In recent years, pre-trained language models have become one of the most attention-grabbing technologies in the field of natural language processing (NLP). Pre-trained models can perform self-supervised learning on large-scale text corpora, thereby obtaining rich linguistic knowledge, and achieve excellent performance by fine-tuning on downstream tasks. Prompt Learning (prompt learning) is a new pre-trained model paradigm that guides the model to learn by providing specific task prompts during the pre-training process, helping the model better utilize the contextual information of the task, thereby improving the performance of the model. It also enables the model to maintain good performance in low-resource scenarios such as Few-shot and Zero-shot. This issue's foresight insight starts from the Prompt Learning pre-training paradigm, discussing what is Prompt, why Prompt, and how to Prompt. Finally, it will combine the most popular technology ChatGPT for a simple explanation of the Prompt paradigm, more intuitively demonstrating the charm of Prompt Learning.
1 Introduction

Figure caption: Prompt magical power[1]
The development of artificial intelligence has always been a hot topic in the technology community. Over the past few decades, people have been exploring how to make machines more intelligent. However, despite the significant progress made by modern machine learning technology, machines still perform far worse than humans in some areas. One of the key reasons is that machines often lack human common sense and reasoning ability. This makes machines perform poorly in complex tasks, such as natural language understanding and text generation.
To solve this problem, researchers have been trying various methods. One of the most promising methods is Prompt Learning. Prompt Learning is a template-based machine learning method that provides some 'prompts' to help the model better understand the task, thereby improving the performance of the model.
When training a model, the first step is to define a prompt template, which contains some prompt information, such as keywords, phrases, and sentences. Then, the prompt template is input into the model along with the training data for training. During prediction, the prompt template can be input into the model along with the data to be predicted, thereby helping the model better understand the input data. The prompt information used in model training is usually understandable to humans, which also allows for a better understanding of the logic and reasoning process of the model when making decisions. By combining different prompt patterns, the model can complete different task requirements during prediction. At the same time, adding prompt information can help the model better utilize existing labeled data, learn more general feature representations, and thus maintain good performance in low-resource scenarios.
2 Prompt Learning Derivative Path
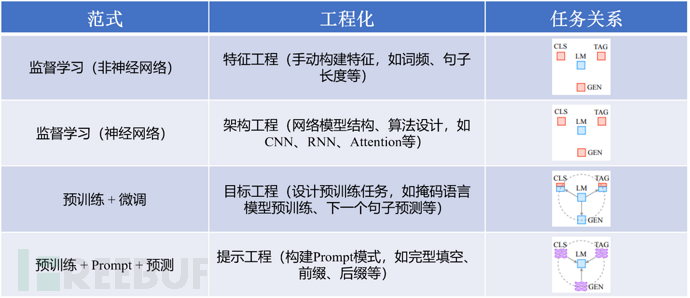
Figure caption: Typical NLP technology paradigm[1]
The development of Natural Language Processing (NLP) technology has gone through typical four paradigm stages: the stage of feature engineering + machine learning, where feature engineering refers to extracting, constructing, and transforming useful features from raw data for algorithm model training and learning. In the early stage, people usually need to manually construct features to solve specific problems, which may require a lot of time and energy, and requires professional knowledge and skills; with the development of deep learning technology, feature engineering has undergone significant changes, and models can automatically extract richer and more robust features from raw data, thereby reducing the need for manual feature construction, and more attention is paid to network model structure design and algorithm optimization; with the emergence of large-scale pre-trained language models such as BERT and GPT, the world has gradually formed a unification again, and the pre-training + fine-tuning paradigm has become the basic solution for many NLP modeling tasks (such as CLS classification tasks, TAG sequence tasks, LM language models, and GEN generation tasks, etc.). On the basis of pre-trained models, introducing downstream task data for fine-tuning training usually can achieve a good implementation effect, often superior to previous technical methods, and more convenient to operate and apply. Since the pre-trained model has achieved such good results, why do we still need Prompt Learning? This can be interpreted from two aspects. In the field of natural language processing, traditional machine learning algorithms often require a large amount of manually labeled data to train a good model on a large corpus. However, these data usually require the annotation processing or guidance of domain experts, which is costly, and the attention of humans is also limited, which leads to insufficient training data and unstable data quality, resulting in a decline in model performance. On the other hand, with the continuous development of artificial intelligence technology, many natural language processing tasks can be solved through pre-trained language models (Pretrained Language Model), which are trained on large-scale corpus and have good performance and generalization ability. However, these pre-trained models are usually only applicable to specific tasks and datasets and cannot be used directly for new tasks. In many cases, business experts need to fine-tune based on task requirements to achieve better performance, which cannot fully utilize the capabilities of pre-trained language models. Therefore, researchers have started to explore how to use automated technology and pre-trained models to solve these problems in one-stop. Among them, Prompt Learning is a widely researched and applied technology, which introduces Prompt templates to transform the original input into a format similar to a cloze test, allowing the language model to answer and infer the results of downstream tasks. Since the proposal of Prompt Learning technology, it has quickly attracted the attention of researchers and related professionals, and has been deeply studied and explored in multiple directions, from the initial manual design of Prompt to the subsequent adaptive optimization learning Prompt, and to a series of more refined and complex Prompt designs.Students interested in this can pay attention to its technical context, and perhaps you will have a sudden realization, "I didn't know it could be implemented like this!" Here, we will not elaborate on it in detail. Currently, when talking about the most popular AI technology, it is undoubtedly the ChatGPT released by OPENAI, which, upon its release, has directly caused a wave of artificial intelligence, even having a disruptive impact in many fields. Prompt Learning is one of the important principle modules, which will be combined with this article to demonstrate and mention at the end.
3 How to carry out Prompt Learning
We may find that in most actual working scenarios, it is usuallyIt is not possible to obtain a lot of supervised training dataEven without any available task data, the needs of such weakly supervised and unsupervised application scenarios are often more in line with our production scenarios. At this moment, how can we meet the task requirements? Prompt Learning undoubtedly gives us a better solution. Here, the author takes the classification task as an example, combining a scenario task to elaborate on how to carry out Prompt Learning in detail.
Firstly, find a public news text classification dataset containing "Culture", "Finance", "Sports", "Entertainment", and other 15 categories, with a total of 600 sample data. The following are 3 sample data:
{"text": "How many branches does China Railway Construction have?", "label_name": "Finance", "label": 3}
{"text": "The ten most famous handguns in the world", "label_name": "Military", "label": 8}
{"text": "How should high school students review?", "label_name": "Education", "label": 6}
By using these data, we can model a text classification task, build a model for training and prediction of its category. However, since the sample data only has 600 entries, the fine-tuned model obtained from training may not be stable, and it is easy to overfit, making the model actually unusable. Weakly supervised learning may be a better solution. According to the principles of Prompt Learning, we adjust and transform the task data, building a cloze test task to let the model provide the corresponding answers, whileIt is no longer a direct text classification output category label and mapping it back to the corresponding category. One of the Prompt data transformation methods that can be used is as follows:
{“text”: “This is a ______ news,”+”How many bureaus does China Railway Construction Corporation have?”, “answer”: “Finance”}
{“text”: “This is a ______ news,”+”The world's ten most famous handguns”, “answer “: “Military”}
{“text”: “This is a ______ news,”+”How to review for high school students?”, ”answer “: “Education”}
We expect the model to be able to directly predict and output the category answer of the text data, such as the first sample data, the model's output is “Finance”. The form of the Prompt data already conforms to the training paradigm of the language model, and it can be directly used to predict and output the answers of cloze test with pre-trained language models such as BERT. Of course, it can also be based on the transformed data to further fine-tune the BERT model with language model (LM) pre-training,The BERT model after training usually has better prediction output performance. If the language model is strong enough, direct prediction and output based on the constructed Prompt data can generally achieve better results, and changing different Prompts can even complete multiple different scene task requirements (classification, Q&A, dialogue, translation...), such as “Translate the sentence into English, how many bureaus does China Railway Construction Corporation have?”, the model will directly infer and predict the English translation “How many bureaus does China Railway Construction Corporation have?”.
The author conducted Prompt-Tuning fine-tuning training based on the above classification tasks, which improved the overall performance by about 3 points on average compared to directly building a model for classification tasks, andThe generalization performance of the model method is relatively stronger. The experimental test is a method called Pattern Exploit Training (PET) [2]The training method is one of the earliest representative methods of the Prompt series. Of course, according to the author's practical experience, the performance improvement here is not absolute, it may also be slightly worse, but the generalization ability of the model will generally be significantly improved. The Prompt Learning model method is generally superior to the same type of task supervised models in the Few-shot and Zero-shot scenarios, and sometimes it may also perform better in supervised learning tasks.
4 A Small Test of ChatGPT
Around 2020, the earliest Prompt series methods such as PET model training methods were proposed, and in just 2 years,The Complete Master of Technology - The ChatGPT Model is Launched. ChatGPT is an optimized large-scale pre-trained conversational language model that has led to a surge in the attention of large model research since its release and launch last November. Both domestically and internationally, many similar version models have emerged. We submitted the same test question from the previous chapter to the ChatGPT model to see its effect. Due to many magical restriction factors, the model we experienced for testing is Claude, which was publicly released by Anthropic, and the test results are as follows:
- Determine the type of data

- Other task types Prompt experience

For the example question provided in the previous chapter, the Claude model can directly provide the expected answer without any training fine-tuning, simply by specifying the output range and form in the Prompt, thus ensuring that the output results meet expectations. At the same time, by introducing different Prompt task requirements, the Claude model can directly output results such as translation translations. The core content lies in the construction and application of different Prompt data patterns.
Since Prompt Learning is so powerful and has even become the 'universal key' when combined with large-scale language models, it can solve many modeling problems in one go. Then, can we directly adopt the 'imported model' approach and directly adapt it to our business field scenarios? The author believes that this is definitely not the case, and the two most core issues are data security and cost issues.
In combination with specific business scenarios, the deployment and application of large models like ChatGPT often require high costs, at least that is the case for the time being; at the same time, once directly adopting large models like ChatGPT, data security will be a more severe challenge, as the data used is directly exposed to the outside, which is an issue that many enterprises and users are definitely unable to accept. At the same time, as a practitioner in the field of cybersecurity, the author finds that there is little research on large models in the vertical field of this industry, which may indeed be closely related to the industry attributes and data characteristics. If there were a mature large-scale language model in the security field that could assist in solving many security modeling tasks such as threat intelligence analysis, tracing, and sensitive information identification, this might be a very anticipated event. Each vertical industry field may hope to have such large models, or general large-scale language models converging towards application in the field, which should be an important development direction for research and industry attention and implementation in the coming years!
5 Conclusion
AlphaGo is an artificial intelligence Go program developed by DeepMind (a subsidiary of Google). In 2016, AlphaGo successfully defeated the world-renowned Go master Lee Sedol in a historic match, becoming the first artificial intelligence program to defeat a human world champion in a public competition. This momentous AlphaGo was also achieved through the method of reinforcement learning:
- Initial Training
AlphaGo first uses millions of human Go match data for initial training. This data is obtained from Internet Go websites. Through this data, AlphaGo trains a deep neural network to learn to predict the moves of human players. This neural network is called the strategy network, which can provide the probability of each possible move in the current game state.
- Self-play
AlphaGo performs self-play for reinforcement learning. That is, two identical AlphaGo copies compete against each other. After each game, the neural network parameters are updated based on the game results. During this process, AlphaGo learns how to place stones, not only considering the current game state but also considering future possible moves, thus optimizing long-term rewards. This process generates a new neural network called the value network, which can evaluate the probability of winning the game in the current game state.
- Monte Carlo Tree Search
In actual gameplay, AlphaGo selects moves by combining strategy networks and value networks with Monte Carlo Tree Search (MCTS). The strategy network is used to narrow the search space and provide possible good moves, while the value network is used to evaluate the game state after various moves. In this way, AlphaGo can balance exploration and exploitation and choose the moves most likely to win the game.
Through these methods, AlphaGo can find excellent strategies in the highly complex game of Go and defeat top human players.
6 Training of ChatGPT (RLFH)
Although the application of large models like ChatGPT may still have many limitations, it must be said that the emergence of such large models has made Prompt Learning increasingly popular, even giving rise to a new profession called Prompt Engineer. Prompt Learning is undoubtedly a technology that deserves more attention and study. In practical production scenarios, when we are faced with problems similar to low-resource issues, why not try this series of Prompt-based methods? Perhaps it will give you a moment of enlightenment!
7 References
[1] Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.
[2] Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference.
GPT-3: in-context learning + few-shot learning, 175 billion parameters, 96 layers, 500 billion words
Git leak && AWS AKSK && AWS Lambda cli && Function Information Leakage && JWT secret leak
2025 latest & emulator WeChat mini-program packet capture & mini-program reverse engineering
AI Large Model Security: Prompt Injection Attack (Prompt Injection Attack)

评论已关闭