to ensure consistency; it has been tested extensively before going online to ensure that the logic is correct;
Single database transaction: It depends on custom transaction implementation, and it is sufficient to thoroughly test this class for the custom transaction implementation; the test scope is small, and security is guaranteed;
Other single-table operations: The related modifications are to add data source switching annotations on the mapper, with changes in hundreds of locations, almost brainless changes, but there is still a possibility of omissions or incorrect changes; test colleagues can cover the core business process, but the edge business may be omitted; we have added an online monitoring mechanism, when there is an error of not finding a table (indicating that the data source switching annotation has been added incorrectly), record the current executing SQL and issue an alarm, and we carry out logical repair and data processing.
In summary, we ensure the security of data by dealing with three situations.
Application Splitting
The system is close to a monolithic architecture, and the following risks exist:
Systemic risk: A component defect can cause the entire process to crash, such as memory leaks, deadlocks.
High complexity: There are many system codes, and we are always scared to modify the code, any bug can cause the entire system to crash, and we dare not optimize the code, which also leads to worse code readability.
Testing environment conflicts, low testing efficiency: all businesses are coupled in one system, and there will be environment occupation as soon as there is a requirement, requiring additional branches to merge code.
Splitting Plan
Like database splitting, system splitting is also split into 9 new systems based on business division.
Option one: Build an empty new system, and then move the relevant code from the old system to the new system.
Advantages: One step at a time.
Disadvantages: Need to subjectively select code, then move it to the new system, which can be regarded as making full business logic changes, requiring full testing, high risk, and long cycle.
Option two: Copy 9 new systems from the old system unchanged, then directly launch them, forward the traffic of the old system to the new system through traffic routing, and then reduce the redundant code of the new system later.
Advantages: Fast splitting speed, no business logic changes before the first launch, low risk; subsequent code reduction is based on the number of interface calls, which can also be regarded as no business logic changes, low risk, and each system can be carried out independently, without the need for overall scheduling, more flexible.
Disadvantages: Split into two steps, splitting deployment and code reduction

After considering the risks and efficiency of splitting, we finally chose option two.
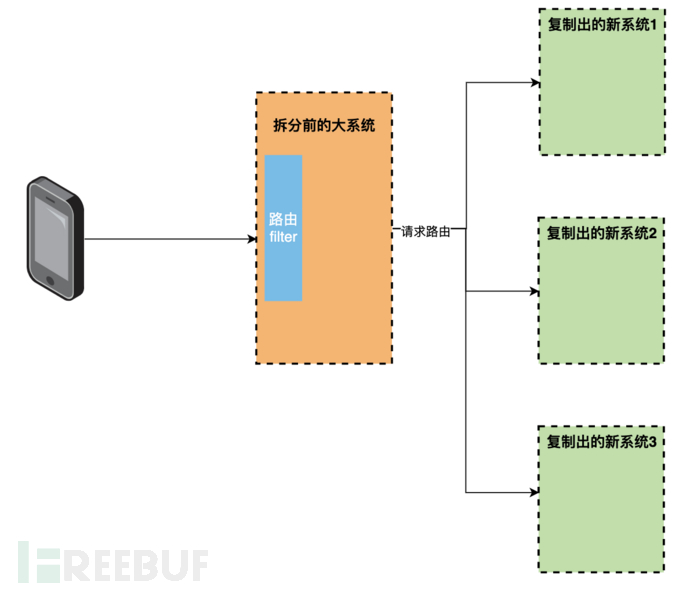
Splitting Practice
1. Build a new system
Directly copy the code from the old system, modify the system name, and deploy it.
2. Traffic Routing
The router is the core of splitting, responsible for distributing traffic to the new system, while also needing to support the identification of test traffic, allowing test colleagues to test the new system online in advance. We use filter as the router here, and the source code is shown below.
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws ServletException, IOException {
HttpServletRequest servletRequest = (HttpServletRequest) request;
HttpServletResponse servletResponse = (HttpServletResponse) response;
// Routing switch (0 - do not route, 1 - route based on specified request header, 2 - full routing)
final int systemRouteSwitch = configUtils.getInteger("system_route_switch", 1);
if (systemRouteSwitch == 0) {
filterChain.doFilter(request, response);
return;
}
// Only route test traffic
if (systemRouteSwitch == 1) {
// Check if the request header contains the test traffic identifier. Route only if it is present
String systemRoute = ((HttpServletRequest) request).getHeader("systemRoute");
if (systemRoute == null || !systemRoute.equals("1")) {
filterChain.doFilter(request, response);
return;
}
}
String systemRouteMapJsonStr = configUtils.getString("route.map", "");
Map<String, String> map = JSONObject.parseObject(systemRouteMapJsonStr, Map.class);
String rootUrl = map.get(servletRequest.getRequestURI());
if (StringUtils.isEmpty(rootUrl)) {
log.error("Routing failed, internal processing of local service. Reason: Request address cannot be mapped to the corresponding system, uri: {}", servletRequest.getRequestURI());
filterChain.doFilter(request, response);
return;
}
String targetURL = rootUrl + servletRequest.getRequestURI();
if (servletRequest.getQueryString() != null) {
targetURL = targetURL + "?" + servletRequest.getQueryString();
}
RequestEntity<byte[]> requestEntity = null;
try {
log.info("Route started targetURL = {}", targetURL);
requestEntity = createRequestEntity(servletRequest, targetURL);
ResponseEntity responseEntity = restTemplate.exchange(requestEntity, byte[].class);
if (requestEntity != null && requestEntity.getBody() != null && requestEntity.getBody().length > 0) {
log.info("Route completed - Request information: requestEntity = {}, body = {}", requestEntity.toString(), new String(requestEntity.getBody()));
}
log.info("Route completed - Request information: requestEntity = {}", requestEntity != null ? requestEntity.toString() : targetURL);
}
HttpHeaders headers = responseEntity.getHeaders();
String resp = null;
if (responseEntity.getBody() != null && headers != null && headers.get("Content-Encoding") != null && headers.get("Content-Encoding").contains("gzip")) {
byte[] bytes = new byte[30 * 1024];
int len = new GZIPInputStream(new ByteArrayInputStream((byte[]) responseEntity.getBody())).read(bytes, 0, bytes.length);
resp = new String(bytes, 0, len);
}
log.info("Route completed - Response information: targetURL = {}, headers = {}, resp = {}", targetURL, JSON.toJSONString(headers), resp);
if (headers != null && headers.containsKey("Location") && CollectionUtils.isNotEmpty(headers.get("Location"))) {
log.info("Route completed - Need to redirect to {}", headers.get("Location").get(0));
((HttpServletResponse) response).sendRedirect(headers.get("Location").get(0));
}
addResponseHeaders(servletRequest, servletResponse, responseEntity);
writeResponse(servletResponse, responseEntity);
}
if (requestEntity != null && requestEntity.getBody() != null && requestEntity.getBody().length > 0) {
log.error("Route exception - Request information: requestEntity = {}, body = {}", requestEntity.toString(), new String(requestEntity.getBody()), e);
}
log.error("Route exception - Request information: requestEntity = {}", requestEntity != null ? requestEntity.toString() : targetURL, e);
}
response.setCharacterEncoding("UTF-8");
((HttpServletResponse) response).addHeader("Content-Type", "application/json");
response.getWriter().write(JSON.toJSONString(ApiResponse.failed("9999", "Network busy, please try again later")));
}
}
3. Interface Capture & Categorization
The routing filter distributes requests to various new systems based on the interface path, so it is necessary to capture a mapping relationship between the interface and the new system.
We have customized an annotation @TargetSystem to indicate the domain name of the target system to which the interface should be routed by annotation
@TargetSystem(value = "http://order.demo.com")
@GetMapping("/order/info")
public ApiResponse orderInfo(String orderId) {
return ApiResponse.success();
}
Then, iterate to obtain all controllers based on interface address and annotation to generate the routing mapping relationship map
/**
* Generate the routing mapping relationship MAP
* key: interface address, value: domain name of the target new system for routing
*/
public Map<String, String> generateRouteMap() {
Map<RequestMappingInfo, HandlerMethod> handlerMethods = requestMappingHandlerMapping.getHandlerMethods();
Set<Map.Entry<RequestMappingInfo, HandlerMethod>> entries = handlerMethods.entrySet();
Map<String, String> map = new HashMap<>();
for (Map.Entry<RequestMappingInfo, HandlerMethod> entry : entries) {
RequestMappingInfo key = entry.getKey();
HandlerMethod value = entry.getValue();
Class declaringClass = value.getMethod().getDeclaringClass();
TargetSystem targetSystem = (TargetSystem) declaringClass.getAnnotation(TargetSystem.class);
String targetUrl = targetSystem.value();
String s1 = key.getPatternsCondition().toString();
String url = s1.substring(1, s1.length() - 1);
map.put(url, targetUrl);
}
return map;
}
Transformation process
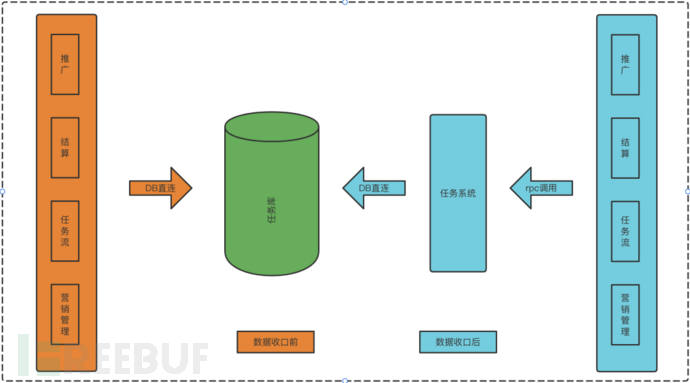
RPC interface statistics (as shown in Figure 1)
Perform comparison, if the classification of program entry and the classification of business DB called are inconsistent, then it is considered that the Dao method needs to provide RPC interfaces
According to statistics, there are more than 260+ locations where the application accesses non-business databases. Due to the large number of involved locations, manual modification costs are high, efficiency is low, and there is a risk of incorrect modification and omission, so we have adopted development tools to carry out code generation and batch modification for transformation.
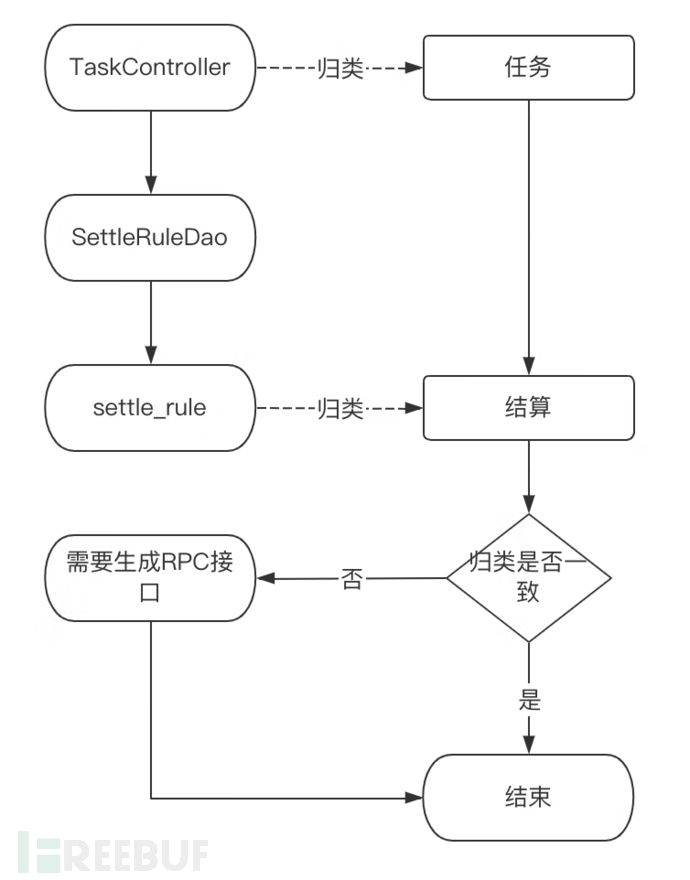
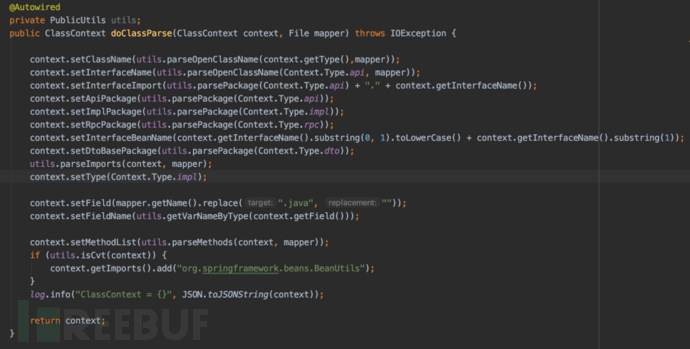
RPC interface generation (as shown in Figure 2)
Read the Dao file that needs to generate RPC interfaces and perform parsing
Obtain file name, Dao method list, import package list, and put them into the ClassContext context
Match the api, rpc file template, take values from classContext to replace template variables, generate java files to the specified service through the package path
Batch replace the suffix of the Dao name in the service with the Rpc service name, reduce the risk of manual changes, for example: SettleRuleDao -> SettleRuleRpc
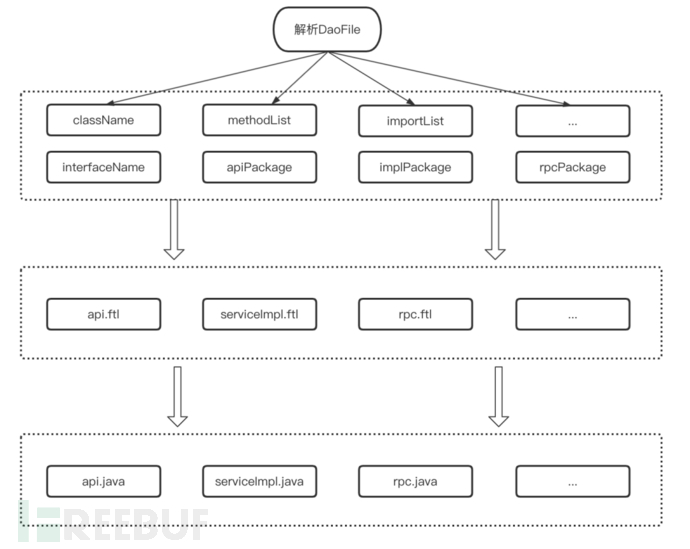
Explanation of Terms:
ftl: The file suffix name of the Freemarker template, Freemarker is a template engine, a text-based template output tool.
interfaceName: Used to store the filename of the api file
className: Used to store the filename of the serviceImpl file
methodList: Used to store the method list, including input parameters, output parameters, return values, and other information
importList: Used to store the import path of other referenced entities in api and impl files
apiPackage: Used to store the package name of the generated Api interface class
implPackage: Used to store the package name of the generated Api implementation class
rpcPackage: Used to store the package name of the generated rpc call class

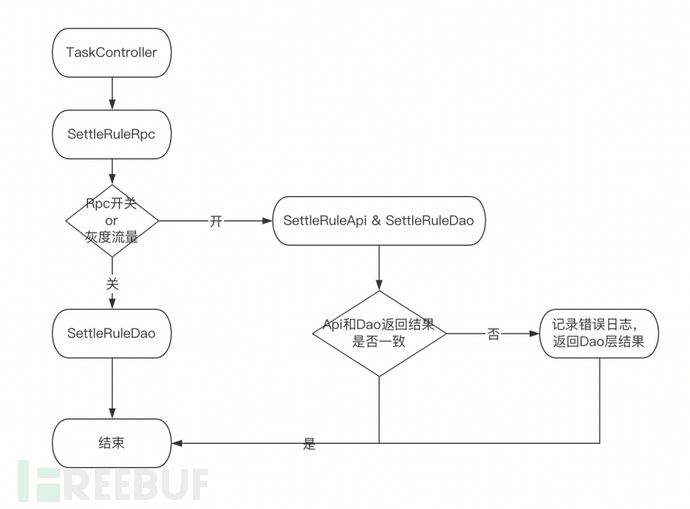
Gray-scale scheme (as shown in Figure 3)
Data operations are unified through RPC layer processing, and in the initial stage, the RPC layer handles both RPC calls and previous DAO calls, using a switch to switch.
Double read at the RPC layer, compare the return results of the API layer and the DAO layer, prioritize the return of the DAO layer results in the early stage, and verify that there are no problems before returning the full RPC results and clearing other business database connections.
Supports one-click switch, grayscale according to traffic, and reduces the risk of data intake
Benefits
Business data decoupling, data operations are unified by each vertical system, and the entry is unified
Convenient for adding cache and degradation processing at the interface granularity in the future
Summary
Above, we have transformed the monolithic system. After three steps of optimization and going online, the monolithic system has smoothly transitioned to a microservice architecture. It solves the single point problem and performance issues of the database, simplifies the application business, and is more conducive to division of labor and iteration. And it can be optimized and upgraded separately for each business, expanded and reduced, improving the utilization rate of resources.

评论已关闭