1. Business background
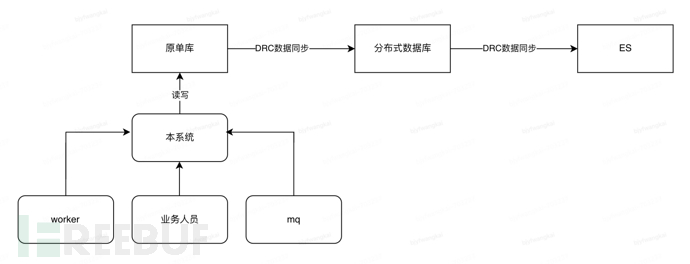
System business functions:The system internally handles data processing and integration, and provides initialization (write) of result data and query data result services to external systems.
System network architecture:

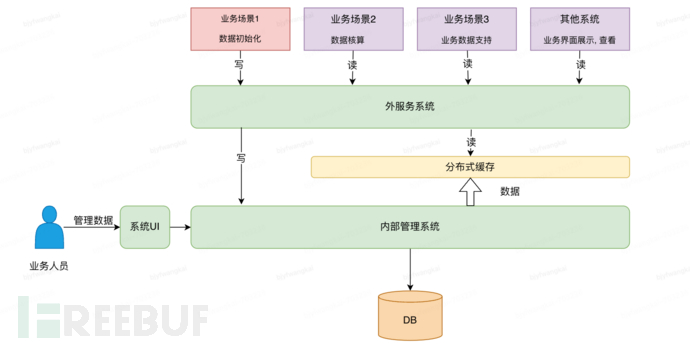
•
The impact of deployment architecture on the cut volume launch - the launch of the internal management system has no impact on the read business of other systems
• Distributed cache can be expanded separately, which is unrelated to the upgrade of storage and query functions
• Through the isolation of the cache layer, external systems can remain unchanged during the system expansion period, and only the internal management system upgrade is affected
• During the internal system launch/verification, in addition to the initialization operations related to business scenario 1, read services can still be provided to reduce the impact of launch
Secondly, the overall implementation plan for this upgrade:
Overall implementation plan diagram:
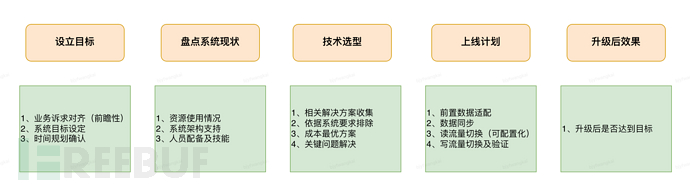
(1) Establish goals
Commodity full volume channel plan - cut volume plan: (Total is 10 times the current):

Currently:
The commonly used tables in the current database have all exceeded5000WAmong the results, some are expressed as 6000W, which has reached the peak capacity of the MYSQL database table, and cannot support the full cut volume;
Goal:
Highest support900 million: According to the slicing plan, after full slicing, the system is about 6.7 billion, retaining 1/4 redundancy, taking8.375Billion; Round up to 900 million, this value has a large redundancy, can meet the data support for the next 5 years
Time goal: scheme setting in early August, online and verification from August 17 to August 22, August 24 slicing plan starts
(Second), current system status
1. Resource usage
• Current deployment structure
——Data center distribution, Mysql: 1 master 4 slaves (Data center A 1 master, 3 slaves; Data center B only read slave)
——Data center distribution, Doris: 32C, 63 nodes, 3 replicas
• Current application container (docker) count, db maximum connection count
——Application container count: 62 (Web group: 25, Worker group: 31, MQ group: 6)
——db maximum connection number 100 (each container configuration)
• Whether the current business is read-write separated, and what is the read-write ratio
——No read-write separation
• Under various business scenarios, whether the master-slave delay can be tolerated? How long is the tolerable delay time
——Most of the modification operations of the business personnel are synchronous operations, and the operation result is returned to the front end after completion. From the perspective of business operations + query results, it is impossible to tolerate delay
——Background task scenario, for intermediate data processing, can tolerate master-slave delay
• At the product level, when the system encounters bottleneck pressure, is it acceptable to limit the flow? Is it acceptable to delay data display?
——This time's external service interface does not involve development, service interface is not affected; business page visit volume is low, can accept short-term delay
• Does the team have ES usage experience?
——Partly understood, not used in the project
2. Internal usage of the database
Use a general inventory framework to comprehensively sort out the current situation of the system
Table space, business scenarios and other information (part)
| Table name | Current number of records in the table (Unit: ten thousand) | Maximum supported number of records (Unit: ten thousand) | Number of table fields | Whether it can be split out into a sharding key | Sharding key field | Whether there is an SQL without sharding field | Whether there is a cross-table query scenario | Data record read-write ratio | Whether there is an immediate query after writing | Use case | Whether the data can be truncated | Acceptable truncation duration | Estimated amount after slicing | Distributed DB | ES judgment condition: whether there is a complex query | ES direct double write, judgment condition: query immediately after writing |
| Approval flow table | 3.5KW | 4 kW | 43 | Yes | sku | There is | There is | 1000/1 | There is a manual query operation after writing | 1. Page creation of approval flow 2. Page query of approval flow 3. Page data set to invalid 4. Callback modification from approval platform | No | +300 million | ✅ | ✅ | After UI modification, you need to click the "Query" button again; | |
| Approval flow details table (historical data has been cleaned) | 800W | 4 kW | 20 | Yes | Add SKU | None | There is | 1000/1 | There is a manual query operation after writing | 1. Refresh approval flow (delete + add) 2. Query approval-in-process processes (tasks) | Convert to cold backup after approval | Convert to cold backup | ✅ | ✅ | ||
| Business data table 1 | 3.3 kW | 4 kW | 15 | Yes | sku | None | None | 100/1 | 1. Create after approval 2. Data invalidation, deletion operation 3. Background tools: synchronize cache (complex and pagination query) | No | +300 million | ✅ | ❌ | ❌ | ||
| Business data table 2 | 5.9 kW | 4 kW | 16 | Yes | sku | Exists (abnormal deletion after addition according to id) | None | 1000/1 | 1. Business query/export dimension 1 data 2. Business query dimension 2 data 2 3. Background tools: synchronize cache | No | +500 million | ✅ | Synchronize big data push data to cache, use creator field to query; multiple SKU pagination query | ❌ | ||
| Support data table (big data platform calculation and push) | 1.2 kW | 4 kW | 12 | Yes | item_sku_id | None | None | 5/1 | 1. Operation and maintenance tools: add/delete records 2. Clean up historical data (task) 3. Data query (display usage) 4. Calculation 5. Big data push data | Pushed by date, currently retained for 3 days | Historical data is useless for doris? | 3 to 4 kW per day | ✅ | Delete data dt | ❌ | |
| ..... |
(Three) technical solution selection
System characteristics: high concurrency write of single table, complex read
1. Storage selection:
Conclusion:
Internal distributed database: expanded from single shard to multi-shard, solving massive data storage and simple query
ES: newly introduced, to realize complex query (token query) and global sorting
redis: retained, needs expansion
Doris: retained, capacity increased
Complex query (reason: there are multi-table association scenarios in the front-end business access (2 tables with tens of millions of level association queries), with the increase of table capacity, the performance of association query decreases, and it can no longer meet the business efficient requirements)
Complex query decision factors:
| Distributed DB (mysql) | es | doris | TiDB | ||
| Decision indicators | Product positioning | Database (OLTP) | Search engine | Database (OLAP) | Database (OLTP+80%OLAP) |
| Advantages: | 1. High concurrency and high throughput transaction processing 2. Stability 3. Data real-time (write and read immediately) | 1. Full-text index 2. Complex structured query | High concurrency query analysis | 1. Both transaction processing and data analysis 2. Automatic expansion 3. Data real-time (write and read immediately) | |
| Disadvantages: | 1. Large-scale data analysis 2. Manual expansion | 1. Transaction processing 2. Real-time (write and read immediately) | 1. Transaction processing 2. Real-time (write and read immediately) | High concurrency and high throughput transaction processing | |
| Reliability | High (multi-machine room) | High (multi-machine room) | Low (shared cluster) | Low (single machine room) | |
| Scalability | Database dimension: platform management, table dimension: application control | Platform management | Database dimension: platform management, table dimension: application control | ||
| Data consistency | Final consistency | Final consistency | Strong consistency | ||
| Operation and maintenance support | DBA | Branch operation and maintenance | No professional operation and maintenance team | Branch DBA | |
| Summary | Slow complex business queries, unable to support cross-table queries, multi-dimensional complex queries, and global sorting. Single-table query performance is fast using sharding fields | High performance in complex business queries | The deployment structure is a shared cluster, (especially) the write performance is greatly affected by external factors | The deployment architecture is a single room, which cannot meet the reliability requirements of the 0-level system | |
| Architecture goal | |||||
| Conclusion | Massive storage and high concurrency write | ✅ Large data volume storage, high performance of single-table query based on sharding field, single database transaction processing | ✖️ Transaction processing under high concurrency | ✖️ Query is greatly affected by write/update operations | ✖️ Transaction processing reliability under high concurrency |
| Complexity of query | ✖️ Poor performance, may exist cross-database query | ✅ High reliability under large data volume complex business queries | ✖️ Query is greatly affected by write/update operations | ✖️ Reliability | |
2. Data synchronization plan
A-Real-time Synchronization Plan:
Solution description: Use the DRC platform to configure and complete the near-real-time data synchronization from distributed DB to ES (Note: DRC is a company's internal general data synchronization platform that can be used for data synchronization between multiple data sources)
Advantages:: Simple unordered code development Disadvantages:: There may be business write-read scenarios after writing, with the risk of data inconsistency
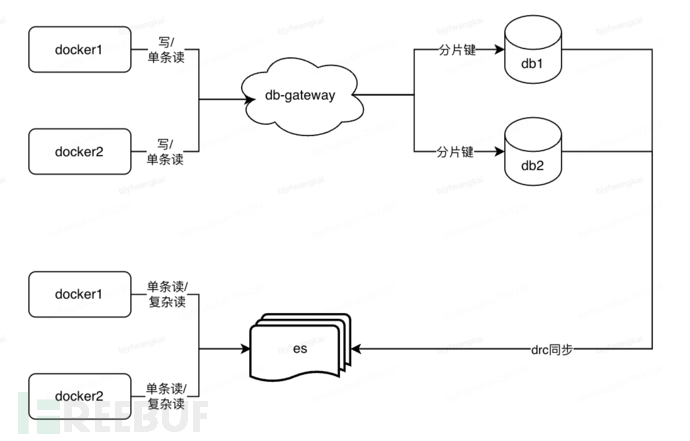
B-Dual Write Strong Consistency Plan:
Solution description: Dual write distributed DB and ES, ensure data consistency
Advantages:: Ensures the consistency of the data write-read scenario Disadvantages:: High code development cost
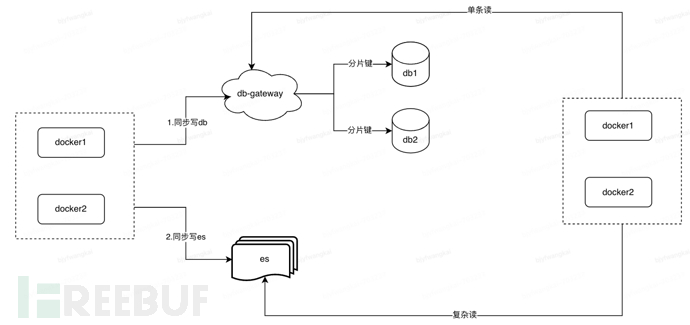
Data synchronization plan selection suggestion:
First choose A-Real-time Synchronization Plan -> Online verification to see if it meets the business operation experience -> Then decide whether to implement B-Dual Write Strong Consistency Plan
Data synchronization difficulties and solutions:
Problem:
• The double-table joint query scenario cannot be directly synchronized using the DRC platform, and it is necessary to develop a corresponding synchronization module jar package, embed it in the DRC task, or give up using DRC, directly use code synchronization, all of which have the problem of long development time
• The ES index space occupancy is large, the number of redundant records is large, and the query results need to be deduplicated, which is complex to query
Difficulties: The process table and the process detail node table involve joint queries, both tables have single-table add/delete/modify operations; leading to a complex data model and difficult synchronization of the data synchronized to ES
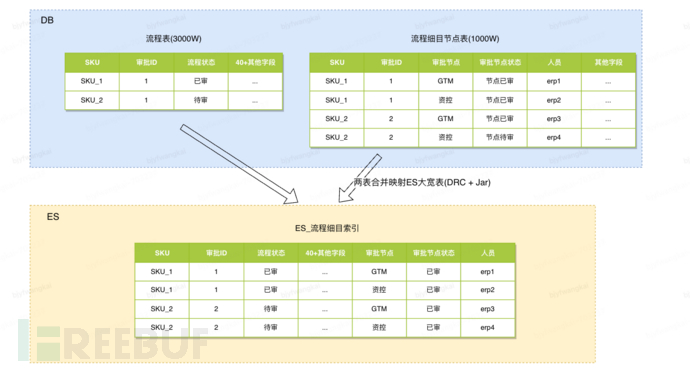
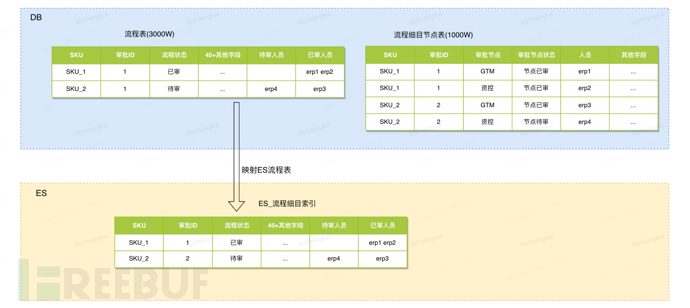
Solution: (Add redundant fields to the database table, and redundant fields are specifically used for ES queries)
Add the fields for pending review personnel and reviewed personnel to the process table in DB, with the values of the fields separated by spaces. Use the tokenization function of ES, and at the same time, ES can directly use the DRC tool to synchronize this table data, reducing the development time for synchronization
Solution cost: Synchronize the new fields in the process table when adding/ modifying detailed procedures; Develop a tool for refreshing historical data
(4) Phased development and implementation steps for going online
1. System business transformation - table field addition (August 10th)
1) Add sharding field to business table
Part of the business tables lack sharding fields, so they cannot be directly sharded. For the business tables, a new SKU sharding field is added, and the existing logic is modified to add SKU conditions to improve query efficiency;
2) Increase redundant fields for ES-related queries (data refresh)
2, Synchronization and verification of distributed database sharding data (August 11)
1) Complete the initialization of the distributed database sharding library + ES;
2) Configure DRC to complete the full and incremental data synchronization from the original single database to the distributed database sharding library;
3) Configure DRC to complete the full and incremental data synchronization from the distributed database sharding library to the ES;
4) Regularly compare the data consistency between the distributed database, distributed database sharding, and ES through inspection tools.
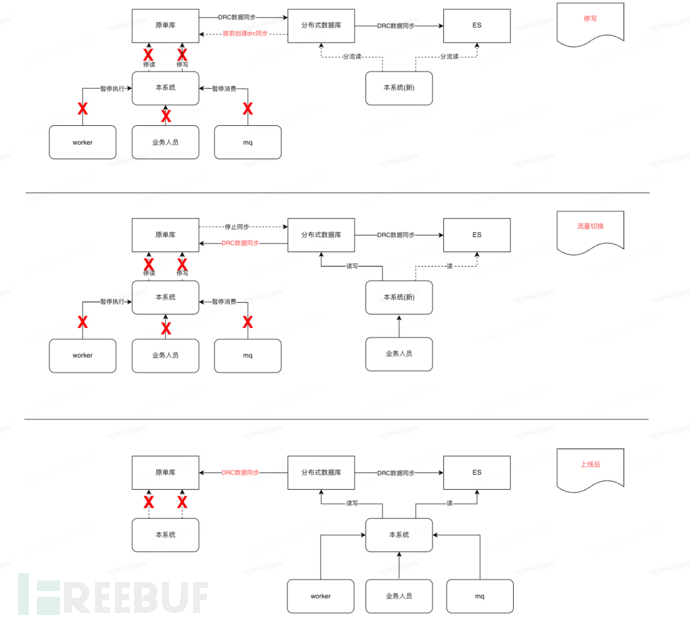
3, Read traffic switching + verification (August 17)
1) Add a new AOP aspect, and gradually shift the read requests to the new application cluster through DUCC configuration (erp whitelist, full read, result comparison, etc.)
2) After the product and business sides complete the verification, switch all read traffic to the new application cluster (note: the new application cluster uses a read-only account for the database)

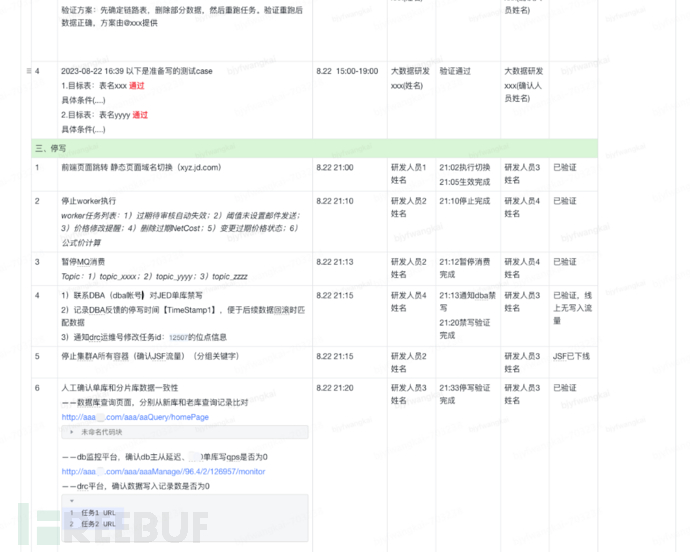
4, Write traffic switching (8.21)
1) Inform the business party and upstream and downstream systems before the launch, inform the launch time and estimated duration, and reduce the impact on business
2) Add a static page to prompt users that the system upgrade is not available, switch the front-end domain to the static page, and avoid user operations
3) Stop the original system grouping, ensure that there is no write traffic in the original single database, and at the same time coordinate with the DBA to execute the write prohibition on the original database (close the worker, pause the MQ consumption)
4) Wait and ensure that the original database data is fully synchronized to the target database, and then manually and automatically verify the consistency of the data in the new and old two databases
5) Switch the new system grouping to read and write accounts and deploy
7) R&D and testing personnel use test products to test the new system's grouping function, and after there are no problems, they are handed over to business personnel for verification (switch to static operation and maintenance page)
8) Start the worker and connect to the MQ
5, Effect after launch
The system runs normally after the launch, and 2.6 billion products have been settled from 8.23 to the present; The current system supports product category data of 316 million; The maximum DB table data has reached 284 million; ES data is 43,560,000;
Comparison before and after: erp: xxx; This erp account has 29w data. The original query takes 9s, and the new query takes 1s;
Four, Summary
Good suggestions:
• Comprehensive and clear inventory of the current system status: can reduce complexity and improve quality
• Clear launch plan: guide personnel to reasonably divide labor, shorten the launch time, and reduce the difficulty of launch
Unsolved problems:
Currently, the distributed database distributed transaction support is relatively weak, and it cannot guarantee the correctness of multiple records being modified in a single transaction across different databases, and it is necessary to submit, read after submission, and verify to ensure that the data is correctly saved
When the product data under the business personnel reaches one million, the query time is still long, and the query performance will continue to be optimized
Author: JD Retail, Wang Kai
Source: JD Cloud Developer Community. Please indicate the source of reproduction
Full-patch domain forest collapsed in 5 seconds? Trust avalanche after encryption upgrade.
Guokr Cloud: Understand the security advantages of IPv6 upgrade and transformation in ten minutes
Fake Google ads target Microsoft ad accounts, and malware attacks are upgraded again
A Brief Discussion on Data Security Governance and Hierarchical Classification Implementation

评论已关闭