One: Case Background
In today's big data era, data storage and management have become a key link in the enterprise IT architecture. Distributed storage systems, due to their high availability, high scalability, and low cost, have gradually become the preferred choice for enterprise data storage. As an open-source distributed storage system, Ceph has received increasing attention and adoption from enterprises and units. However, while enjoying the convenience brought by Ceph, how to deal with data loss caused by accidental operations and other reasons has become a problem that enterprise IT operations personnel must face.
Two: Case Description
This article will introduce a case of data recovery in an OpenStack system when using KVM virtualization and Ceph distributed storage servers, due to the accidental deletion of configuration files and the absence of backup disaster recovery. We will elaborate on the causes of the problem, the recovery process, and preventive measures, providing reference and reference for operations personnel.

System Environment:
1. OpenStack Version: Pike
2. KVM Virtualization
3. Ceph Version: Luminous
4. Storage Servers: 4 in total, each configured with 32-core CPU, 128GB memory, 8TB hard disk * 8

Problem Description:
While the customer's operations team was performing routine maintenance on the OpenStack platform, they accidentally deleted a key configuration file of the Ceph distributed storage cluster in the KVM virtualization environment. This sudden situation immediately alerted the team, as the Ceph cluster's configuration files contain core data such as the definition of storage pools, the mapping of OSD (Object Storage Device), the osdmap, monmap, and monitoring information of the Ceph cluster. After deletion, some of the storage pools in the Ceph cluster could not be accessed normally, thereby affecting the normal operation of the entire cloud service business. Summarizing, there are three points:
Virtual Machine Failure to Start: The missing configuration files of KVM virtualization will cause virtual machines to fail to start or connect to the correct storage pool.
Storage Node Failure: If the Ceph configuration files are lost, it may cause storage nodes to fail to communicate correctly with each other, affecting data read and write operations.
Service Disruption: The entire OpenStack cloud platform's service may be interrupted due to missing configuration files, affecting the continuity of business operations.
Three: Solution
1.Emergency Response
After the customer contacted us, our technical team faced this emergency situation and immediately had the customer's operations team initiate the emergency response plan, taking the following measures:
1. Emergency Shutdown: Firstly, to avoid further data corruption, all operations that could affect the Ceph cluster, including data writing and reading, were immediately stopped.
2. Environmental Assessment: A comprehensive assessment of the current state of the Ceph distributed cluster is conducted to confirm the scope and extent of the affected areas, including which configuration files are missing and whether data corruption has occurred.
2.Recovery Challenges
Data recovery without backup disaster recovery on the server is extremely challenging, and the main challenges include:
No backup available: Traditional recovery methods depend on existing backups, and in the absence of backups, it is necessary to reconstruct the lost configuration through log files, metadata, and other remaining data.
System complexity: The configuration of OpenStack platform and Ceph distributed storage is complex, and a slight mistake in the recovery process may cause permanent data loss.
Time pressure: In actual business environments, service interruption can cause huge losses, therefore, it is necessary to recover quickly and accurately.
3.Case Evaluation
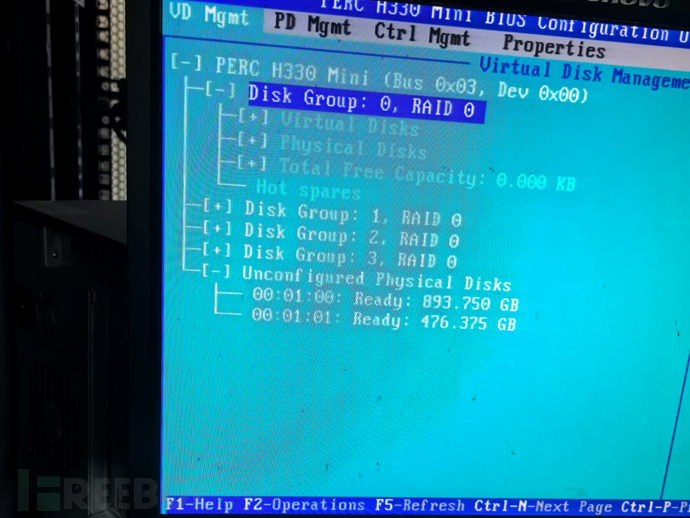
Firstly, we need to understand the distributed storage mechanism of Ceph. Unlike other distributed storage systems, Ceph provides interfaces for block storage, file storage, and object storage on top of the so-called RADOS core object storage architecture, thus Ceph can be called unified storage (Unified Storage). Ceph is mainly composed of three types of components: Monitors, Managers, and OSDs. Among them, Monitors are responsible for maintaining cluster status information, Managers are responsible for managing cluster resources, and OSDs are responsible for storing data.
The underlying layer of Ceph is RADOS (a distributed object storage system), which consists of two parts: OSD and MON. MON is responsible for monitoring the entire cluster, maintaining the health status of the cluster, and maintaining various charts that display the cluster status, such as OSDMap, MonitorMap, PGMap, and CRUSHMap. OSD is responsible for storing data, replicating data, balancing data, recovering data, and performing heartbeat checks with other OSDs. Under normal circumstances, one hard disk corresponds to one OSD.
The storage process of Ceph distributed data, regardless of which storage method (object, block, file) is used, the stored data will be divided into objects (Objects).
Storage Pool: Different users store objects in different storage pools for different purposes, and these objects are distributed on OSDs. Objects stored in different storage pools (Pool) are the logical groups of object storage, corresponding to different users. The storage pool manages the number of placement groups, the number of replicas, and the set of storage pool rules.
Placement Group: Placement Group (PGPlacementGroup) is a fragment of the object pool. Ceph performs calculation operations based on the object's Oid and some other information, mapping to placement groups, and numerous objects are divided into different placement groups. PG is a logical concept, similar to an index in a database in terms of data addressing. Each object is mapped into a fixed PG, so when we need to find an object, we only need to find the PG of the object first, and then traverse this PG, without the need to traverse all objects. Moreover, during data migration, it is also done with PG as the basic unit.
OSD: Finally, the PG will replicate according to the number of replicas set by the administrator, and then store it on different OSD nodes through the crush algorithm, ultimately storing all objects in the PG on OSD nodes.
BlueStore: In the new version, Ceph defaults to Bluestore as the storage engine, serving as the underlying implementation of the ObjectStore storage for OSDs in RADOS, the overall architecture of BlueStore.
Storage space: BlueStore divides the entire storage space into three parts: WAL, DB, and SLOW. Slow space: mainly used to store object data, managed by BlueStore. Fast (DB) space: stores data generated by blufs and rocksdb, directly managed by BlueFS, and if there is no DB device or the space of the DB device is insufficient, it will choose the Slow type device space. Ultra-fast (WAL) space: mainly stores the WAL files of RocksDB (i.e., .log), directly managed by BlueFS, and if there is no WAL device or the space of the WAL device is insufficient, it will choose the DB and SLOW partitions in turn.
Rocksdb: BlueStore uses Rocksdb as the underlying implementation for its metadata storage, storing various metadata in the database in the form of kv records. Writing mechanism: any write of metadata is first written to WAL, and then written to MemoryTable (Memtable). When a Memtable is full, it becomes an immutable Memtable, and RocksDB will flush this Memtable to disk in the background through a flush thread, generating a SortedStringTable (SST) file.
BlueFS: BlueFS, different from the general file system, is a slim file system designed for Rocksdb specifically by Bluestore. The metadata of BlueFS files and directories is stored in log files in the form of log transactions, and during the power-on process, replaying the transactions in the log files can load all the metadata into memory.
In this case, due to the accidental deletion of the configuration file, some OSDs failed to operate normally, thereby affecting the access to the storage pool. We also conducted an in-depth analysis of the Ceph log files, trying to find any possible clues from the logs, such as records of configuration file modifications or abnormal operations. Although the log files cannot directly recover the lost configuration files, they provide valuable reference information to help confirm the correctness and integrity of the recovery operations.
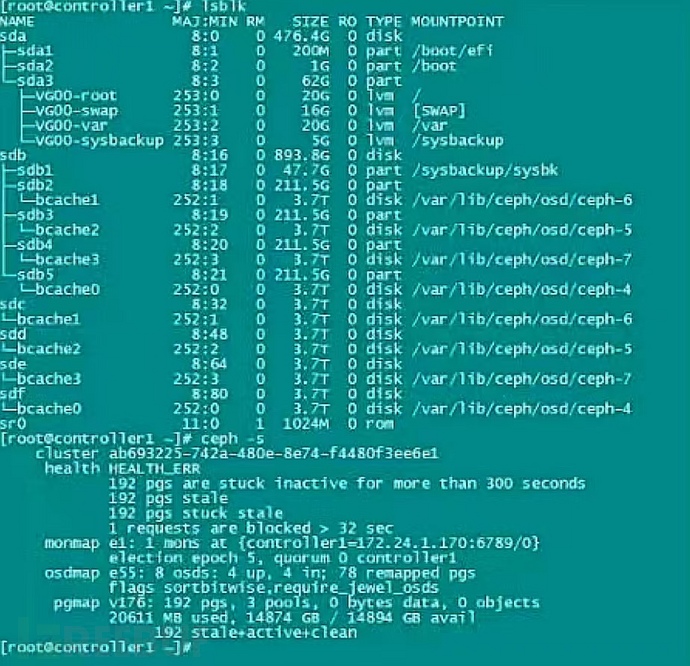
4.Recovery plan
First of all, let's sort out the main process of routine handling after the distributed failure of Ceph, which is divided into three major steps:
- Perceive the cluster status
The Ceph cluster is divided into two major parts: the MON cluster and the OSD cluster. The MON cluster consists of an odd number of Monitor nodes, which form a decision-making cluster through the Paxos algorithm to make decisions on key cluster events and broadcast. 'OSD node leaves' and 'OSD node joins' are two key cluster events.
The MON cluster manages the member status of the entire Ceph cluster and stores the status information of OSD nodes in the OSDMap. OSD nodes periodically send heartbeat packets to MON and peer OSDs (Peer OSD) to declare their online status. MON receives heartbeat messages from OSD to confirm the online status of OSD; at the same time, MON also receives failure detection notifications from OSD for Peer OSDs. MON determines whether an OSD is online based on heartbeat intervals and other information, updates the OSDMap, and notifies the latest cluster status to each node. For example, if a server fails, the heartbeat timeout of the OSD node on it or the MON cluster, or if the failure notifications sent by these OSDs' peer OSDs exceed the threshold, these OSDs will be deemed offline by the MON cluster.
After determining that an OSD node is offline, Ceph distributes the latest OSDMap through a message mechanism to an OSD randomly. When the client (peer OSD) processes IO requests and finds that its OSDMap version is too low, it will request the latest OSDMap from MON. The other two copies of the PG in each OSD may be in any OSD in the cluster. Through a period of propagation, eventually, all the OSDs in the entire cluster will receive the update of OSDMap.
- Determine the data affected by the failure
The maintenance of object data in Ceph is responsible by PG (Placement Group). As the smallest data management unit in Ceph, PG directly manages object data, and each OSD manages a certain number of PGs. When the client has an IO request for object data, it is evenly distributed among various PGs according to the hash value of the object ID. PG maintains a PGLog to record the data changes of this PG, and these records are persisted and recorded in the backend storage.
PGLog records the data of each operation and the version of PG, and each data change operation will cause the version of PG to increment. By default, PGLog saves 3000 records, and PG will trigger Trim operations periodically to clean up extra PGLog. Generally speaking, the PGLog in the same PG of different replicas should be consistent. After a failure occurs, the PGLog of different replicas may be in a state of inconsistency.
After receiving the OSDMap update message, the OSD will scan all PGs under the OSD, clean up the PGs that no longer exist (such as those that have been deleted), initialize the PG, and if the PG on this OSD is the primary PG, the PG will perform a Peering operation. During the peering process, the PG will check the consistency of multiple replicas based on PGLog, and try to calculate the data missing in different replicas of the PG, finally obtaining a complete list of missing objects to be used as a basis for subsequent Recovery operations. For PGs that cannot calculate lost data based on PGLog, it is necessary to recover by copying the entire data of the PG through Backfill operations. It should be noted that before the Peering process is completed, the data of the PG are unreliable, and therefore, the PG will pause all client IO requests during the Peering process.
- Recover affected data
After peering is completed, the PG enters the Active state and marks itself as Degraded/Undersized based on the replica status of the PG. In the Degraded state, the number of logs stored in PGLog will expand to 10,000 records by default, providing more data records for easy data recovery after the replica node goes online. After entering the Active state, the PG becomes available and starts to accept data IO requests, and decides whether to perform Recovery and Backfill operations based on the peering information.
The primary PG will copy the data of specific objects based on the missing list of objects. For data missing in replica PG, the primary will push the missing data through the Push operation, and for data missing in primary PG, it will obtain the missing data through the Pull operation from the replicas. During the recovery process, the PG will transfer objects of complete 4M size. For those that cannot rely on PGLog for recovery, the PG will perform Backfill operations to make a full copy of the data. After the data of all replicas is fully synchronized, the PG is marked as Clean status, and the replica data remains consistent, indicating that the data recovery is complete.
The process of handling faults through Ceph allows us to see how Ceph deals with common issues in cluster failures. Firstly, it reduces resource consumption: in cases of power failure and restart, Ceph can only recover changed data, thus reducing the amount of data to be recovered; on the other hand, MON does not actively push cluster status to all OSDs, but instead adopts the method of OSD actively fetching the latest OSDMap to prevent sudden traffic in large-scale cluster failure scenarios.
Additionally, since the Ceph IO process must go through the Primary PG, once the OSD where the Primary PG is located fails, IO will not be able to proceed normally. To ensure that the normal business IO is not interrupted during the recovery process, MON will allocate PG Temp to temporarily handle IO requests, and then remove the PG Temp after the data recovery is completed. At the same time, throughout the recovery process, Ceph also allows users to adjust the number of recovery threads, the number of concurrent recovery operations, and the priority of data network transmission and other related parameters through the configuration file to limit the recovery speed, thereby reducing the impact on normal business.
However, in this case, because it involves the loss of metadata, the above conventional fault handling procedures are not applicable, and a professional Ceph data recovery solution needs to be used:
(1) Backup the current Ceph cluster state
To prevent new problems from occurring during the data recovery process, we first backed up the current state of the Ceph cluster:
# ceph tell mon.* backup
(2) Analyze the Ceph logs
By analyzing the Ceph logs, we found the detailed process of mistakenly deleting the configuration files. Since the Ceph logs record detailed operation records, we were able to determine the specific time point of the erroneous operation.
(3) Restore metadata: The metadata retained in the Ceph storage system may contain some content of the original configuration files. By analyzing the metadata, some key configuration information can be recovered.
(4) Rebuild the configuration file
According to the logs, metadata, and remaining configuration files, we manually rewritten the configuration files and tried to recover some configuration information. However, due to the deletion of key configuration files, some information could not be fully recovered.
(5) Manually scan the storage pool
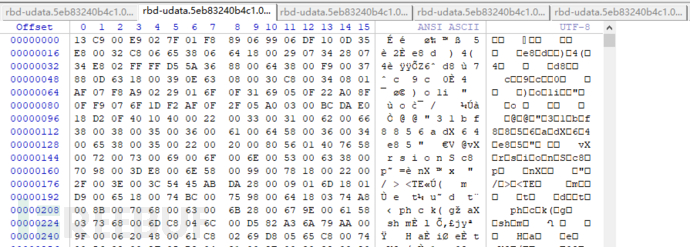
In order to retrieve lost data, we manually extracted all files from the server hard disk in accordance with the ceph distributed file storage method. After analyzing the naming method of the files, we parsed out the combination method of the file disk volumes, and found that the files in the same group of file disk volumes all have the same ID (for example, 5eB83240b4c1). We then classified all files in the same group of file disk volumes into a unified folder and made naming marks. Continuing to analyze the files in the marked folder, we found that the file sequence IDs are not continuous after sorting the files by the sequence ID. By analyzing the data structure between the file sequence IDs, we determined that the missing part of the file sequence ID is the file blocks that are all zeros in the file disk volume, and manually completed the combination of the file disk volume. We then checked whether the combined file disk volume is complete, and if there were any errors, we continued the previous operation. If there were no errors, we manually extracted and recovered the data.

(6) Reconfigure the Ceph cluster
Based on the recovered data, we have reconfigured the Ceph cluster. After the Ceph cluster has returned to normal, we have reconfigured KVM virtualization to ensure that virtual machines can use Ceph distributed storage normally.
(7) Test and verify
After the recovery is completed, a comprehensive test is conducted to ensure that all virtual machines can start normally, and the storage system can read and write data normally, mainly through the following three steps:
Configuration check: Use the command-line tools provided by Ceph to check the configuration status of the cluster, ensure that all configuration items have been correctly restored;
Data consistency verification: Run data consistency verification tools to verify whether the data in the Ceph cluster is complete and intact.
Performance testing: Conduct a series of read and write performance tests to evaluate whether the performance of the restored Ceph cluster meets business requirements. After verification, the storage pool has returned to normal, and business operations have not been affected.
Four: Case Summary
After a tense and orderly work, our technical team finally successfully restored the configuration files of the Ceph distributed storage server cluster and ensured the stable operation of the entire system environment. Although this incident was thrilling, it also brought valuable experience and lessons:
- Strengthen backup management: Ensure the establishment of a sound backup mechanism, regularly backup the key configuration files and data of the Ceph cluster, ensure the integrity and availability of backups, and prevent unforeseen events.
- Enhance security awareness: Reasonably set administrator permissions, strengthen the security education and training of operation and maintenance personnel, improve their operation and maintenance capabilities and data protection levels, and reduce the probability of human errors.
- Improve emergency response plans: Establish standardized operational procedures, continuously improve and optimize emergency response plans, and ensure rapid and effective response in emergencies.
- Strengthen monitoring and log analysis: Enable log audit function, record all operations of administrators, facilitate traceability and troubleshooting, and make full use of monitoring systems and log analysis tools to detect and handle potential problems in a timely manner.
Ceph is a highly popular open-source distributed storage system at present, featuring high scalability, high performance, high reliability, and other advantages. It also provides block storage services (rbd), object storage services (rgw), and filesystem storage services (cephfs). It is also the mainstream backend storage for OpenStack, closely related to OpenStack as brothers, providing unified shared storage services for OpenStack. Using Ceph as the backend storage for OpenStack has the following advantages:
All computing nodes share storage, and there is no need to copy the root disk during migration. Even if a computing node fails, the virtual machine can be immediately started on another computing node (evacuate).
Using the COW (Copy On Write) feature, when creating a virtual machine, it is only necessary to clone the image based on it, without the need to download the entire image, and the clone operation is almost zero cost, thus achieving the creation of virtual machines in seconds.
Ceph RBD supports thin provisioning, which means allocating space on demand, somewhat similar to the sparse files of the Linux file system. When creating a 20GB virtual hard disk, it does not occupy physical storage space at first, but only when data is written, storage space is allocated on demand.
What is the difference between OpenStack and KVM? Although OpenStack and KVM both belong to the category of cloud computing technology, they have different concepts. Simply put, OpenStack is an open-source cloud computing management platform project, composed of multiple main components, which can be used to deploy and manage various resources in cloud computing platforms; while KVM (Kernel-based Virtual Machine) is an open-source virtualization technology based on the Linux kernel, which can convert the Linux kernel into a super virtual machine monitor.
The relationship between OpenStack and KVM: OpenStack is a cloud management platform that itself does not provide virtualization functions, with the actual virtualization capabilities provided by the underlying Hypervisor (such as KVM, Qemu, Xen, etc.). OpenStack can manage the KVM virtualization environment. KVM can help you transform Linux into a virtual machine monitor, enabling the host computer to run multiple isolated virtual environments, that is, virtual clients or virtual machines (VMs). It is a currently popular virtualization solution, such as many foreign hosts are based on KVM virtualization. Hypervisor software like KVM actually provides a virtualization capability, simulating CPU operation, which is more at the bottom level. However, its user interaction is not good, and it is not convenient to use. Therefore, to better manage virtual machines, a cloud management platform like OpenStack is needed.
When data is lost, the Haicheng Super Backup research and development team delves deeply into various server and system design ideas, carefully compares fault categories, overcomes difficult recovery cases, summarizes successful recovery experience, and has more than ten thousand difficult cases related to data center such as server database, virtualization platform, and distributed storage. It also masters the core technology of ransomware recovery, ensuring that all recovered data is not lost, with complete structure, ready for direct use, and without errors.

评论已关闭