101 for web technology reconnaissance in corporate security SDLC
This article is suitable for SDLC security development, web testing, penetration testing, and exploitation development.
Today's web is an aggregate of new technologies and applications, introducing more security issues and testing techniques ------ sec875
[This article belongs to the first part: Technical Reconnaissance]
These knowledge will help you discover more tests that scanning tools cannot complete, replace online POCs, use your own scripts for secure testing, [Part Two: Detection]. Help developers, familiarize themselves with web security knowledge, and develop with secure architecture and thinking, in [Part Three: Defense].
This article introduces a complex set of reference materials, and the general reference materials are as follows:
Materials from Twitter UPs, youyu bi UPs, and recommended materials, as well as the external links of the external links.
tryhackme scenarios
O'Reilly published 'Web Application Security'
Materials encountered by Google arbitrarily
Prerequisites
We need a basic understanding of enterprise-level application system development, such as Java EE
We need a basic understanding of web security and penetration testing
We need observation. We need to go to the official website to do data association. We need to translate English words.
We need to treat English sensually: nouns (call it whatever dinosaur) andVerbs(Attention increased by 200%): Wang Yin's 'Deciphering English Grammar'
http://www.yinwang.org/blog-cn/2018/11/23/grammar
Awareness and cognition
It is common for penetration testers to operate using various pre-built vulnerability exploitation scripts.
These scripts or initial conditions may be incorrect, toxic, incomplete, defective, or even a decoy.
Various factors and needs indicate that someone needs to build exploitation scripts, identify exploitation scripts, and check exploitation scripts.
When I find web security vulnerabilities, can I simply use my own POC (Proof of Concept) to verify them?
After the automated collection tool collects the data back, it still requires you to judge which data is valid.
The more development knowledge we have, the more information we can侦察. Otherwise, there is no way to further collect information. Less vulnerabilities are found.
Observation, bypassing conventional defenses.
Web application reconnaissance
Simple reconnaissance only requires browsing the web application and recording network requests, starting from each functional point on the homepage. Registration, login, captcha, password reset?
We should assume that we can only access a subset of the user interface. What parameters are used to locate other user interfaces? Horizontal and vertical privilege escalation? What parameters represent ourselves? Finding this can also indicate that, by tampering with it, it can become someone else's.
CRUD (Create, Read, Update, Delete)? Role-based access control?
Can I test vulnerabilities related to authentication and authorization?
Think about each functional point from a macro perspective. My test account itself represents the team leader, can checking the information of my team members be considered a vulnerability?
We can often find APIs. They are compared with the permissions set by other users.
If we have the appropriate skills in reverse engineering structure, we do not need a user interface to understand how the application runs its API and what payloads these APIs accept.
Network application mapping
Browsing the source code, js files, and recording all endpoints such as APIs. For specific implementation, please refer to: https://shubs.io/
The structure of modern web applications
Introducing a large number of individual programs that work independently but are combined into a web application aggregate through APIs.
Modern and traditional web applications
Ten years ago, most web applications were presented using server-side frameworks for HTML/JS/CSS pages. The client simply updates through HTTP requests.
Not long after that, with the rise of Ajax (Asynchronous JavaScript and XML), web applications more frequently use HTTP, allowing network requests to be made from page sessions through JavaScript.
Today, two or more applications communicating through network protocols. This is the main architectural difference between today's web applications and web applications ten years ago.
Connecting multiple applications through (REST) APIs. These APIs are stateless. They actually do not store any information about the requesters.
Client programs running in the browser request their own data, and do not need to reload the page after the initial boot is complete.
It is not uncommon for independent applications deployed to web browsers to communicate with multiple servers.
Today's applications are actually usually a combination of many independent but symbiotic applications working together. You can privately call it web 3.0.
node.js allows JavaScript to run on the server side without the need for backend programming languages such as PHP.
Modern web applications may use the following technologies:
Modern web applications may use the following technologies: REST API, JSON or XML, JavaScript, SPA framework (React, Vue, EmberJS, AngularJS), authentication and authorization systems, multiple servers, multiple web server software packages (ExpressJS, Apache, NginX), various databases (MySQL, MongoDB, etc.), local data storage on the client (cookies, Web storage, IndexedDB)
Other technologies to refer to: Stack Overflow, other books, etc.
There are also cache APIs for local storage requests, as well as Web sockets for communication from the client to the server (even client to client). Browsers intend to fully support assembly code variants called Web Assembly, allowing client code to be written in non-JavaScript languages within the browser.
From the perspective of historical development, every new technology brings new attention to hacker activities. Therefore, in addition to traditional web security vulnerabilities, new web vulnerabilities are constantly emerging.
REST APIs
Representational State Transfer: Representational State Transfer, accessing resources
REST APIs aim to build highly scalable web applications. Separate the client from the API, but follow a strict API structure, so that client applications can easily request resources from the API without calling the database or executing server-side logic itself.
https://en.wikipedia.org/wiki/Representational_state_transfer
In short: when a user accesses http://www.example.com/articles/21 and 20, the surface, appearance, and page are all different. Different resources are obtained, and this is called REST API.
The number 21 is used to represent state transitions. REST APIs can be as simple as this URL. But they can also be very complex in their setup: based on URI, based on HTTP methods, based on HTTP media types, etc.
REST APIs do not have an official standard, it seems that people do not call APIs based on standards and definitions very painfully, although not strict, they are very clever to treat all APIs as RESTful, implementing with HTTP, URI, JSON, and XML.
This does not mean that REST APIs cannot perform authentication and authorization - on the contrary, authorization should be tokenized and sent with each request.
Each endpoint can define a specific object or method
/moderators/joe/logs/12_21_2018 with GET, POST, PUT, and DELETE
Modify moderator account? : PUT /moderators/joe
Delete log file? : DELETE /moderators/joe/logs/12_21_2018
Each state transition combination represents a large amount of information, tools like Swagger can easily be integrated into applications and record endpoint information.
Swagger, an automatic API documentation generator, designed to integrate with REST APIs easily
In the past, most web applications used APIs with the simple object access protocol (SOAP) structure. Compared to SOAP, REST has several advantages:
Request target data instead of functions; easily cache requests; highly scalable
SOAP APIs must use XML data format, but REST APIs can accept any data format, usually JSON. Compared to XML, JSON is lighter and easier to read, which also gives REST an advantage in competition.
Observe the representation methods of both, and it is evident that JSON is concise.

Most modern web applications either use RESTful APIs or use class REST APIs that provide JSON. In summary, the current situation uses REST APIs.
REST API vulnerabilities: https://www.youtubepro.com/watch?v=YPzMTKsBMnI
JavaScript Object Notation
Easily convert JSON to a JavaScript object.
REST is an architectural specification that defines how HTTP verbs map to resources on the server (API endpoints and functions). Today, most APIs use JSON as their data transport format.
The following JSON:
{
"first": "Sam",
"last": "Adams",
"email": "sam.adams@company.com",
"role": "Engineering Manager",
"company": "TechCo.",
"location": {
"country": "USA",
"state": "california",
"address": "123 main st.",
"zip": 98404
} }
It can be easily parsed into a JavaScript object in the browser:
const jsonString = `{
"first": "Sam",
"last": "Adams",
"email" "sam.adams@company.com",
"role": "Engineering Manager",
"company": "TechCo.",
"location": {
"country": "USA",
"state": "california",
"address": "123 main st.",
"zip": 98404
}
}`;
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse
// JSON.parse() parses the JSON string into a JavaScript object
const jsonObject = JSON.parse(jsonString);
Familiarize yourself with reading JSON strings, which means you need to translate JSON words in combination with actual functional points, grasp the meaning of each field, and put the payload in to see what kind of reaction it elicits. It is very valuable to be able to quickly parse these and find specific information when conducting penetration testing on various APIs in a short period of time.
JavaScript
Today's web servers run on top of languages such as Python, Java, JavaScript, C++, and more. JavaScript is not only a programming language but also the only programming language for client-side scripts in web browsers. It even runs on IoT devices.
Variables and scope
In ES6 JavaScript (latest version), there are four ways to define variables:
// global definition Global variable
age = 25;
// function scoped Function scope
var age = 25;
// block scoped Block scope
let age = 25;
// block scoped, without reassignment Block scope, cannot be assigned
const age = 25;
Block, code block:
Ding ding ding {
Ding ding ding.... This is a code block
}
Function scope
const func = function() {
if (true) {
// code block
var age = 25; } # The scope of var is defined as function rather than block
console.log(age); # Returns 25, not function scope, returns undefined
};
ECMAScript 6 (JavaScript specification) introduced let and const — twoInstantiating an objectIn the way, their behavior is more similar to that of modern languages.
Generally, you should always strive to use let and const in your code to avoid errors and improve readability.
let age = 25; Block scope, what does it mean that it cannot be assigned anything? It means that it can no longer be assigned a new memory address.
Instantiating an object involves creating a new memory address pointing to it; otherwise, how can it be instantiated? It cannot be assigned to represent it, and it cannot be assigned a memory address value again. Assignment is the instantiation of an object.
FunctionsFunctions
In JavaScript, functions are objects. They can be assigned and reassigned using variables and identifiers.
These are functions
// anonymous function
function () {};
// globally declared named function
a = function() {};
// function scoped named function
var a = function() { };
// block scoped named function
let a = function () {};
// block scoped named function without re-assignment
const a = function () {};
// anonymous function inheriting parent context
() => {};
// immediately invoked function expression (IIFE)
(function() { })();
The first function is an anonymous function—this means it cannot be referenced after creation. The next four are functions that specify scope based on the provided identifier. This is very similar to the way we created variables for age before. The sixth function is a shorthand function—it shares the context with its parent function (to be introduced in more detail later). The last function is a special type of function that you may only find in JavaScript, called an immediately invoked function expression. A function that is triggered immediately when loaded and runs in its own namespace.
ContextContext
A philosophical thinking: In our daily life, we sayR Flashorfull screen 'getshell'. The context of 'R Flash' comes from League of Legends, and the full screen 'getshell' comes from the context story of another joke. These phenomena are called:Context.
To become an excellent JavaScript developer, you need to learn five things: scope, context, prototype inheritance, asynchronous, and browser DOM.
Every function in JavaScript has its own set ofpropertiesand itsData. This is called the context of these functions.
You can use the keyword this to refer to the object stored in the function context:
const func = function() {
this.age = 25;
// will return 25
console.log(this.age);
};
// will return undefined
console.log(this.age); # To someone who has never played League of Legends, saying 'R Flash, R Flash' must be undefined
Many programming errors are caused by the difficulty of debugging context—especially when the context of certain objects must be passed to another function. JavaScript has introduced some solutions to help developers share context between functions:
// create a new getAge() function clone with the context from ageData
// then call it with the param 'joe'
const getBoundAge = getAge.bind(ageData)('joe'); #The same function getAge() and its data property with ageData are definitely in the same context
// call getAge() with ageData context and param joe
const boundAge = getAge.call(ageData, 'joe');
// call getAge() with ageData context and param joe
const boundAge = getAge.apply(ageData, ['joe']);
Another new feature of helping context is the arrow function, also known as shorthand function. The context shared from the parent function is inherited by the child function without explicit calling/applying or binding:
// global context
this.garlic = false;
// soup recipe
const soup = { garlic: true };
// standard function attached to soup object
soup.hasGarlic1 = function() { console.log(this.garlic); } // true
// arrow function attached to global context
soup.hasGarlic2 = () => { console.log(this.garlic); } // false
Mastering these methods of managing context will make reconnaissance on servers or clients based on JavaScript easier and faster. You may even find some language-specific vulnerabilities caused by these complexities.
Prototypal inheritance
Prototypal inheritance is used only in JavaScript.
Unlike many traditional server-side languages that suggest using a class-based inheritance model, JavaScript is designed to have a highly flexible prototypal inheritance system.
Unfortunately, because this type of inheritance system is rarely used in languages, it is often ignored by developers, many of whom try to convert it into a class-based system.
Here is an example of an implicitly generated prototype object:
/*
A vehicle pseudoclass written in JavaScript.
*
* This is simple on purpose, in order to more clearly demonstrate
* prototypal inheritance fundamentals. Prototype inheritance fundamentals.
*/
const Vehicle = function(make, model) {
this.make = make;
this.model = model;
this.print = function() {
return `${this.make}: ${this.model}`;
};
};
const prius = new Vehicle('Toyota', 'Prius'); # It will also implicitly generate a separate object for __proto__
console.log(prius.print());
When any new object is created in JavaScript, a named__proto__of a separate object. The object Vehicle inherits the default prototype__proto__
This allows for comparison between objects, for example:
const prius = new Vehicle('Toyota', 'Prius');
const charger = new Vehicle('Dodge', 'Charger'); # It will also implicitly generate a separate object for __proto__, the prototype object
/*
* As we can see, the "Prius" and "Charger" objects were both
* created based off of "Vehicle".
*/
prius.__proto__ === charger.__proto__;
Generally, developers will modify the prototype of the object, which can lead to confusion in the functionality of web applications. Notably, prototype properties can be changed at any time during runtime.
Unlike the more strictly designed inheritance model, the JavaScript inheritance tree can be changed at runtime. Therefore, objects can be transformed at runtime, and the entire prototype is updated:
const prius = new Vehicle('Toyota', 'Prius');
const charger = new Vehicle('Dodge', 'Charger');
/*
* This will fail, because the Vehicle object
* does not have a "getMaxSpeed" function.
*
* Hence, objects inheriting from Vehicle do not have such a function
* either.
*/
console.log(prius.getMaxSpeed()); // Error: getMaxSpeed is not a function
/*
* Now we will assign a getMaxSpeed() function to the prototype of Vehicle,
* all objects inheriting from Vehicle will be updated in real time as
* prototypes propagate from the Vehicle object to its children.
*/
Vehicle.prototype.getMaxSpeed = function() { # Transformation: Assigning getMaxSpeed(), the entire prototype is updated
return 100; // mph
};
/*
* Because the Vehicle's prototype has been updated, the
* The getMaxSpeed function will now function on all child objects.
*/
prius.getMaxSpeed(); // 100
charger.getMaxSpeed(); // 100
Understanding prototypes is particularly important when delving into JavaScript security, as few developers fully understand them. Moreover, since prototypes propagate to their descendants upon modification, a special type of attack has been discovered in JavaScript-based systems, known as prototype pollution. This attack involves modifying the parent JavaScript object, inadvertently altering the functionality of child objects.
Prototype Pollution Vulnerability: https://www.youtubu.com/watch?v=Z6CtDSx8C5k CVE-2021-23329
asynchronous
Since browsers must communicate with servers regularly, and the time between requests and responses is not standardized (considering payload size, latency, and server processing time), asynchronous processing is often used on the Web to handle such changes.
In the synchronous programming model, operations are executed in the order they occur. For example:
console.log('a');
console.log('b');
console.log('c');
// a
// b
// c
In the asynchronous programming model, the interpreter may read these three functions in the same order each time, but may not parse them in the same order.
Example of asynchronous logging feature:
// --- Attempt #1 ---
async.log('a');
async.log('b');
async.log('c');
// a
// b
// c
// --- Attempt #2 ---
async.log('a');
async.log('b');
async.log('c');
// a
// c
// b
// --- Attempt #3 ---
async.log('a');
async.log('b');
async.log('c');
// a
// b
// c
Instead of completing requests one after another, all requests are started simultaneously
When dealing with network programming, requests often take different amounts of time, timeouts, and unpredictable operations. In JavaScript-based web applications, this is usually handled through an asynchronous programming model, rather than simply waiting for one request to complete before starting another. The benefit is significant performance improvement, which can be several tens of times faster than synchronous alternatives.
Asynchronous requests were previously done with callbacks, and now with asynchronous functions (essentially, promises).
In older versions of JavaScript, this was usually done through a system called callbacks:
const config = {
privacy: public,
acceptRequests: true
};
/*
* First request a user object from the server. # Request user
* Once that has completed, request a user profile from the server. # Request profile
* Once that has completed, set the user profile config. # Request to set profile
* Once that has completed, console.log "success!"
*/
getUser(function(user) {
getUserProfile(user, function(profile) {
setUserProfileConfig(profile, config, function(result) {
console.log('success!');
});
});
});
Although callbacks are very fast and efficient, they are difficult to read and debug compared to the synchronous model.
Later programming philosophies suggest creating a reusable object that will call the next function once the given function is completed. These are calledPromises promisesThese are used in many programming languages today:
const config = {
privacy: public,
acceptRequests: true
};
/*
* First request a user object from the server.
* Once that has completed, request a user profile from the server.
* Once that has completed, set the user profile configuration.
* Once that has completed, console.log "success!"
*/
const promise = new Promise((resolve, reject) => { # Observe here, an additional reusable object has been added
getUser(function(user) {
if (user) { return resolve(user); }
return reject();
});
}).then((user) => { # Here is the reuse
getUserProfile(user, function(profile) {
if (profile) { return resolve(profile); }
return reject();
});
}).then((profile) => { # Here is the reuse
setUserProfile(profile, config, function(result) {
if (result) { return resolve(result); }
return reject();
});
}).catch((err) => {
console.log('an error occurred!');
});
Search for it yourself, and associate data in the manual

The two previous examples have completed the same application logic. The difference lies in readability and organization. The method based on promises can be further decomposed, vertically rather than horizontally, and makes error handling easier. Promises and callbacks are interoperable and can be used together, depending on the programmer's preference.
processingasynchronousThe latest method isAsynchronous functions。 They are different from ordinary function objects and are designed to make handling asynchronous operations easy.
Consider the following asynchronous function:
const config = {
privacy: public,
acceptRequests: true
};
/*
* First request a user object from the server.
* Once that has completed, request a user profile from the server.
* Once that has completed, set the user profile configuration.
* Once that has completed, console.log "success!"
*/
const setUserProfile = async function() { # Asynchronous function
let user = await getUser();
let userProfile = await getUserProfile(user);
let setProfile = await setUserProfile(userProfile, config);
};
setUserProfile();
You may notice that it is easier to read - that's great, that's the point!
Asynchronous functionsConvert functions toPromises promisesAny method call within the promise will stop executing further within the function until the method call is resolved. Code outside of the asynchronous function can still run normally.
Essentially, asynchronous functions turn a normal function into a promise.
Browser Browser DOM
DOM usageHierarchical representation of dataManage the state of modern browsers.
DOM window objectAs shown below

JavaScript is a programming language, like any excellent programming language, it relies on a powerful standard library. Unlike standard libraries in other languages, this library is called DOM. DOM provides well-tested and high-performance routine functions and is implemented in all major browsers, so your code should have the same or almost the same functionality regardless of which browser it runs on.
Unlike other standard libraries, the existence of DOM is not to fill functional gaps in the language or to provide general functionality (i.e., the secondary functions of DOM), but mainly to provide a general interface, from which a hierarchical node tree representing the Web is defined. You may have accidentally called a DOM function and assumed it was a JS function. An example of this is document.querySelector() or document.implementation.
The main objects that make up the DOM are window and document, each object is carefully defined in a specification maintained by an organization called WhatWG.
DOM Standard: https://dom.spec.whatwg.org/
Not all security vulnerabilities related to scripts are caused by incorrect JavaScript, sometimes they may be caused by incorrect browser DOM implementations.
SPA Framework
Older websites were usually built on a combination of temporary scripts that manipulate the DOM and a large amount of reusable HTML template code. This was not an extensible model, although it was suitable for providing static content to end users, it was not suitable for providing complex, logically rich applications.
The desktop application software of that time was powerful, allowing users to store and maintain the state of applications. Past websites did not provide such functionality, although many companies preferred to deliver their complex applications through the Web, as it offered many benefits from usability to preventing piracy.
Single-page application (SPA) frameworks are designed to bridge the functionality gap between websites and desktop applications. SPA frameworks allow the development of complex JavaScript-based applications that store their own internal state and are composed of reusable UI components, each with its own self-maintaining lifecycle, from rendering to logic execution.
SPA frameworks are rife on the web today, supporting the largest and most complex applications (such as Facebook, Twitter, and YouTube), where functionality is key and provide an experience close to desktop applications.
Some of the largest open-source SPA frameworks today are ReactJS, EmberJS, VueJS, and AngularJS. These are all built on JavaScript and DOM, but they bring additional complexity from both security and functionality perspectives.
Authentication and Authorization Systems
The authentication system tells us that 'joe123' is actually 'joe123' and not 'susan1988'.
Authorization is used to describe the process within the system, used to determine what resources 'joe123' can access, rather than 'susan1988'.
Authentication Authentication
Early authentication systems. For example, HTTP basic authentication performs authentication by attaching an Authorization header to each request. The header contains Basic:<base64-encoded username:password>The string is composed of. The server receives the username: password combination and checks it against the database with each request. It is obvious that this type of authentication scheme has several flaws - for example, credentials are easily leaked in various ways, from broken WiFi through HTTP to simple XSS attacks.
Later authentication developments include digest authentication, which uses encrypted hashes instead of base64 encoding. After digest authentication, a large number of new technologies and architectures for authentication have emerged, including those that do not involve passwords or require external devices.
Today, most web applications choose from a set of authentication architectures, depending on the nature of the business. For example, the OAuth protocol is very suitable for websites that want to integrate with large websites. OAuth allows major websites (such as Facebook, Google, etc.) to provide authentication tokens to partner websites. OAuth is very useful for users because their data only needs to be updated on one site, not on multiple sites - but OAuth can be dangerous because an infiltrated website can lead to multiple compromised profiles.
HTTP basic authentication and digest authentication are still widely used today, with digest being more popular because it offers more defense against intercept and replay attacks. These are often used in conjunction with tools like 2FA to ensure that authentication tokens are not compromised and the identity of the logged-in user remains unchanged.
AuthorizationAuthorization
Authorization systems are more difficult to classify because authorization largely depends on the business logic within the Web application. Generally, well-designed applications have a centralized authorization class responsible for determining whether users can access certain resources or features.
If the API is poorly written, they will implement checks based on each API, manually mimicking the authorization function.
Typically, if you can see that the application has re-implemented authorization checks in each API, then the application is likely to have multiple APIs, which are insufficiently checked due to human error.
Some common resources that should always be authorized include setting/config file updates, password resets, reading/writing private messages, any paid features, and any enhanced user features (such as audit features).
Web Servers
Apache is open-source and has been developed for about 25 years, almost running on every Linux distribution and some Windows servers.
Apache's main competitor is Nginx. Nginx runs on about 30% of Web servers and is growing rapidly.
Although Nginx can be used for free, its parent company (currently F5 Networks) uses a paid+ model, and support and additional features require payment.
Nginx is used for high-volume applications with a large number of unique connections, as the overhead of each connection in the Nginx architecture is much lower.
Microsoft IIS, despite the decline in popularity of Windows servers due to expensive licenses and incompatibility with Unix-based open-source software (OSS) packages, is the correct choice for Web servers when dealing with many Microsoft-specific technologies. However, for companies trying to build on open-source platforms, it may be a burden.
Server-side database
Once the data to be processed by the client is sent to the server, the server usually must retain these data so that they can be retrieved in future sessions. In the long run, storing data in memory is unreliable because restarts and crashes may cause data loss. Moreover, compared to disk, random access memory is quite expensive.
When storing data on disk, appropriate precautions need to be taken to ensure that data can be reliably, quickly retrieved, stored, and queried. Today, almost all web applications store user-submitted data in some type of database - usually changing the database used based on specific business logic and use cases.
SQL databases are still the most popular general-purpose databases on the market. The SQL query language is strict, but reliable, fast, and easy to learn. SQL can be used for everything from storing user credentials to managing JSON objects or small image blob files. The largest ones are PostgreSQL, Microsoft SQL Server, MySQL, and SQLite.
When more flexible storage is needed, schema-less NoSQL databases can be used. Databases such as MongoDB, DocumentDB, and CouchDB store information as loosely structured 'documents', which are flexible and can be modified at any time, but are not as easy or efficient in querying or aggregation.
In today's web application environment, there are also more advanced and specific databases. Search engines typically use their highly specialized databases, which must be synchronized with the main database regularly. An example of this is the widely popular Elasticsearch.
Each type of database comes with its own unique challenges and risks. SQL injection is a well-known vulnerability pattern, which can effectively target major SQL databases when queries are not formed correctly. However, if hackers are willing to learn the query model of the database, almost any database can be subject to injection attacks.
It is wise to consider that many modern web applications can and often do use multiple databases simultaneously. Applications that may have sufficient secure SQL queries may not have sufficiently secure MongoDB or Elasticsearch queries and permissions. This is an additional layer of security on queries and permissions.
Client Data Storage
Traditionally, due to technical limitations and cross-browser compatibility issues, the least amount of data is stored on the client. This is changing rapidly. Many applications now store important application states on the client, usually in the form of configuration data or large scripts, which could cause network congestion if they had to be downloaded each time.
In most cases, a browser-managed storage container called local storage is used to store and access key/value data from the client. Local storage follows the browser-enforced same-origin policy (SOP), which prevents other domains (websites) from accessing each other's local storage data. Even if the browser or tab is closed, the web application can maintain its state in local storage.
The operations of the local storage subset called session storage are the same, but the data is only retained before the tab is closed. This type of storage can be used when data is more critical, and it should not be retained if another user uses the same machine.
The operations of the local storage subset called session storage are the same, but the data is only retained before the tab is closed. This type of storage can be used when data is more critical, and it should not be retained if another user uses the same machine.
In poorly architected web applications, client data storage may also leak sensitive information, such as authentication tokens or other secrets.
Finally, for more complex applications, all major web browsers today provide browser support for IndexedDB. IndexedDB is an object-oriented programming (OOP) database based on JavaScript, which can asynchronously store and query data in the background of web applications.
Because IndexedDB is searchable, it provides a more powerful developer interface than local storage. IndexedDB can be used for web-based games and interactive web applications (such as image editors).
You can check if your browser supports IndexedDB by typing the following content into the browser's developer console:if (window.indexedDB) { console.log('true'); }.
Subdomain
Multiple applications on each domain
Subdomain enumeration is about finding: whether other services based on the main domain are hosted or named in other subdomains. If you also find other irregularly named services or those with no relation to the main site, you should consider what's going on. Did the developers secretly leave an interface? Is it a legacy issue? Did a department handover lead to a mistake?
Suppose we are trying to map MegaBank's web application to better perform the black-box penetration testing sponsored by the bank. We know that MegaBank has an application that users can log in to and access their bank accounts. This application is located at https://www.megabank.com.
We are particularly curious whether MegaBank has any other internet-accessible server links to the megabank.com domain. We know that MegaBank has a bug bounty program, which covers the main megabank.com domain quite comprehensively. Therefore, any easily discovered vulnerabilities in megabank.com have been fixed or reported. If new vulnerabilities arise, we will strive to find them before the bug bounty hunters.
Therefore, we want to look for some easier targets that still allow us to hit MegaBank where it is vulnerable. This is a purely sponsored ethical test by enterprises, but it doesn't mean we can't have fun.
The first thing we should do is conduct some reconnaissance and fill our web application map with the list of subdomains attached to megabank.com. Since www points to the public-facing web application itself, we may not be interested in it. However, most large consumer companies actually own various subdomains associated with their main domain. These subdomains are used to host a variety of services from email to management applications, file servers, and more.

Built-in browser network analysis tools
Initially, we can simply collect some useful data by viewing the visible features in MegaBank and checking the API requests sent from the background. This usually gives us some easy-to-implement results. To view these requests, we can use the network tools of our own web browser, or more powerful tools such as Burp, PortSwigger, or ZAP. Such free network analysis tools are much more powerful than many paid network tools from 10 years ago.
As long as you use one of the three major browsers (Chrome, Firefox, or Edge), you will find that the development tools they come with are very powerful. In fact, browser development tools have developed to the point where you can easily become a proficient hacker without purchasing any third-party tools. Modern browsers provide tools for network analysis, code analysis, runtime analysis of JavaScript with breakpoints and file references, accurate performance measurement (which can also be used as a hacking tool in side-channel attacks), and tools for performing smaller security and compatibility audits.
For example, using Chrome:
Click the network tab
I also use Firefox to access together to observe https://www.reddit.com/
The most interesting results usually come from the XHR tab under the Network tab, which displays any HTTP POST, GET, PUT, DELETE, and other requests to the server, and filters out fonts, images, videos, and dependent files (unselected items are filtered out). You can click on any individual request in the left pane to view more details.

Click Preview to see the formatted version of the API response package.

Other features see here without listing
Leverage public records
Today, there is a large amount of information stored on the network
Look for similar content in public repositories: search engines; social media posts; archived applications, such as archive.org; image search and reverse image search
Look for content similar to the following:
• Cached copies of GitHub repositories that were unexpectedly made public before becoming private
• SSH keys
• Non-public DNS lists and URLs
• Detailed pages of unreleased products that are not intended to go online
• Financial records hosted on the network but not intended to be indexed by search engines
• Email addresses, phone numbers, and usernames
• Subdomain
Search Engine Cache
Filter out the subdomains of no interest
site:reddit.com -inurl:www
site:mega-bank.com -inurl:www -inurl:mobile
Social Media
Most people would not consider it unethical to look for subdomains for penetration testing through social media data. However, when using these APIs for more targeted reconnaissance in the future, consideration should be given to the feelings of the end users.
Use the Twitter API as an example of reconnaissance. The concepts required can be applied to any other major social media network.
Twitter API
Twitter provides many products for searching and filtering data. These products differ in scope, feature set, and dataset. This means the more data you want to access, the more ways you need to request and filter the data, and the more you need to pay. In some cases, you can even perform searches on Twitter's servers instead of locally. Remember, doing so for malicious purposes may violate the law, so this usage should be limited to authorized white hats.

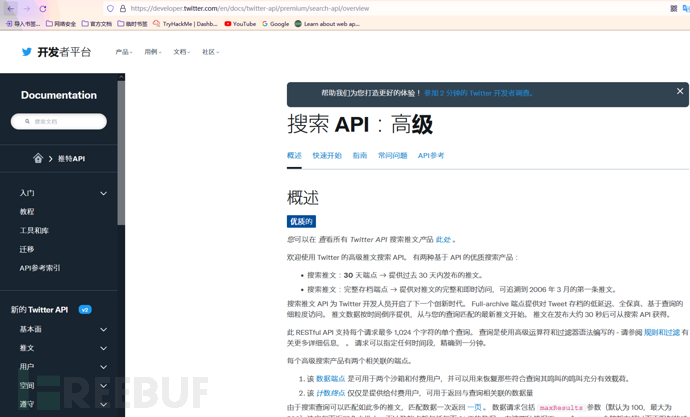
We can use this API to build a JSON that contains links to *.mega-bank.com for further subdomain reconnaissance. To query the Twitter Search API, you need:
• Registered developer account
• Registered application
• The anonymous token included in your request to verify your identity
The API query is very simple, although the documentation is scattered, lacking examples and difficult to understand:
curl --request POST \
--url https://api.twitter.com/1.1/tweets/search/30day/Prod.json \
--header 'authorization: Bearer <MY_TOKEN>' \
--header 'content-type: application/json' \
--data '{
"maxResults": "100",
"keyword": "mega-bank.com"
}
By default, the API performs a fuzzy search for keywords. For an exact match, you must ensure that the string being transmitted is enclosed in double quotes (using\The double quotes can be escaped in the following form through valid JSON:
"keyword": "\"mega-bank.com\""
Why might the results of this API lead to the discovery of previously unknown subdomains? These are usually services on different servers than the main application, such as advertising trackers, even recruitment activities, and other commercial interests, leaving information behind due to intersections.
Zone Transfer Attacks
You can translate it as: zone transfer, transfer, transmission attack
Browsing public-facing web applications and analyzing network requests will only get you so far. We also want to find subdomains attached to MegaBank that are not linked to any public web application in any way.
DNS allows web applications to change their server IP address, so users can continuously access https://www.mega-bank.com without worrying about which web server the request will be resolved to.
The DNS system is very dependent on its ability to synchronize DNS record updates with other DNS servers. Zone transfer is the standardized way for DNS servers to share DNS records.
For DNS background knowledge: you can refer to a snippet in my other article https://www.anquanke.com/post/id/243935

Zone files usually contain DNS configuration data that is not easily accessible. Properly configured, it only authorizes requests from other DNS servers. If misconfigured, anyone can see it.
We need to pretend to be a DNS server and request a DNS zone file, just as if we need it to update our own records.
Assuming, we need to find the DNS server associated with https://www.mega-bank.com first.
host -t mega-bank.com
The responding name servers are as follows:
mega-bank.com name server ns1.bankhost.com
mega-bank.com name server ns2.bankhost.com
It is very simple to send a zone transfer request to the host
host -l mega-bank.com ns1.bankhost.com
-l flag indicates that we want to retrieve the zone transfer file for mega-bank.com from ns1.bankhost.com to update our records.
If the request is successful and it really returns data, it indicates that the DNS server security is not high, and you will see the following results:
Using domain server:
Name: ns1.bankhost.com
Address: 195.11.100.25
Aliases:
mega-bank.com has address 195.250.100.195
mega-bank.com name server ns1.bankhost.com
mega-bank.com name server ns2.bankhost.com
mail.mega-bank.com has address 82.31.105.140
admin.mega-bank.com has address 32.45.105.144
internal.mega-bank.com has address 25.44.105.144
Zone transfer attacks are easy to prevent, and you will find that many applications are already correctly configured to reject these attempts. Therefore, this phenomenon is rare in a century.
Brute-force subdomain
As a final measure for discovering subdomains, brute-force strategies can be used. However, for more mature and secure web applications, brute-force must be very intelligent to build. (Based on rate limiting, performance degradation, and automatic blacklisting of defense records based on regular expressions, etc.)
This may cause your IP address to be logged or blocked by the server or its administrator.
Generally, you can extend each network request by 50 to 250 milliseconds of delay. Hire cloud services and collect day by day.
A brute-force algorithm generates a subdomain and then sends it to<subdomain-guess>.mega-bank.comMake a request. If we receive a response, we will mark it as an active subdomain.
The most important language we are familiar with is JavaScript. JavaScript is not only the only programming language currently available for client-side scripts in web browsers, but also, due to Node.js and the open-source community, it is a very powerful backend server-side language.
Let's use JavaScript to build a brute-force algorithm in two steps.
Generate a list of potential subdomains.
Traverse the list of subdomains, pinging each one to check if the subdomain is valid.
Record the active subdomains, and do nothing with the unused subdomains.
Use the following method to generate a subdomain:
/*
* 一个简单的蛮力尝试生成子域列表的函数
* 给定每个子域的最大长度。
*/
const generateSubdomains = function(length) { #function definition subdomain length
/*
* 从中生成子域的字符列表。
*
* 这可以修改以包含较少见的字符
* 如 '-'.
*
* 中文、阿拉伯文和拉丁字符也是
* 受某些浏览器支持。
*/
const charset = 'abcdefghijklmnopqrstuvwxyz'.split(''); # Enumerate character set
let subdomains = charset;
let subdomain;
let letter;
let temp;
/*
* 时间复杂度: o(n*m)
* n = 字符串的长度
* m = 数目的有效字符
*/
for (let i = 1; i < length; i++) { # Core part generates subdomain 1-4 lengths
temp = [];
for (let k = 0; k < subdomains.length; k++) {
subdomain = subdomains[k];
for (let m = 0; m < charset.length; m++) {
letter = charset[m];
temp.push(subdomain + letter);
}
}
subdomains = temp
}
return subdomains; }
const subdomains = generateSubdomains(4); # Here, the length of the subdomain is set to 4, and the defined function is executed
Now, using this list of subdomains, we can start querying top-level domains such as mega-bank.com. For this, we will write a short script that utilizes the DNS library provided by Node.js—a popular JavaScript runtime environment.
To run this script, you only need to install the latest version of Node.js in your environment (it is based on Unix environments such as Linux or Ubuntu):
const dns = require('dns');
const promises = [];
/*
* This list can be filled with the previous brute force
* script, or use a dictionary of common subdomains.
*/
const subdomains = [];
/*
* Iterate through each subdomain, and perform an asynchronous DNS query
* DNS query against each subdomain.
*
* This is much more performant than the more common `dns.lookup()`
* because `dns.lookup()` appears asynchronous from the JavaScript,
* but relies on the operating system's getaddrinfo(3) which is
* implemented synchronously.
*/
subdomains.forEach((subdomain) => {
promises.push(new Promise((resolve, reject) => {
dns.resolve(`${subdomain}.mega-bank.com`, function (err, ip) {
return resolve({ subdomain: subdomain, ip: ip });
});
});
});
// after all of the DNS queries have completed, log the results
Promise.all(promises).then(function(results) {
results.forEach((result) => {
if (!!result.ip) {
console.log(result);
}
});
});
Firstly, import the Node DNS library. Then we create an array promises, which will store a list of promise objects.Promise PromiseIt is a simpler way to handle asynchronous requests in JavaScript and is natively supported in all major web browsers and Node.js.
After that, we create another array named subdomains, which should be filled with the subdomains generated from the first script.
Next, we use the forEach() operator to easily iterate over each subdomain in the subdomains array. This is equivalent to a for loop, but more elegant in syntax.
At each level of subdomain iteration, we push a new promise object into the promises array. In this promise object, we call dns.resolve, which is a function in the Node.js DNS library that attempts to resolve a domain name to an IP address. The promises pushed into the promise array are only resolved after the DNS library completes its network request.
最后, Promise.all 块只在数组中的每个承诺都已被解析(完成其网络请求)时才接受一组承诺对象和结果(calls .then())。 双 !! 结果中的运算符指定我们只想要返回定义的结果,因此我们应该忽略不返回 IP 地址的尝试。
如果我们包含一个调用reject() 的条件,我们还需要在末尾使用一个catch() 块来处理错误。 DNS 库会引发许多错误,其中一些错误可能不值得中断我们的暴力破解。 为简单起见,示例中省略了这一点,但如果您打算进一步研究此示例,这将是一个很好的练习。
此外,我们使用 dns.resolve 与 dns.lookup ,因为尽管两者的 JavaScript 实现都是异步解析的(无论它们被触发的顺序如何),但 dns.lookup 依赖的本机实现是建立在同步执行操作的 libuv 上的。 我们可以很容易地将这两个脚本组合成一个程序。 首先,我们生成潜在子域的列表,然后我们执行异步蛮力尝试解析子域:
const dns = require('dns');
/*
* 一个简单的蛮力尝试生成子域列表的函数
* 给定每个子域的最大长度。
*/
const generateSubdomains = function(length) {
/*
* 从中生成子域的字符列表。
*
* 这可以修改以包含较少见的字符
* 如 '-'.
*
* 中文、阿拉伯文和拉丁字符也是
* 受某些浏览器支持。
*/
const charset = 'abcdefghijklmnopqrstuvwxyz'.split('');
let subdomains = charset;
let subdomain;
let letter;
let temp;
/*
* 时间复杂度: o(n*m)
* n = 字符串的长度
* m = 数目的有效字符
*/
for (let i = 1; i < length; i++) {
temp = [];
for (let k = 0; k < subdomains.length; k++) {
subdomain = subdomains[k];
for (let m = 0; m < charset.length; m++) {
letter = charset[m];
temp.push(subdomain + letter);
}
}
subdomains = temp
}
return subdomains; }
const subdomains = generateSubdomains(4);
const promises = [];
/*
* Iterate through each subdomain, and perform an asynchronous
* DNS query against each subdomain.
*
* This is much more performant than the more common `dns.lookup()`
* because `dns.lookup()` appears asynchronous from the JavaScript,
* but relies on the operating system's getaddrinfo(3) which is
* implemented synchronously.
*/
subdomains.forEach((subdomain) => {
promises.push(new Promise((resolve, reject) => {
dns.resolve(`${subdomain}.mega-bank.com`, function (err, ip) {
return resolve({ subdomain: subdomain, ip: ip });
});
});
});
// after all of the DNS queries have completed, log the results
Promise.all(promises).then(function(results) {
results.forEach((result) => {
if (!!result.ip) {
console.log(result);
}
});
});
Dictionary attack
The process can be further accelerated by using dictionary attacks instead of brute force attacks. Extracted from the most common subdomain list.
A popular open-source DNS scanner named dnscan comes with the most popular subdomain list on the Internet, which is based on millions of subdomains from over 86,000 DNS zone records.
https://github.com/rbsec/dnscan
const dns = require('dns');
const csv = require('csv-parser');
const fs = require('fs');
const promises = [];
/*
* Begin streaming the subdomain data from disk (versus
* pulling it all into memory at once, in case it is a large file).
*
* On each line, call `dns.resolve` to query the subdomain and
* check if it exists. Store these promises in the `promises` array.
*
* When all lines have been read, and all promises have been resolved,
* then log the subdomains found to the console.
*
* Performance Upgrade: if the subdomains list is exceptionally large,
* then a second file should be opened and the results should be
* streamed to that file whenever a promise resolves.
*/
fs.createReadStream('subdomains-10000.txt')
.pipe(csv())
.on('data', (subdomain) => {
promises.push(new Promise((resolve, reject) => {
dns.resolve(`${subdomain}.mega-bank.com`, function (err, ip) {
return resolve({ subdomain: subdomain, ip: ip });
});
});
})
.on('end', () => {
// after all of the DNS queries have completed, log the results
Promise.all(promises).then(function(results) {
results.forEach((result) => {
if (!!result.ip) {
console.log(result);
}
});
});
});
API Analysis
The next logical investigative skill after subdomain discovery is API analysis.
Which domains does this application use? If this application has three domains (for example, x.domain, y.domain, and z.domain), I should know that each may have its own unique API endpoint.
Finding the API is the second step after discovering the subdomain to understand the structure of the Web application. This step will provide us with the information needed to start understanding the purpose of the public API. When we understand why an API is made publicly available over the network, we can start understanding how it fits into the application and what its business purpose is.
Endpoint Discovery
Generally, APIs will follow REST format or SOAP format. REST is becoming increasingly popular and is considered the ideal structure for modern Web application APIs today.
We can use the developer tools in the browser. If we see many HTTP requests similar to this:
GET api.mega-bank.com/users/1234
GET api.mega-bank.com/users/1234/payments
POST api.mega-bank.com/users/1234/payments
It can be safely assumed that this is a REST API. Note that each endpoint specifies a specific resource rather than a function.
In addition, we can assume that the nested resource payment belongs to user 1234, which tells us that this API is hierarchical. This is another obvious sign of RESTful design.
If we look at the cookies sent with each request and examine the headers of each request, we may also find signs of RESTful architecture:
POST /users/1234/payments HTTP/1.1
Host: api.mega-bank.com
Authorization: Bearer abc21323 # Observe here, authentication token
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/1.0 (KHTML, like Gecko)
Sending a token with each request is another sign of RESTful API design. A REST API should be stateless, meaning the server should not track its requesters.
Once we know that this is indeed a REST API, we can start making logical assumptions about the available endpoints.
The HTTP verbs supported by the REST architecture are as follows:
POST Create
GET Read
PUT Update/Replace
PATCH Update/Modify
DELETE Delete
By looking at the requests for a specific resource that support the architectural specification, we can see which HTTP verbs are supported. Then we can try to send requests to these resources using different HTTP verbs and see if the API returns any interesting content.
The HTTP specification defines a special method that is only used to provide information about specific API verbs. This method is called OPTIONS and should be our preferred method when conducting reconnaissance on the API. We can easily send a curl request from the terminal:
curl -i -X OPTIONS https://api.mega-bank.com/users/1234
Changing burp HTTP verbs directly to OPTIONS is the same.
Generally speaking, OPTIONS is only applicable to APIs specifically designated for public use. Therefore, although this is a simple first attempt, for most of the applications we are trying to test, we need a more powerful discovery solution. Few enterprise applications publicly expose OPTIONS.
Let's continue using a more likely method to determine acceptable HTTP verbs. The first API call we see in the browser is as follows:
GET api.mega-bank.com/users/1234
Now we can expand it to:
GET api.mega-bank.com/users/1234
POST api.mega-bank.com/users/1234
PUT api.mega-bank.com/users/1234
PATCH api.mega-bank.com/users/1234
DELETE api.mega-bank.com/users/1234
Considering the above list of HTTP verbs, we can generate a script to test the legitimacy of our theory.
Brute-forcing API endpoint HTTP verbs may have the side effect of deleting or changing application data. Before performing any type of brute-force attempt on an application API, make sure you have obtained explicit permission from the application owner.
Our script has a simple purpose: using the given endpoint (which we know has already accepted at least one HTTP verb), try each additional HTTP verb. After trying each additional HTTP verb against the endpoint, record and print the results:
/*
* Given a URL (corresponding to an API endpoint),
* attempt requests with various HTTP verbs to determine
* which HTTP verbs map to the given endpoint.
*/
const discoverHTTPVerbs = function(url) {
const verbs = ['POST', 'GET', 'PUT', 'PATCH', 'DELETE'];
const promises = [];
verbs.forEach((verb) => {
const promise = new Promise((resolve, reject) => {
const http = new XMLHttpRequest();
http.open(verb, url, true)
http.setRequestHeader('Content-type', 'application/x-www-form-urlencoded');
/*
* If the request is successful, resolve the promise and
* include the status code in the result.
*/
http.onreadystatechange = function() {
if (http.readyState === 4) {
return resolve({ verb: verb, status: http.status });
}
}
/*
* If the request is not successful, or does not complete in time, mark
* the request as unsuccessful. The timeout should be adjusted based on
* average response time.
*/
setTimeout(() => {
return resolve({ verb: verb, status: -1 });
// initiate the HTTP request
http.send({});
});
// add the promise object to the promises array
promises.push(promise);
});
/*
* When all verbs have been attempted, log the results of their
* respective promises to the console.
*/
Promise.all(promises).then(function(values) {
console.log(values);
});
}
The way this script runs on a technical level is equally simple. HTTP endpoints return status codes as well as any messages they send back to the browser. We are not actually concerned with what the status code is. We just want to see a status code. We send many HTTP requests to the API, one for each HTTP verb. Most servers will not respond to requests that are not mapped to a valid endpoint, so we also have a case where if we do not receive a response within 1 second, we will return -1. Generally, 1 second (in this case 1,000 milliseconds) is sufficient for API responses. You can adjust up or down based on your own use case. After all parsing is committed, you can view the log output to determine which HTTP verbs have associated endpoints.
Authentication Mechanism
Guessing the payload shape required for an API endpoint is much more difficult than simply asserting that an API endpoint exists. The simplest method is to analyze the structure of known requests sent through the browser. In addition to this, we must make informed guesses about the shape required for API endpoints and manually test them.
The structure of API endpoints can be automatically discovered, but any attempt not involving the analysis of existing requests will be easily detected and logged.
It is usually best to start with common endpoints that can be found in almost every application: login, registration, password reset, etc. These typically use payloads similar to other applications because authentication is usually based on standardized design schemes.
Every application with a public Web user interface should have a login page. However, they may differ in how they authenticate your session.
It is important to understand which type of authentication scheme you are using, because many modern applications will send an authentication token with each request. This means that if we can reverse engineer the authentication type used and understand how the token is attached to the request, it will be easier to analyze other API endpoints that depend on authenticated user tokens.
There are several main authentication schemes currently in use, the most common of which are as shown in the table. Translate this for me, let me save some work...
The packet appearance is in the second column, and the third and fourth columns are advantages and disadvantages. Be sure to understand what this chart says, otherwise you can't test anything...

If we log in to https://www.mega-bank.com and analyze the network response, after a successful login, we may see the following content:
GET /homepage
HOST mega-bank.com
Authorization: Basic am1lOjEyMzQ=
Content Type: application/json
At first glance, we can see that this is HTTP basic authentication because the basic authorization header is sent. Moreover, the string am1lOjEyMzQ= is just a base64-encoded username:password string. This is the most common method of formatting a username and password combination to transmit it through HTTP.
In the browser console, we can use the built-in functions btoa(str) and atob(base64) to encode and decode base64.
There is no need to reproduce this, the operation is too simple. Just take a quick look. Leave a message if you have any questions.
/*
* Decodes a string that was previously encoded with base64.
* Result = joe:1234
*/
atob('am1lOjEyMzQ=');
Due to the insecurity of this mechanism, basic authentication is usually only used for web applications that enforce SSL/TLS traffic encryption. In this way, credentials cannot be intercepted in the air - for example, at a rough shopping mall WiFi hotspot.
An important point to note from the analysis of this login/redirect to the homepage is that our requests were indeed authenticated, and they were authorized for access through Authorization: Basic am1lOjEyMzQ=. If we encounter some resources that do not return any data, we should first try to increase the authorization headers and compare them with the packets that were authenticated before the request was made to observe any differences.
Endpoint Shape
Shape: This is what the endpoint APIs look like... What key-value pairs do these endpoint APIs expect to receive?
After finding multiple subdomains and the HTTP APIs contained within them, you should begin to determine the HTTP verbs used by each resource and add the results of this investigation to your web application map. Once you have a complete list of subdomains, APIs, and shapes, you may start to wonder how to truly understand the expected payload types of any given API.
Common shape
If the API can't be found, what's the point of testing it anyway...
Many APIs expect a payload shape that is common in the industry. For example, the authorization endpoint set as part of the OAuth 2.0 flow may require the following data:
{
"response_type": code,
"client_id": id,
"scope": [scopes],
"state": state,
"redirect_uri": uri
}
Since OAuth 2.0 is a widely implemented public specification, it is usually possible to determine the data to be included in the OAuth 2.0 authorization endpoint by combining informed guesses with available public documents.
The naming conventions and scope lists in the OAuth 2.0 authorization endpoint may vary slightly depending on the implementation, but the overall load shape should not be like this.
Examples of OAuth 2.0 authorization endpoints can be found in the Discord (instant messaging) public documents. Discord recommends the following call structure for the OAuth 2.0 endpoint:
https://discordapp.com/api/oauth2/authorize?response_type=code&client_id=157730590492196864&scope=identify%20guilds.join&state=15773059ghq9183habn&redirect_uri=https%3A%2F%2Fnicememe.website&prompt=consent
Among them, response_type, client_id, scope, state, and redirect_uri are all part of the official specifications.
The OAuth 2.0 public documents of Facebook are very similar, and it is recommended to put forward the following requirements for the same function:
GET https://graph.facebook.com/v4.0/oauth/access_token?
client_id={app-id}
&redirect_uri={redirect-uri}
&client_secret={app-secret}
&code={code-parameter}
Finding the shape of an HTTP API is not a complex task. Although many APIs implement general specifications such as OAuth, the logical implementation within the organization does not use general specifications. Key-value pairs may have derivatives.
The shape specific to the application
The shape specific to the application is more difficult to determine than the shape based on public specifications.
To determine the expected shape of the valid payload for the API endpoint, you may need to rely on multiple reconnaissance techniques and slowly understand the endpoint through repeated testing.
Insecure applications may prompt HTTP error messages in the response packet.
For example, suppose you use the following body to call POST https://www.mega-bank.com/users/config:
{
"user_id": 12345,
"privacy": {
"publicProfile": true
}
}
The HTTP status code of the response packet may be 401 Unauthorized or 400 Internal Error. Even the content returned may contain messages describing that the auth_token was not provided, then恭喜您,发现了缺少的参数.
In a field request with the correct auth_token, you may receive another error message: publicProfile only accepts 'auth' and 'noAuth' as parameters. Congratulations, you have discovered how to fill in the field value.
However, more secure applications may only throw general error messages, and you will have to turn to other technologies. Temporarily abandon the testing method here.
If you have a privileged account, you can use the UI to try the same request for your regular account and then try the same request for another account to determine where the differences in their shapes lie.
Identifying third-party dependencies
Using such third-party dependencies in application code is not without risk, and third-party dependencies are usually not as thoroughly security-reviewed as internal code.
During the reconnaissance process, you may encounter many third-party integrations, and you will need to pay very close attention to dependencies and integration methods. Typically, these dependencies become attack vectors; sometimes, the vulnerabilities in such dependencies are well-known, and you may not even need to prepare the attack yourself but can copy the attack from the Common Vulnerabilities and Exposures (CVE) database.
Detecting client frameworks
Generally, developers do not build complex UI infrastructure but use well-maintained and well-tested UI frameworks. These usually appear as SPA libraries, used to handle complex states, pure JavaScript frameworks (Lodash, JQuery) for fixing cross-browser functionality vulnerabilities in the JavaScript language, or as CSS frameworks (Bootstrap, Bulma) for improving the appearance of websites.
If you can determine the version number, you can usually find the combination of ReDoS, Prototype Pollution, and XSS vulnerabilities (especially those in outdated versions without updates) on the network.
Detect SPA frameworks
The largest SPA framework on the network is (in no particular order):
• EmberJS (LinkedIn, Netflix)
• AngularJS (Google)
• React (Facebook)
• VueJS (Adobe, GitLab)
Each of these frameworks introduces very special syntax and order to explain how they manage DOM elements and how developers interact with the framework. Not all frameworks are so easy to detect. Some require fingerprinting or advanced techniques. Be sure to write down the version when it is given.
EmberJS
EmberJS is easy to detect because when EmberJS boots up, it sets a global variable Ember, which can be easily found in the browser console.
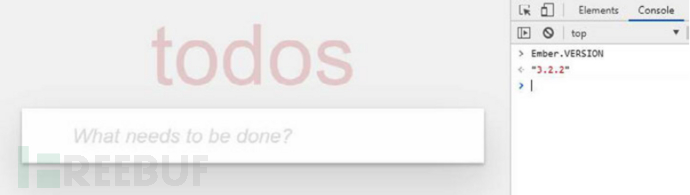
Ember also uses ember-id to mark all DOM elements for its internal use. This means that if you use Ember to view the DOM tree of any given web page through Developer tools → Elements tab, you should see many divs containing id=ember1, id=ember2, id=ember3, etc. Each div should be wrapped in a parent element with class="ember-application", which is usually the body element.
Ember can easily detect the running version. Just reference a constant attached to the global Ember object:
// 3.1.0
console.log(Ember.VERSION);
AngularJS
Old versions of Angular provided a global object similar to EmberJS. The global object was named angular, and the version could be derived from its property angular.version. AngularJS 4.0+ removed this global object, making it a bit difficult to determine the version of an AngularJS application. You can detect whether an application is running AngularJS 4.0+ by checking if the ng global exists in the console.
To detect the version, you need to do more work. First, obtain all root elements in the AngularJS application. Then check the properties of the first root element. The first root element should have a property ng-version, which will provide you with the AngularJS version of the application you are investigating:
// returns array of root elements
const elements = getAllAngularRootElements();
const version = elements[0].attributes['ng-version'];
// ng-version="6.1.2"
console.log(version);
React
React can be identified through the global object React, and like EmberJS, its version can be easily detected through a constant:
const version = React.version;
// 0.13.3
console.log(version);
You may also notice that script tags with the type text/jsx reference React's special file format, which includes JavaScript, CSS, and HTML in the same file. This is a deadly gift when using a React application, and knowing that each part of the component originates from a single .jsx file can make investigating a single component much easier.
VueJS
Similar to React and EmberJS, VueJS exposes a global object Vue with a version constant:
const version = Vue.version;
// 2.6.10
console.log(version);
If you cannot inspect elements on a VueJS application, it may be because the application is configured to ignore developer tools. This is a toggle property attached to the global object Vue.
You can toggle this property to true to start inspecting VueJS components in the browser console again:
// Vue components can now be inspected
Vue.config.devtools = true;
Detecting JavaScript libraries
There are too many JavaScript helper libraries that cannot be counted, some of which expose global variables and others that run under the radar. Many JavaScript libraries use the top-level global object to name their functions. These libraries are easy to detect and iterate.

Underscore and Lodash expose global variables using the symbol $, while jQuery uses the $ namespace, but it is best to run a query to see all external scripts loaded into the page, except for the main library.
We can use the DOM's querySelectorAll function to quickly find the list of all third-party scripts imported into the page:
/*
* Utilizes built-in DOM traversal function
* to quickly generate a list of each <script>
* tag imported into the current page.
*/
const getScripts = function() {
/*
* A query selector can either start with a "."
* if referencing a CSS class, a "#" if referencing
* an `id` attribute, or with no prefix if referencing an HTML element.
*
* In this case, 'script' will find all instances of <script>.
*/
const scripts = document.querySelectorAll('script');
/*
* Iterate through each `<script>` element, and check if the element
* contains a source (src) attribute that is not empty.
*/
scripts.forEach((script) => {
if (script.src) {
console.log(`i: ${script.src}`);
}
});
};
Calling this function will give us the following output:
getScripts();
VM183:5 i: https://www.google-analytics.com/analytics.js
VM183:5 i: https://www.googletagmanager.com/gtag/js?id=UA-1234
VM183:5 i: https://js.stripe.com/v3/
VM183:5 i: https://code.jquery.com/jquery-3.4.1.min.js
VM183:5 i: https://cdnjs.cloudflare.com/ajax/libs/d3/5.9.7/d3.min.js
VM183:5 i: /assets/main.js
From here, we need to access the script directly to determine orders, configurations, etc.
Detect CSS library
By slightly modifying the algorithm for detecting scripts, we can also detect CSS:
/*
* Makes use of DOM traversal built into the browser to
* quickly aggregate every `<link>` element that includes
* a `rel` attribute with the value `stylesheet`.
*/
const getStyles = function() {
const scripts = document.querySelectorAll('link');
/*
* Iterate through each script, and confirm that the `link`
* element contains a `rel` attribute with the value `stylesheet`.
*
* Link is a multipurpose element most commonly used for loading CSS
* stylesheets, but also used for preloading, icons, or search.
*/
scripts.forEach((link) => {
if (link.rel === 'stylesheet') {
console.log(`i: ${link.getAttribute('href')}`);
}
});
};
Similarly, this function will output the list of imported CSS files:
getStyles();
VM213:5 i: /assets/jquery-ui.css
VM213:5 i: /assets/boostrap.css
VM213:5 i: /assets/main.css
VM213:5 i: /assets/components.css
VM213:5 i: /assets/reset.css
Detecting the server-side framework
Some scripts may fail to work due to different initial conditions.
It is much easier to detect the software running on the client (browser) than the software running on the server. In most cases, all the code required by the client is downloaded and stored in memory through DOM references. Some scripts may be loaded conditionally or asynchronously after the page is loaded, but they can still be accessed as long as the correct conditions are triggered.
Header Detection
Some web server packages with insecure configurations expose too much data in their default headers. For example, the X-Powered-By header, this feature is enabled by default on older versions of Microsoft IIS.
X-Powered-By: ASP.NET
Server: Microsoft-IIS/4.5
X-AspNet-Version: 4.0.25
Smart administrators disable these headers and remove them from the default configuration.
Default error messages and 404 pages
Some popular frameworks do not provide a very simple method to determine the version number. If these frameworks are open source, such as Ruby on Rails, you may be able to determine the version used through fingerprint recognition.
The historical versions of Git version control, specific modifications submitted can be used to identify the version number.
Most servers have their own default error messages and 404 pages. If the web application framework does not provide or configure a 404 page, the default error page of the server is displayed.
You can flip through the git version files, search in the repository, and compare the differences in the 404 pages
https://github.com/rails/rails


Take a look at the content of each version change, for example
• April 20, 2017 - Namespace CSS selectors added to 404 page
• November 21, 2013 - Replaced U+00A0 with space
• April 5, 2012 - Removed HTML5 type attribute
Database Detection
If database error messages are sent directly to the client, you can use techniques similar to those used to detect server packets to determine the database. This is usually not the case, so you must find other discovery routes.
One technique that can be used is primary key scanning. Most databases support the concept of 'primary key', which refers to the key in a table (SQL) or document (NoSQL) that is automatically generated at the time of object creation and used for fast searches in the database.
If you can determine how the default primary key of some major databases is generated, you have a good chance of identifying the database type unless the default method has been changed.
Taking the popular NoSQL database MongoDB as an example. By default, MongoDB generates a field named _id for each document created. The _id key is generated using a low collision hash algorithm that always produces a hexadecimal compatible string of length 12. In addition, the algorithm used by MongoDB is visible in its open-source documentation.
https://oreil.ly/UdX_v
The document tells us the following:
• The class used to generate these ids is called ObjectId.
• Each id is exactly 12 bytes.
• The first 4 bytes represent the number of seconds since the Unix epoch (Unix timestamp).
• The next 5 bytes are random.
• The last 3 bytes are a counter starting with a random value.
ObjectId example: 507f1f77bcf86cd799439011.
After understanding the structure of MongoDB primary keys, we hope to view the HTTP traffic and analyze the 12-byte payloads we find that have a similar appearance.
This is usually simple, and you will find the primary key in the form of a request, for example:
GET users/:id # Where :id is the primary key
PUT users, body = { id: id } # Where :id is the primary key
GET users?id=id # Where id is the primary key but in the query parameters
Sometimes, the id may appear in the most unexpected places, such as in metadata or in responses about user objects:
{
_id: '507f1f77bcf86cd799439011',
username: 'joe123',
email: 'joe123@my-email.com',
role: 'moderator',
biography: '...'
}
No matter how you find the primary key, if you can confirm that the value is indeed the primary key from the database, you can then start studying the database and try to find characteristic values that match its key generation algorithm.
This is usually sufficient to determine what database the web application is using, but if you encounter multiple databases using the same master database, you may sometimes need to combine it with another technology (such as forced error messages) using key generation algorithms (such as consecutive integers or other simple patterns).
Identify weaknesses in the application architecture
Throughout the reconnaissance process, you should record the findings in the notes, as some web applications are so vast that exploring all their features may take several months. Documentation of the reconnaissance period is invaluable.
Ideally, the notes should contain:
• Technologies used in web applications
• List of API endpoints listed by HTTP verbs
• List of API endpoint shapes (if any)
• Functions included in the web application (such as, comments, authentication, notifications), etc.
• Domains used by the web application
• Found configurations (such as, Content Security Policy or CSP)
• Authentication/session management system
Design requirements are more important than code auditing. Most vulnerabilities originate from poor design.
Most vulnerabilities in web applications originate from poorly designed application architecture, not from poorly written methods. Of course, the method of directly writing user-provided HTML into the DOM is certainly risky and may allow users to upload scripts (if there is no proper cleaning) and execute them on another user's machine (XSS).
Some applications have dozens of XSS vulnerabilities, while other similar-sized applications in the same industry have almost none. Ultimately, the architecture of the application and the architecture of the modules/dependencies within the application are likely to be the weak points that are most likely to have vulnerabilities.
Signs of secure and insecure architecture
A single XSS vulnerability may be the result of poorly written methods, but multiple vulnerabilities may be a sign of weak application architecture.
Assuming two simple applications that allow users to send messages (text) to other users. One application is vulnerable to XSS attacks, while the other is not.
When making a request to store comments at the API endpoint, an insecure application may not reject the script; its database may not reject the script, and it may not perform appropriate filtering and cleaning on the string representing the message. Ultimately, it is loaded into the DOM and evaluated as a DOM test message<script>alert('hacked');</script>, thereby causing script execution.
It is necessary to be aware of what functional points need to be filtered out, what data needs to be checked, and if the functional point has an output, it should also be checked or encoded, etc., before application development.
If the application architecture is inherently insecure, even applications written by engineers proficient in application security may ultimately have security vulnerabilities.
This is because secure applications implement security before and during the development of features, while applications with moderate security implement security during feature development, and potentially insecure applications may not implement any security.
If developers must write 10 variants on the instant messaging (IM) system in the previous example over a span of 5 years, each implementation is likely to be different. The security risks between each implementation will be roughly the same. Each of these IM systems includes the following features:
• UI used for writing messages
• API endpoint receives messages that have just been written and submitted
• Database table used for storing messages
• API endpoint used for retrieving one or more messages
• UI code for displaying one or more messages
The application code is as follows: Variants of similar code with similar security issues are presented here for careful observation, rather than occupying space in the article. You should think about functional points, observe security, and discover in the process of growth that you need to combine various specific functional points, check where the code implements them, and whether there is a security design. Think comprehensively from input to output, combining functional points, business logic, roles, and even the purpose of the entire program.
client/write.html
<!-- Basic UI for Message Input Message Input UI-->
<h2>Write a Message to <span id="target">TestUser</span></h2>
<input type="text" class="input" id="message"></input>
<button class="button" id="send" onclick="send()">send message</button>
client/send.js
const session = require('https://www.freebuf.com/articles/es/session');
const messageUtils = require('https://www.freebuf.com/articles/es/messageUtils');
/*
* Traverses DOM and collects two values, the content of the message to be
* sent and the username or other unique identifier (id) of the target
* message recipient.
*
* Calls messgeUtils to generate an authenticated HTTP request to send the
* provided data (message, user) to the API on the server. Send the value to the server API endpoint
*/
const send = function() { # Can you find the API endpoint interface?
const message = document.querySelector('#send').value;
const target = document.querySelector('#target').value;
messageUtils.sendMessageToServer(session.token, target, message);
};
server/postMessage.js Server-side reception
const saveMessage = require('https://www.freebuf.com/articles/es/saveMessage');
/*
* Receives the data from send.js on the client, validating the user's
* permissions and saving the provided message in the database if all
* validation checks complete.
*
* Returns HTTP status code 200 if successful.
*/
const postMessage = function(req, res) { # Can you find any security checks missing?
if (!req.body.token || !req.body.target || !req.body.message) {
return res.sendStatus(400);
}
saveMessage(req.body.token, req.body.target, req.body.message)
.then(() => {
return res.sendStatus(200);
})
.catch((err) => {
return res.sendStatus(400);
});
};
server/messageModel.js
const session = require('https://www.freebuf.com/articles/es/session');
/*
* Represents a message object. Acts as a schema so all message objects
* contain the same fields.
*/
const Message = function(params) {
user_from: session.getUser(params.token),
user_to: params.target,
message: params.message
};
module.exports = Message;
server/getMessage.js
const session = require('https://www.freebuf.com/articles/es/session');
/*
* Requests a message from the server, validates permissions, and if
* successful pulls the message from the database and then returns the
* message to the user requesting it via the client.
*/
const getMessage = function(req, res) {
if (!req.body.token) { return res.sendStatus(401); }
if (!req.body.messageId) { return res.sendStatus(400); }
session.requestMessage(req.body.token, req.body.messageId) .then((msg) => {
return res.send(msg);
})
.catch((err) => {
return res.sendStatus(400);
});
};
client/displayMessage.html
<!-- displays a single message requested from the server -->
<h2>Displaying Message from <span id="message-author"></span></h2>
<p class="message" id="message"></p>
client/displayMessage.js
const session = require('https://www.freebuf.com/articles/es/session');
const messageUtils = require('https://www.freebuf.com/articles/es/messageUtils');
/*
* Makes use of a util to request a single message via HTTP GET and then
* appends it to the #message element with the author appended to the
* #message-author element.
*
* If the HTTP request fails to retrieve a message, an error is logged to
* the console.
*/
const displayMessage = function(msgId) {
messageUtils.getMessageById(session.token, msgId) .then((msg) => {
messageUtils.appendToDOM('#message', msg);
messageUtils.appendToDOM('#message-author', msg.author);
})
.catch(() => console.log('an error occurred'););
};
Many security mechanisms required to protect this simple application can and are likely to be abstracted into the application architecture, implemented through calls rather than directly implementing regular expressions and filters in this code.
Take DOM injection as an example. A simple method built into the UI is shown below, which can eliminate most XSS risks:
import { DOMPurify } from 'https://www.freebuf.com/articles/utils/DOMPurify';
// makes use of: https://github.com/cure53/DOMPurify #Check here, sanitization
const appendToDOM = function(data, selector, unsafe = false) {
const element = document.querySelector(selector);
// for cases where DOM injection is required (not default)
if (unsafe) {
element.innerHTML = DOMPurify.sanitize(data); #DOMPurify.sanitize is abstracted into the application architecture
} else { // standard cases (default)
element.innerText = data;
}
};
Building applications around such features simply will greatly reduce the risk of XSS vulnerabilities in the codebase.
Can I bypass the filter? Then the war has shifted here https://github.com/cure53/DOMPurify
This observation is particularly important, as it first makes you aware of whether the development has mastered this application architecture that abstracts from the security design.
Mechanisms like the appendToDOM method mentioned earlier are signals of a secure application architecture.
Applications lacking these security mechanisms are more likely to contain vulnerabilities. This is why identifying insecure application architectures is important for discovering vulnerabilities and determining the priority of codebase improvements.
Multi-layer security
In the previous example, we added the disinfection program architecture DOMPurify.sanitize() at the input point, but we need to consider multiple levels of defense, including horizontal and vertical.
• API POST
• Database writing
• Database reading
• API acquisition
• Client reading
• And the data output points
The same is true for other types of vulnerabilities, such as XXE or CSRF—each vulnerability may be caused by insufficient security mechanisms at one level or above.
For example, suppose a hypothetical application (such as a messaging application) adds security mechanisms at the API POST layer to eliminate XSS risks. Now it may not be possible to deploy XSS through the API POST layer.
However, in the future continuous development, another method of sending messages may be developed and deployed. If the new API endpoint does not provide security mechanisms, XSS can be deployed here again.
If developers implement security improvement mechanisms at multiple locations, such as API POST and database write stages, and data output stages, the new attacks can be mitigated.
The safest web application is: introducing security mechanisms in many layers and improving default insecure configurations. In contrast, insecure web applications only introduce security mechanisms in one or two layers. Because you will never know where the high-risk and high-harm areas are, therefore, it is necessary to improve all problematic areas to extend the width of defense. If you have this awareness of reconnaissance, you can prioritize where to start the detection because it is more likely to be exploited.
Adoption and modification
In summary, organizations may have their own reasons for reinventing the wheel.
A component with a secure design: a function that requires profound professional knowledge in mathematics, operating systems, or hardware. This includes databases, process isolation, and most memory management. It is impossible to be an expert in all aspects. Therefore, it is recommended to use excellent open-source components.
Summary
Thank you, masters, for your patience in reaching here.
We will meet again.
Mutual encouragement.

评论已关闭