1 Introduction
In our daily work, we will encounter some slow SQL. When analyzing these slow SQLs, we usually look at the execution plan of SQL to verify whether the index is used during the execution of SQL. We usually adjust some query conditions and add necessary indexes to improve the execution efficiency of SQL by several orders of magnitude. Have we ever thought about why adding an index can improve the query efficiency of SQL, and why sometimes adding an index does not change the SQL execution? This article will analyze the underlying data structure and algorithm of MySQL index in detail.
2 Comparison of Index Data Structures
The definition of index: Index (Index) is a sorted data structure that helps MySQL efficiently retrieve data.

There are several common data structures in the index:
- Hash Table
- Binary Tree
- Red-Black Tree
- B-Tree
- B+Tree
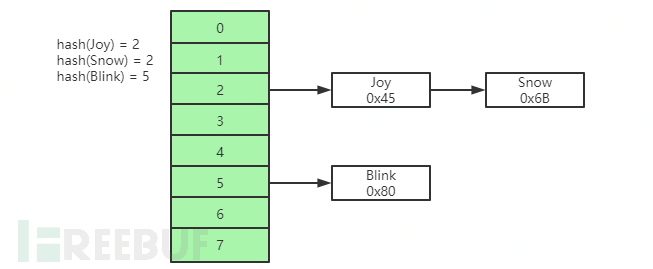
Hash Table
By performing a hash calculation on the key of the index, the disk file pointer can be quickly obtained, which is very fast for specific index file lookup, but it does not support range lookup, and sometimes there may be hash conflicts.
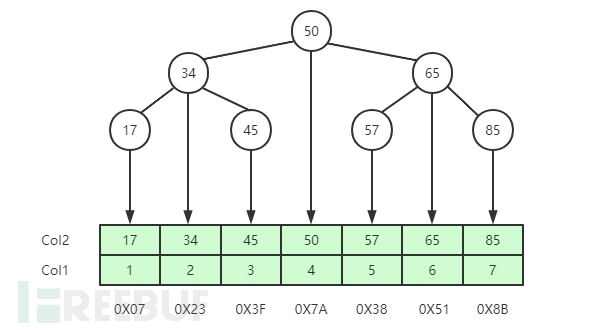
Binary Tree
The characteristics of a binary tree are: the data of the left child node is less than that of the parent node, and the data of the right child node is greater than that of the parent node. As shown in the figure below, if col2 is the index, to find the row element with the index 65, it only takes two searches to get the disk pointer address of the row element.
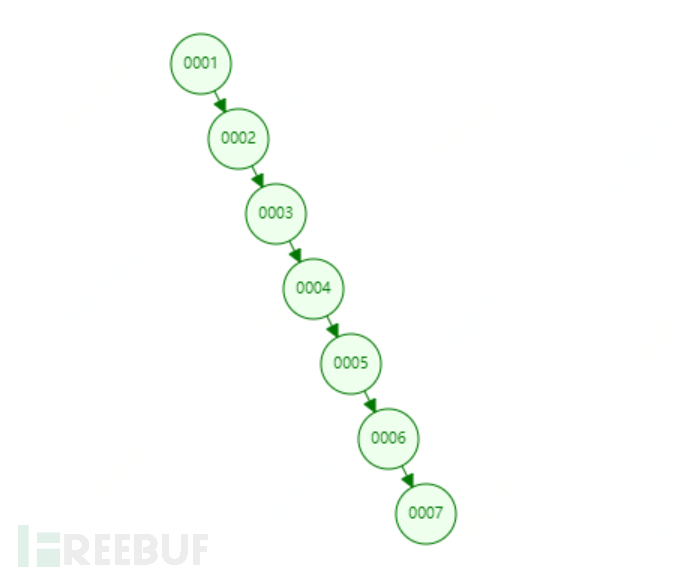
But if it is a value that increases in order, for example, to establish an index for col1, it is no longer suitable to use a binary tree to establish an index. Because at this time, using a binary tree to establish an index will become a linked index. The index structure is shown in the figure below. It takes 6 traversals to find the 6th node.
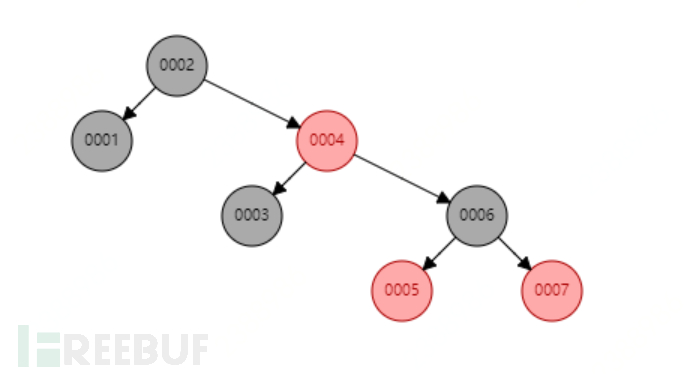
Red-Black Tree
Red-Black Tree is a binary balanced tree that can improve query efficiency. At this point, if you need to find the 6th node, it only takes 3 traversals to find it. However, Red-Black Tree also has its disadvantages. When storing large amounts of data, the height of the tree becomes uncontrollable. The larger the amount of data, the higher the height of the tree, and the query efficiency will be greatly reduced.
B-Tree
B-Tree is a multi-way binary tree with the following characteristics: 1. Leaf nodes have the same depth and their pointers are empty; 2. All index elements are unique; 3. The data index in the node is arranged in ascending order from left to right.
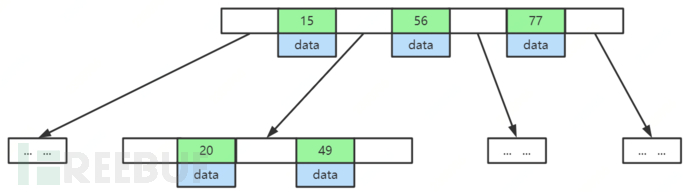
B+Tree
B+Tree is a variant of B-Tree, with the following characteristics: 1 Non-leaf nodes do not store data, only store index (redundant), which can hold more indexes; 2 Leaf nodes contain all index fields; 3 Leaf nodes are connected by pointers to improve the performance of interval access.

Compared with red-black tree, both B-Tree and B+Tree data structures are more short and fat, and have fewer levels when storing the same level of index data.
A significant difference between B-Tree and B+Tree is that B+Tree does not store value on the node, only store key, while the leaf node stores all the key-value set, and the nodes are ordered. The advantage of this is that each disk I/O can read more nodes, that is, the degree (Max.Degree) of the tree can be set larger, because the number of disk pages read each time is fixed. For example, each disk I/O can read 1 page = 4kb, then by omitting the value, the same page of data can read more keys, which greatly reduces the number of disk I/O operations.
In addition, B+Tree is also a sorted data structure, and the database can directly rely on this feature for > < or order by, etc.
In MySQL, the main data structure used for indexing is also B+Tree, the purpose of which is to reduce disk I/O when reading data.
How to use B+Tree index to quickly find 30 million level data
MySQL officially imposes a size limit on non-leaf nodes (such as the top-level node h = 1, with a B+Tree height of 3), the maximum size is 16K, which can be queried through the following SQL statement, of course, this value can be adjusted. Since the official has given this threshold, it means that if it is larger, it will affect the disk I/O efficiency.
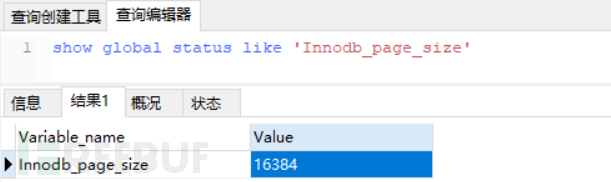
From the execution results, it can be seen that the size is 16384, which is 16K in size.
Suppose: All B+Tree tables are full. The type of primary key index is BigInt, with a size of 8B, and the pointer stores the file address of the next node, with a size of 6B. In the last layer, if the data data stored is 1K in size, then
- The maximum number of nodes in the first layer is: 16k / (8B + 6B) ≈ 1170 (nodes);
- The maximum number of nodes in the second layer should also be: 1170 nodes;
- The maximum number of nodes in the third layer is: 16K / 1K = 16 (nodes).
Therefore, a B+Tree table can store up to 1170_1170_16 ≈ 20 million.

Therefore, through analysis, we can conclude that B+Tree structured tables can accommodate queries with millions of data. Moreover, generally speaking, MySQL will place the root node of B+Tree in memory, which only requires two disk I/O operations.
4 Storage Engine Index Implementation
Where is the index stored in MySQL? Like the data itself, the index is stored in files on the hard disk.
In the MyISAM storage engine, data and index files are stored separately, data is stored in .MYD files, and indexes are stored separately in .MYI files.

In InnoDB, data and index files are stored together, note that there is no .MYI file ending in the figure below, only one .ibd file ending.

MyISAM indexes and data files are separated (non-clustered), and the storage methods of primary key indexes and auxiliary indexes (secondary indexes) are the same.
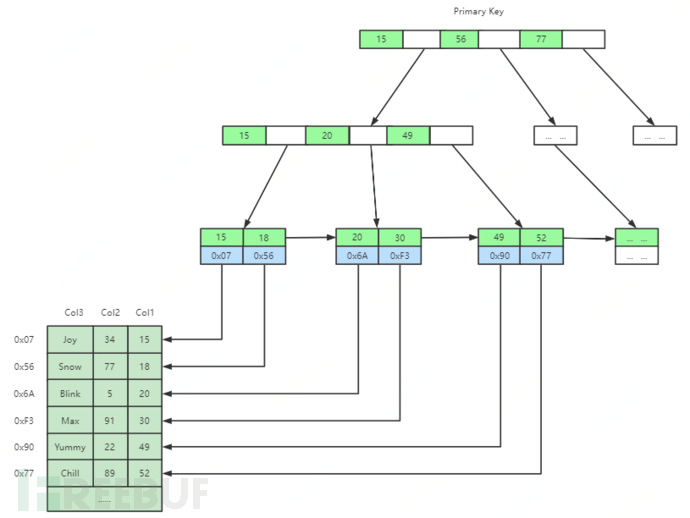
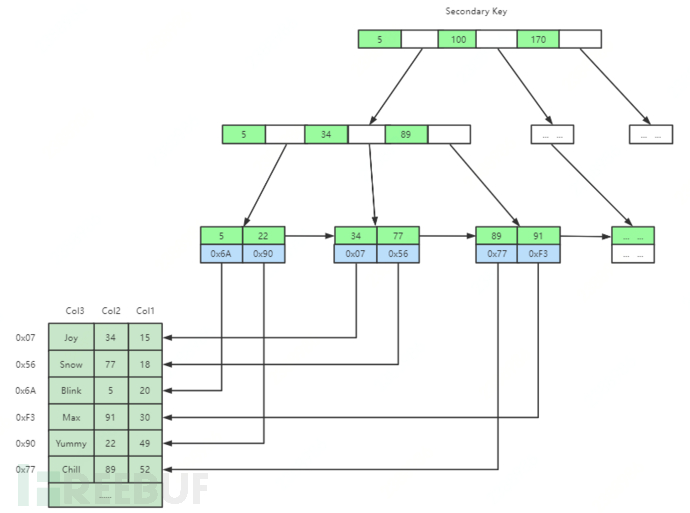
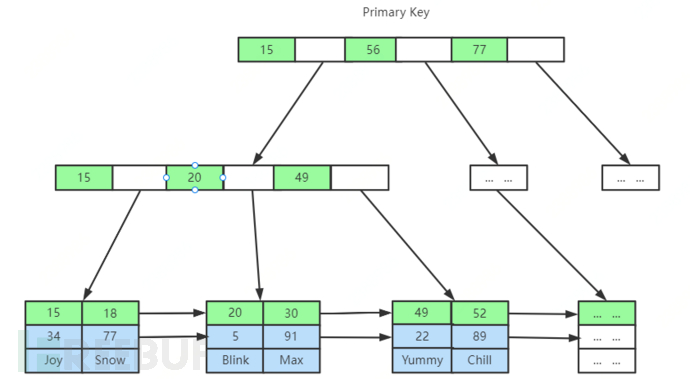
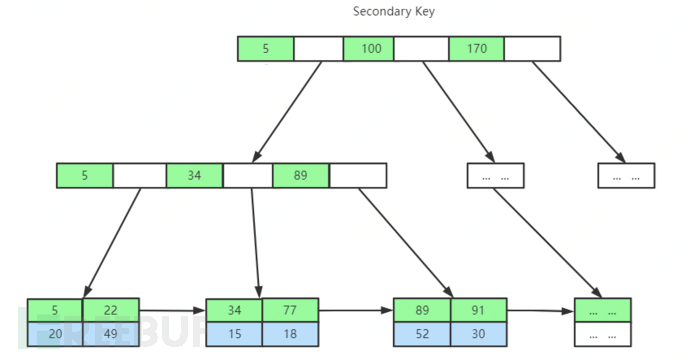
InnoDB indexes and data files are the same file (clustered), and the storage methods of primary key indexes and secondary indexes are different, as shown in the figure, the leaf nodes of secondary indexes do not store data, only storing the primary key ID.
Here are some questions to think about:
- Why is it recommended that the InnoDB table must have a primary key, and it is recommended to use an integer auto-increment primary key?
- Why do the leaf nodes of the non-primary key index structure store the primary key values?
If we do not set the primary key when creating the table, InnoDB will automatically help us select a column that does not repeat from the first column as the primary key. If such a column cannot be found, a hidden column (rowid) will be created as the primary key, which will increase a lot of work for MySQL, so it is recommended that we set the primary key when creating an InnoDB table.
An integer field as the primary key, on the one hand, does not need to be converted during data comparison, and on the other hand, it is also more space-saving. Why emphasize the auto-increment of the primary key? If the primary key id is unordered, then it is very likely that the new inserted value will cause the current node to split, at this time, MySQL has to move the data to the appropriate position to insert the new record, and even the target page may have been written back to disk and cleared from the cache, and then it has to be read back from the disk, which adds a lot of overhead. At the same time, frequent moving and pagination operations cause a large number of fragments, resulting in an index structure that is not compact enough, and it is necessary to rebuild the table and optimize the filling of pages through OPTIMIZE TABLE. Conversely, if the insertion is ordered every time, it will be written continuously behind the current page, and a new node will be allocated if it is not enough. The memory is continuous, so the efficiency is naturally the highest.
The leaf nodes of non-primary key indexes store the primary key values instead of all the data, mainly for consistency and to save space. If the secondary index also stores data, then every time MySQL inserts, it has to update every index tree, which would increase the performance overhead of adding and editing, and in this way, the space utilization is also not high, which inevitably generates a large amount of redundant data.
What is the underlying data structure of a composite index?
A composite index, also known as a multi-column index, for example, the following table:
CREATE TABLE `test` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL,
`age` int NOT NULL,
`position` varchar(32) NOT NULL,
`address` varchar(128) NOT NULL,
`birthday` date NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
The following index is a composite index.
`idx_name_age_position` (`name`,`age`,`position`) USING BTREE
What does the underlying data structure of the composite index look like?
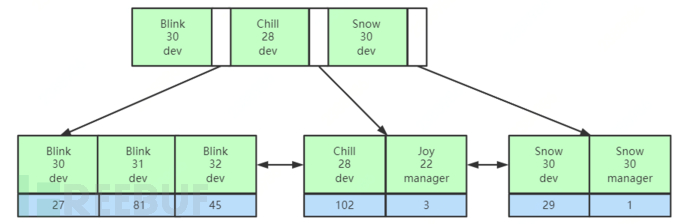
When comparing for equality, the value of the first column is compared first, and if equal, the second column is continued to be compared, and so on.
After understanding the storage structure of the composite index, we know what the index left prefix optimization principle is all about. When using a composite index, the definition order of the index columns will affect the use of the index during the final query. For example, in the composite index (name, age, position), MySQL will match from the leftmost column first. If the name, the leading brother at the leftmost, is not used, and there is no use of a covering index, a full table scan can only be performed.
Joint underlying data structure thinking: MySQL will match the first column of the composite index first, and then match the next column. If the value to be matched by the first column is not specified, it is also impossible to know which node to query next.
6 Summary
Indexes are essentially a sorted data structure. Understanding the underlying data structure and storage principles of MySQL indexes can help us better optimize SQL. In fact, database index optimization is a technical task, not just relying on theory, because the actual situation is ever-changing, and MySQL itself has very complex mechanisms, such as query optimization strategies and the implementation differences of various engines, which will make the situation more complex. At the same time, these theories are the basis of index optimization. Only on the basis of understanding the theory, can we make reasonable inferences on optimization strategies and understand their underlying mechanisms, and then combine continuous experiments and exploration in practice, thus truly achieving the purpose of efficient use of MySQL indexes.
Finally, if everyone wants to review the knowledge of data structures again, this data structure website (https://www.cs.usfca.edu/~galles/visualization/Algorithms.html)Not to be missed, it can help us demonstrate the storage process of data structures very well.
Author: JD Logistics Yu Shuo
How to use TikTok Scraper to quickly collect user-posted video data
From Akamai, we can see how to quickly recover from a large-scale outage of cloud services
Flexible, quick, and low-maintenance cost data integration method: Data Federation Architecture
2.1. Obtain the password of the optical network terminal super administrator account (telecomadmin)

评论已关闭