Author: Li Junbing, JD Technology
Hello, everyone, I am the Ball God (code name in the江湖).

Since ChatGPT was launched on November 30th last year, it has quickly become popular beyond the circle.
At first, I still thought this was just like the 'hot' model like Transformer and Bert in the past, but as more and more articles/reports were pushed in front of me, I realized too late that this time it is really different.
A very direct point is that ChatGPT has affected everyone, whether they are in AI, Internet, or computer fields.
You will see that many bigwigs in the tech industry, such as Musk, Nadella, Lee Kuan Yew, Li Yanhong, Zhou Hongyi, etc., are all claiming that ChatGPT will change the world;
Too many Internet companies, such as Microsoft, Google, Baidu, Alibaba, Tencent, etc., are vying for the commercial opportunity;
More academic institutions and universities have also started to discuss whether the papers generated by ChatGPT conform to academic norms;
Suddenly, professionals from all walks of life began to worry about being replaced by ChatGPT...
「At first glance, it seemed to be a hot topic, but after a second look, it has become a classic...」
So I decided to study it thoroughly and strive to write it in a comprehensive and easy-to-understand manner, which eventually led to this ten-thousand-word long report. It is recommended to save and read it slowly.
The theme of this article is about:「The AI background, technical insights, and commercial applications behind ChatGPT.»

The following is the table of contents and main content:
Introduction
My little story with the chatbot
I. AI Background
1.1 The Breakout and Capability Circle of ChatGPT
1.2 Brief History of the Development of Artificial Intelligence
1.3 The NLP and Transformer Behind ChatGPT
Second, technical secrets
2.1 The evolution and technical principles from GPT-1 to ChatGPT
2.2 Limitations of ChatGPT
2.3 Exploration and optimization directions of ChatGPT
3. Business applications
3.1 Capital investment at home and abroad is increasing layer by layer
3.2 The curtain has been opened for the commercialization of ChatGPT
3.3 ChatGPT helps AIGC surge again
Postscript
Will ChatGPT lead the fourth technological revolution?
Will ChatGPT bring about a wave of unemployment for humans?
Is ChatGPT suitable for starting a business?
Are there investment opportunities in the ChatGPT and AIGC industry chain?
References
Brief introduction of the author's background
Introduction
My little story with the chatbot
As early as the end of 2017 to the first half of 2018, when I just got the entrance ticket to the graduate program in computer science, I also needed to complete my undergraduate graduation project. Therefore, I chose to enter the graduate laboratory early and bring back a graduation project topic: Chinese text dialogue system (commonly known as: chatbot).
That's right, from the perspective of research direction, the main topic of this article, ChatGPT, exactly falls into the research scope I was focusing on back then — Natural Language Processing (NLP). However, later on, due to some uncontrollable factors, I became more interested in the fields of machine learning and computer vision.
I still remember when I was writing my undergraduate thesis and giving the defense, my Chinese text chatbot (based on Seq2Seq + Attention architecture) was quite primitive: it could only maintain 4-5 rounds of dialogue logic; it would become incoherent when answering difficult questions; and the text of the dialogue could not be too long...
Although in 2017, the Transformer architecture had already been introduced, at that time, even first-line researchers and engineers might have found it hard to imagine that five years later, in 2022, a phenomenon-level general chatbot program like ChatGPT would appear.
"The development of science and technology is not uniform, but appears in the form of waves." --- 'The Crest of the Wave', Wu Jun
First, AI Background
1.1 The Breakout and Capability Circle of ChatGPT
Although ChatGPT has become so popular that many people are crazy about it, we still hope to calm down and carefully look at what it can actually do now, and where its boundaries are.

The time required for the monthly active users of major popular platforms to exceed 100 million
First, let's look at the actual application test results of the product:
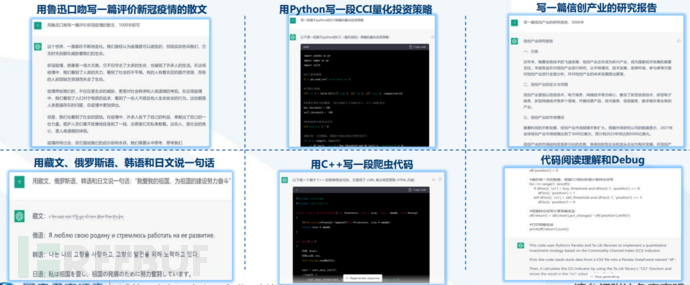
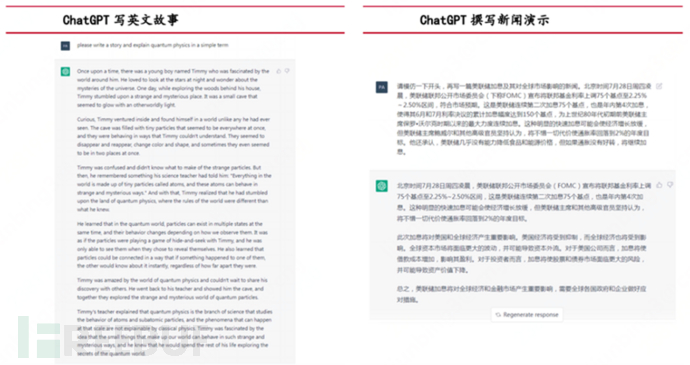
Let's take a look at the deep-level capabilities abstracted from the product performance behind it:
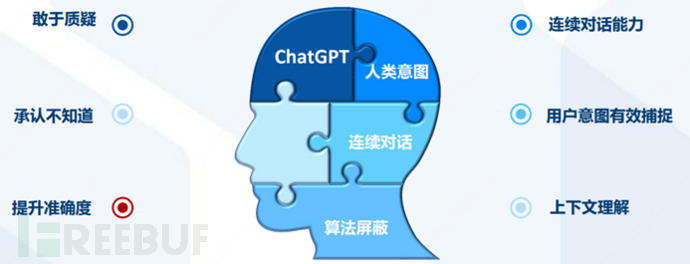
Therefore, in the two and a half months since its launch, ChatGPT has proven that its capabilities include: automatic question answering, multi-round chat, article creation, language translation, text summarization, coding, and debugging, and these surface capabilities reflect its deep-level abilities such as understanding human intentions, being bold in questioning, admitting ignorance, and continuously learning and evolving.
And these capabilities have far exceeded those of other AI robots in the past, and have been unanimously recognized by AI researchers, engineers, and industry experts in various fields.
Admit it, from multiple dimensions such as single-item performance, overall functional coverage, stability, timeliness, and robustness, the current ChatGPT is already enough to颠覆, it makes it possible for the research and industrialization of general AI.
1.2 Brief History of the Development of Artificial Intelligence
When it comes to artificial intelligence and computer science, there is always a name that cannot be avoided.
He is the British Alan Turing (Alan Turing, 1912-1954).
In the year of Alan Turing's birth (1912), his homeland was in the heyday of the 'Sun Never Sets', with colonies occupying more than a hundred times the area of the motherland. In the distant east, the Provisional Government of the Republic of China was established in Nanjing, and Mr. Sun Yat-sen took office as the Provisional President, marking the beginning of the revolutionary复兴 of the Chinese nation (「ChatGPT should not be able to write this section」)。
In 1950, at the age of 38, Alan Turing had already made significant achievements in the fields of mathematics and logic. However, when he proposed the famous 'Turing Test' concept in his paper 'Computers and Intelligence,' people in later generations would never forget his outstanding contributions to the fields of artificial intelligence and computer science.
"If a third party cannot distinguish the difference between the reaction of a human and an artificial intelligence machine, then it can be concluded that the machine possesses artificial intelligence." --- Alan Turing, the Father of Artificial Intelligence
In August 1956, at Dartmouth College in the United States, scientists such as John McCarthy, Marvin Minsky, Claude Shannon, Allen Newell, and Herbert Simon discussed using machines to imitate human learning and other aspects of intelligence. They first proposed the concept of 'artificial intelligence', marking the birth of the discipline of artificial intelligence.
Since then, the development of artificial intelligence has gone through four major waves.
The First Wave (1956-1980): From Initial Prosperity to Low Point
In the first generation of AI, computers were used in fields such as proving mathematical theorems and solving algebraic application problems. During this period, theories such as perceptrons (1957), pattern recognition (1961), human-computer dialogue (1966), expert systems (1968), and visual computing (1976) were proposed one after another.
The good times did not last long. Experts and scholars found that logical reasoning alone was far from enough to realize artificial intelligence. Many difficult problems were not solved over time, and many AI systems have remained at the toy stage. The previous over-optimism led people to have high expectations, but without substantial progress, many institutions gradually stopped funding AI research. Artificial intelligence encountered the first trough.
The Second Wave (1980-1995): From Second Resurgence to Depression
In the AI 2.0 era, expert systems and multi-layer neural networks were widely applied, and human-computer dialogue robots and voice-controlled typewriters gradually appeared. During this period, Bayesian networks (1985), backpropagation (BP, 1986), support vector machines (SVM, 1995), and other algorithms were proposed one after another.
However, problems such as narrow application fields, difficult knowledge acquisition, and high maintenance costs of expert systems began to emerge. AI development encountered a series of financial problems and entered the second trough.
The Third Wave (1995-2010): Accumulating Strength in Stability
Since the mid-1990s, with the rapid development of computer performance and the accumulation of massive data, the development of artificial intelligence officially entered the modern AI era.
In 1997, IBM's chess-playing robot Deep Blue defeated the world chess champion Garry Kasparov, causing a sensation worldwide. Subsequently, conditional random fields (CRF, 2001), deep learning (Deep Learning, 2006), transfer learning (Transfer Learning, 2010), and other theories were proposed one after another.
The Fourth Wave (2010 to present): From Outbreak to Peak
Since the second decade of the 21st century, the industrial sector has begun to launch practical artificial intelligence products and applications one after another.
In February 2011, IBM's question-answering robot Watson defeated two human champion contestants on the American quiz show 'Jeopardy!'.
In October 2012, Microsoft showcased an automatic simultaneous interpretation system at the '21st Century Computing' conference, which could convert the English speech of the speaker into Chinese with a similar tone and clear pronunciation in real-time.
In March 2016, Google's Go artificial intelligence system AlphaGo engaged in a man vs. machine battle with the world champion of Go, professional nine-dan player Lee Sedol, and won with a total score of 4:1.
Subsequently, at the end of 2016 and the beginning of 2017, AlphaGo successively played rapid games against dozens of top Go players from China, Japan, and South Korea, winning 60 games without a single defeat, including a 3:0 complete victory over the world's number one, Chinese player Ke Jie.
Correspondingly, the AI academic community has been a hundred schools of thought contending for more than ten years, each displaying its unique skills.
In 2012, Hinton (one of the three giants of deep learning) and his student Alex Krizhevsky designed the first deep convolutional neural network---AlexNet, and won the championship of that year's ImageNet image classification competition.
Since then, CV people have successively proposed base models such as VGGNet (2014), Inception Net (2014), ResNet (2015), Fast RCNN (2015), YOLO (2015), Mask RCNN (2017), MobileNet (2017), etc., leading the rapid development in fields such as image classification, face recognition, object detection, image segmentation, and video understanding.
People in the field of NLP are not willing to be outdone, and they first designed tools like Word2Vec (2013) that can convert words into vector representations, and then used LSTM (1997) series recurrent neural networks, based on the architecture of Seq2Seq (2014) + Attention (2015), to achieve complex tasks such as machine translation and dialogue systems, and further proposed the big killer Transformer in 2017, while also advancing the BERT (2018) series of larger models with better performance and stability.
There is also another group of persistent AI enthusiasts who focus more on deep generative network models. From Variational Autoencoder (VAE, 2013) to Generative Adversarial Network (GAN, 2014), to Denoising Diffusion Model (DDPM, 2020) and Generative Pre-trained Transformer (GPT series, 2018-present), these innovative models have truly driven the rapid development of AIGC (Generative Artificial Intelligence Technology) in the industry.
In 2017, Microsoft's 'Xiao Ice' launched the world's first poetry collection created by artificial intelligence, 'Sunlight Lost Its Glass Window'; in 2018, Nvidia released the StyleGAN model that can automatically generate high-quality images; in 2019, Deep Mind released the DVD-GAN model that can generate continuous videos; until November 30, 2022, OpenAI released ChatGPT, and the protagonist of this article finally made its official debut.

The history of artificial intelligence development is also the history of the development of information technology revolution.
The difference is that, when artificial intelligence reaches a certain stage, it may ultimately颠覆 the informatization era of 'machines helping people' and lead the intelligent era of 'machines replacing people'.
「Perhaps, many years later, we will see that ChatGPT is one of the iconic events marking the beginning of the fourth technological revolution.」
1.3 The NLP and Transformer Behind ChatGPT
After understanding the scope of ChatGPT's capabilities and the history of the development of artificial intelligence, non-AI professionals can also understand that the research of ChatGPT belongs to the field of Natural Language Processing (NLP).
Natural Language Processing (NLP) is被誉为“人工智能皇冠上的明珠”,on the one hand, indicating its importance, and on the other hand, highlighting its technical difficulty.
In simple terms, what NLP aims to do is to use computers to realize the intelligent processing, analysis, and generation of natural language data, in order to enable computers to achieve the language abilities possessed by humans, such as listening, speaking, reading, writing, and translation.
More specifically, according to different downstream tasks, the NLP field mainly includes the following research directions:

Careful readers have already noticed that ChatGPT has basically achieved the intermediate goals of the above 7 major categories of tasks, so it is not without reason for NLP researchers and engineers to worry that they are inventing tools that are taking their own livelihood, and other workers in industries with low technical content are even more trembling.
The development of NLP has also gone through three major stages, namely, the first stage represented by rule learning (1960-1990), the second stage represented by statistical learning (1990-2010), and the third stage represented by deep learning (2010 to the present).
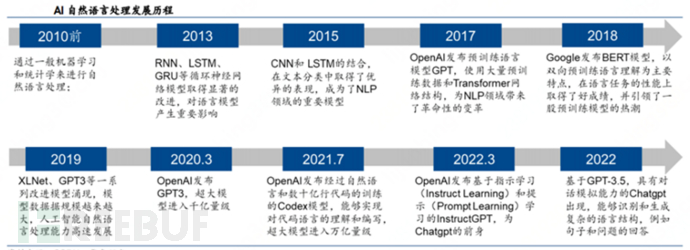
Among them, the architecture of Transformer undoubtedly has a significant impact on the generation of ChatGPT and other large language models.
It can be said that the emergence of Transformer has completely opened up the space for large-scale pre-trained language models (Pre-trained Language Model, PLM) and has laid the rules of the game for generative AI.
In 2017, the Google Machine Translation team published the paper 'Attention is All You Need' at the top machine learning conference NIPS, and the core of the article was the Transformer model.
The novelty of Transformer compared to previous papers lies in: boldly discarding the traditional CNN and RNN basic models, and the entire network structure is composed entirely of Attention mechanisms. More accurately, Transformer is composed of and only composed of self-Attention mechanisms and feed-forward neural networks.
From the perspective of practical applications, the main contributions of Transformer are as follows:
1. It has broken through the limitation that RNN models cannot be computed in parallel
2. The precision and model complexity are superior compared to the RNN/CNN + Attention series models
3. Transformer itself can also be used as a base model for extension
Looking back on this moment, the Transformer behind ChatGPT, its thoughts and architecture exactly prove that:The way to the Tao is simple.
It first achieved SOTA in machine translation tasks, and then successfully applied to various tasks such as NLP and CV, and achieved stable and excellent performance.
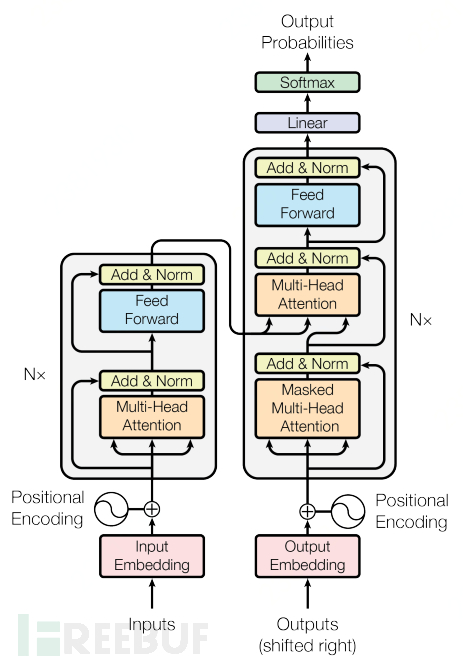
Transformer model architecture diagram
The story that followed is well-known to many, with Google people continuing to strive, and the BERT (Bidirectional Encoder Representation from Transformers) model proposed in October 2018 once again caused a stir in the industry.
BERT achieved astonishing results in the top-level machine reading comprehension test SQuAD1.1: fully surpassing humans in all two measurement indicators, and creating SOTA (state-of-the-art) performance in 11 different NLP tests, including raising the GLUE benchmark to 80.4% (absolute improvement of 7.6%), and achieving an accuracy of 86.7% in MultiNLI (absolute improvement of 5.6%), becoming a milestone achievement in the history of NLP development.
While everyone thought Google would dominate the large language model track, it was ultimately the GPT series models from OpenAI that became widely known to the world first.

Second, technical secrets
2.1 The evolution and technical principles from GPT-1 to ChatGPT
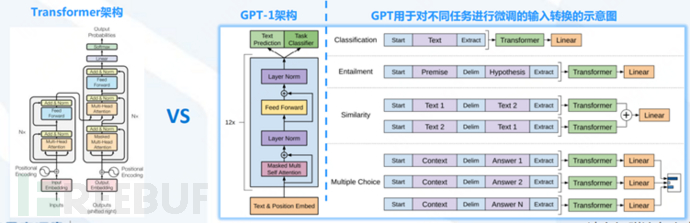
The GPT (Generative Pre-training Transformer) series models first took a detour from BERT, despite the fact that GPT-1 (June 2018) was released earlier than BERT (October 2018).
BERT only used the encoding (Encoder) part of Transformer for training, while GPT-1 only used the decoding (Decoder) part of Transformer.
As a result, both have taken different paths.
GPT-1: Pre-training + fine-tuning mode, 117M parameters, 12 layers, 200 million words
Original text: Improving Language Understanding by Generative Pre-Training
Pre-training phase: Based on the Transformer Decoder architecture, language modeling is used as the training goal (self-supervised, predicting unknown words based on known words).
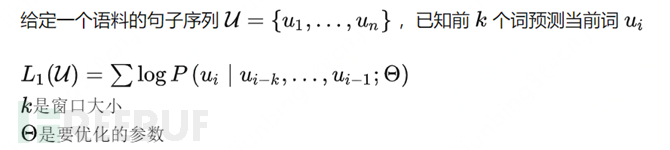
Fine-tuning phase: Fix the trained Decoder parameters, add a linear layer on top, and fine-tune the parameters of the linear layer through supervised training tasks to make predictions.

The limitations of GPT-1: Fine-tuning can only be used for specific tasks; if fine-tune a classification task, it cannot be used in the sentence similarity task.
So, can a single model be used to perform all NLP tasks?
This is the goal of improvement for subsequent GPT-2 and GPT-3.
GPT-2: Multitask learning + zero-shot learning, 1542M parameters, 48 layers, 40 billion words
Original: Language Models are Unsupervised Multitask Learners
The goal of GPT-2 is to try to use a single model to perform multiple NLP tasks, and its core idea is reflected in the title of the paper: Language Model = Unsupervised Multitask Learning.
To put it simply: a language model is actually a form of self-supervised learning, predicting unknown words based on known words, without explicitly defining which fields are to be predicted as output. How can we achieve the effect of language model self-supervised training + multi-task fine-tuning through unsupervised multi-task training? We just need to represent input, output, and task as data, for example, in a task of translating English into French, we just need to represent the samples, labels, and tasks in the following format, thus realizing the translation ofP(output|input,task)of modeling.
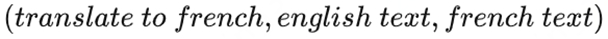
Importantly, this method can realize unsupervised training, and the tasks inside can change, which means that now GPT-2 can achieve unsupervised multi-task training without the need for supervised fine-tuning in the second stage for different tasks!
Therefore, we see that the biggest improvement of GPT-2 compared to GPT-1 is the removal of the fine-tuning layer in the second stage, achieving multi-task training and zero-shot method (Zero-shot learning) directly connecting to many downstream tasks, and achieving good results under multiple tasks.
Of course, it is also evident that adjustments have been made to the dataset, the number of network layers, the amount of parameters, the size of the vocabulary, initialization, and LN (layer normalization).
GPT-3: in-context learning + few-shot learning, 175 billion parameters, 96 layers, 500 billion words
Original: Language Models Are Few-shot Learners
GPT-3 basically inherits the model architecture and training mode of GPT-2, in addition to the massive amount of data and gigantic parameters that have produced miracles, the main improvements of GPT-3 in terms of model design compared to GPT-1 and GPT-2 are: in-context learning (ICL) and few-shot learning (FSL) working in combination.
We know that both GPT-1 and BERT need to be fine-tuned for downstream tasks, while GPT-2 gives up fine-tuning through unsupervised multi-task and zero-shot learning and has been verified to have superior performance. Can we continue to improve without the need for fine-tuning?
The answer is yes, by introducing the in-context learning (contextual learning) mechanism.
This mechanism can be understood as adding a certain amount of prior knowledge to the model, appropriately guiding the model, and teaching it what content should be output.
For example, if you want GPT3 to help you translate Chinese into English, you can ask him like this:
User input to GPT3: Please translate the following Chinese into English: Do you think the ball god is handsome?
If you want GPT3 to answer your question, you can ask in a different way:
User input to GPT3: Model, model, tell me: Do you think the ball god is handsome?
In this way, the model can respond specifically based on the context provided by the user's prompt.
Here, it is only told how the model should do, can you give an example first?
User input to GPT-3: Please answer the following question: Do you think the ball god is handsome? => I think he is quite handsome; Do you think Kobe is better at playing basketball than Irving? =>
Among them, the example of asking whether the ball god is handsome or not is used to make the model aware of what output should be generated.
Based on the above, providing only a prompt is called zero-shot, providing one example is called one-shot, and providing a few multiple examples is called few-shot.
Professional readers should be able to notice that the in-context learning (contextual learning) provided here is very similar to the idea of prompt learning (prompt-based learning).
GPT-3's paper provides a comparison of performance among 3 versions:
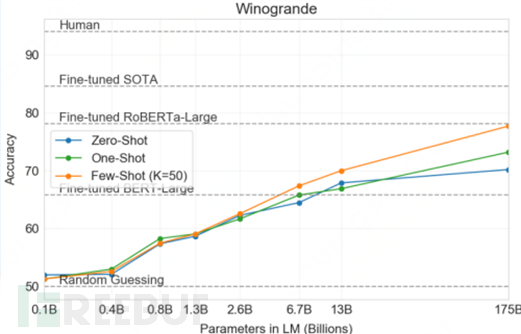
It is obvious that in-context learning (learning in context) combined with few-shot learning (learning with a few examples) works better.
InstructGPT: RLHF (Reinforcement Learning with Human Feedback) + PPO (Proximal Policy Optimization)
Original: Training language models to follow instructions with human feedback
InstructGPT addresses the problem of large model alignment (alignment) compared to GPT-3. The background is that large language models may generate some outputs that are unrealistic, toxic (not in line with human morality and ethics, etc.), or completely unhelpful to users, which are obviously inconsistent with user expectations.
Large models have seen all kinds of data during the pre-training process, so for a prompt/instruct (prompt), the output may be diverse. However, the data patterns that appear in the pre-training data do not necessarily represent the patterns that humans hope to see when using the model, so an alignment (alignment) process is needed to规范 the model's 'words and actions'.
And to achieve this process, InstructGPT introduces the RLHF mechanism (human feedback reinforcement learning), which actually made full use of reinforcement learning six years ago, and achieved invincible hands in the field of Go.
In simple terms, InstructGPT is a fine-tuning on the basis of GPT-3 using the RLHF mechanism (human feedback reinforcement learning) to solve the alignment problem (alignment) of large models.
Let's first think about how to solve the problem of mismatch between the model's output and human expectations?
The most direct way is to manually construct a large amount of data (prompt and expected output written by annotators themselves), which fully conforms to the pattern of human expectations, and then hand it over to the model to learn. However, this cost is obviously too high. Therefore, we need to figure out how to make this process easier, and the RLHF mechanism (human feedback reinforcement learning) has achieved this.
Below is the flowchart of InstructGPT, understanding it will also help understand how the RLHF mechanism is implemented.
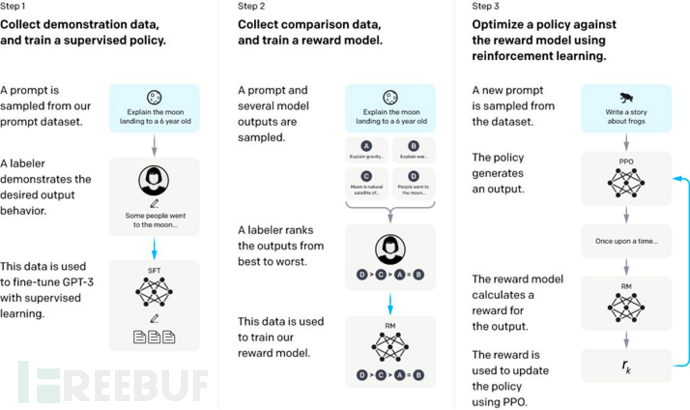
Step-1: The initial model is called V0, which is GPT-3. We can first manually construct a batch of data, not necessarily a large amount, as much as possible, and then let the model learn first, which is called V1 at this time.
Step-2: Then let the model output according to a lot of prompts (tips) and see how the effect is. We let the model V1 output multiple times for a prompt, and then let people score and sort the multiple outputs. Although the sorting process also requires manual work, it is much more convenient than directly writing training data for people, so more data can be labeled more easily. However, this labeled data cannot be directly used to train the model because it is a sorting, but we can train a scoring model called RM (reward-model, also known as reward model), whose role is to score a <prompt,output> pair and evaluate whether the output matches the prompt.
Step-3: Next, we continue to train the V1 model (wrapped by a strategy and updated with PPO), given some prompts, obtain the output, then input the prompt and output to RM to get a score. Then, with the method of reinforcement learning, we train the V1 model (the score will be given to the strategy wrapping the V0 model core to update the gradient), and iterate repeatedly, finally refining to get the V2 model, which is the final InstructGPT.
Overall understanding: The whole process is that the teacher (human annotator) first injects some essential knowledge, then lets the model try to imitate the teacher's preferences to make some attempts, then the teacher scores these attempts of the model, learns a scoring machine, and finally, the scoring machine can work with the model to automate the iteration of the model. The overall idea is called RLHF: reinforcement learning based on human feedback.
Among them, the PPO mechanism (Proximal Policy Optimization, near-end policy optimization) is a classic algorithm in reinforcement learning's AC class (Actor/Critic), proposed by OpenAI in 2017. It has the advantages of Policy Gradient methods and, based on importance sampling, utilizes the experience buffer, playing the data utilization advantages of similar DQN algorithms.
PPO is a commonly used baseline method by OpenAI, with a theoretically complex part. Readers who are interested in the professional aspects can read the original text and related blogs.
Original: Proximal policy optimization algorithms
Non-professional readers only need to understand that this is a strategy optimization algorithm that completes the entire process training through a human feedback reinforcement learning (RLHF) mechanism.
By decomposing the above process, we can easily find that InstructGPT can achieve better performance through this RLHF mechanism, with one big premise: that the initial model GPT-3 is already strong enough.
Only when the initial model itself is strong can a small amount of精华 data provided by humans start to imitate, and at the same time, a more reasonable output can be produced in the second step for human scoring.


ChatGPT: An upgraded version of InstructGPT for chatting
According to the official introduction of OpenAI, the ChatGPT released in November 2022 and the InstructGPT released in February 2022 have the same model structure and training methods, but there are differences in the way of data collection. However, there is currently no more information on the specific details of the differences in data collection.
Therefore, the technical principles of ChatGPT are basically the same as those of its little brother InstructGPT, which is equivalent to being a pre-release version of ChatGPT, also known as GPT3.5. The rumored GPT-4 is a multimodal model (capable of handling image + text + voice and other multimodal data), and we are looking forward to it.
So far, the evolution and technical principles from GPT-1 to ChatGPT have been explained quite thoroughly.
import is a bit exhausting
Finally, here is an Instruct/ChatGPT Chinese architecture flowchart for a clearer and more understandable view.
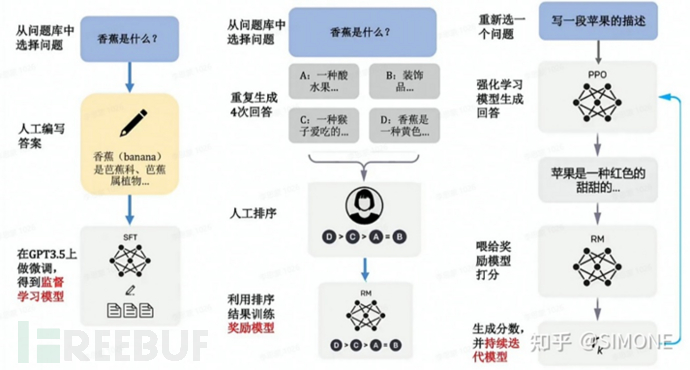
2.2 Limitations of ChatGPT
Although ChatGPT is already sufficiently artificial intelligence, under the judgment of many real intelligent humans, it still has many limitations at present.
Functional limitations
1. Sometimes the answers may contain factual errors
2. There may still be content that is biased and not aligned with human moral and ethical standards
3. There is no connection with real-time information
4. Sometimes it is sensitive to the way of expressing the input
5. Sometimes the answers are too long-winded
The above limitations are mainly based on the following compound reasons:
1. ChatGPT and all machine learning models are based on existing data, knowledge, associations, tags, etc. to make predictions, so as long as it has dependencies and makes probabilistic predictions, errors, inaccuracies, and biased answers theoretically exist, only the issues of precision and recall;
2. The accuracy, expression level, and 'values' of ChatGPT's manual annotation (including instructions and outputs) can still be improved, and the current AI alignment method -- RLHF mechanism may not be the optimal one;
3. The information update of ChatGPT stopped at 2021, and it currently cannot connect to search engines to provide the latest and most real-time information to users.
Technical limitations
1. No matter how large the model is, it cannot be infinitely large
2. The model is greatly affected by the reward model and manual annotation
These are the two major pain points of ChatGPT's technical architecture, and also the two major difficult problems in the fields of deep learning and reinforcement learning research at present.
Other limitations
1. Data and computing power bring about technological monopoly
The data and computing power required for ChatGPT training make players basically domestic and foreign technology giants. Moreover, ChatGPT will not be open-sourced at present, which makes schools and small and medium-sized AI enterprises unable to conduct research, which is not conducive to the progress of ChatGPT itself.
2. Balancing lightweighting and performance
The parameter volume of ChatGPT has reached the billion level, and such a large model is obviously not suitable for large-scale real-world applications. Subsequent lightweight model research is unavoidable, and balancing lightweighting and performance is also a huge challenge.
3. AI credibility behind interpretability
Although ChatGPT performs surprisingly well in various NLP tasks, the model itself is still like a black box, and interpretability is still a point that professional algorithmic people need to explore deeply, and users still expect a more trustworthy AI.
2.3 Exploration and optimization directions of ChatGPT
1. Multi-modal expansion
The capabilities currently demonstrated by ChatGPT are mainly in the text domain and a small part of cross-modal/content generation.
The next trend is already very clear: integrating multi-modal understanding and generation capabilities of text, images, voice, and video, thinking and processing multi-modally like humans.
RLHF is not the only AI alignment technology; there are still many methods and strategies to explore for AI alignment in reinforcement learning.
3. Enhancing the generalization and error correction capabilities of prompts
In addition to the manually annotated labels (ground truth), ChatGPT also relies heavily on prompts, which further improves the generalization ability of the model to prompts and the ability to correct incorrect prompts. This not only improves the user experience when using the model but also enables the model to adapt to a wider range of application scenarios.
4. Exploration of model lightweighting technology
Since the effectiveness of deep learning frameworks has been widely verified, in the past 10 years, the overall trend of research work in the CV and NLP fields has been that the number of model layers has become deeper, the number of parameters has increased, and the amount of data has become larger in pursuit of performance.
But in fact, everyone in the industry knows that at some stage, it is necessary to break the circle. Although ChatGPT is performing extremely well now, its large and deep model is obviously not suitable for large-scale real-world scenarios or even for terminal applications. The research on model lightweighting in the future cannot be avoided, and the balance between lightweighting and performance also greatly tests whether AI technology has truly matured.
5. Cost reduction and efficiency improvement through data + computing power + manual annotation
Data, computing power, and algorithms are the three elements of AI. ChatGPT has successfully attached the cost of resources for data and computing power annotated manually to the level that universities, research institutions, and other small AI companies cannot afford, so even though many experts and scholars吐槽 'more effort, more miracles', there is nothing they can do.
Technology seems to have once again gone ahead of science, which is obviously not conducive to the long-term progress of technology itself.
However, from the perspective of large companies such as OpenAI with substantial capital support, they also hope to gradually reduce costs and improve efficiency in the future, after all, the ultimate goal of AI developers is still 'AI, making life better', but there are factors such as technological monopoly and commercial competition mixed in, which will affect the time of realization.
3. Business applications
3.1 Capital investment at home and abroad is increasing layer by layer
In addition to what ChatGPT can do and the technical secrets behind it, people may be more concerned about its future process of productization and commercialization.
For complex and high-input technology to be able to mass produce and commercialize on a large scale, it cannot do without the help of capital.
In fact, the development history of OpenAI has first proven this point.
OpenAI was founded in San Francisco in December 2015 by entrepreneurs Elon Musk, President of American startup incubator Y Combinator, Altiman, and co-founder of the global online payment platform PayPal, Peter Thiel.
Initially, it was positioned as a non-profit AI research company, but in March 2019, OpenAI established a limited partnership called OpenAI LP, officially transitioning to a 'top profit' nature.
The turning point came in July 2019 when Microsoft invested 1 billion US dollars in OpenAI and obtained the authorization for the commercialization of OpenAI's technology.
Therefore, in May 2020, OpenAI successfully released the GPT-3 language model with 175 billion parameters and 45TB of data, which cost about 12 million US dollars just in the training phase.
Money is all you need.

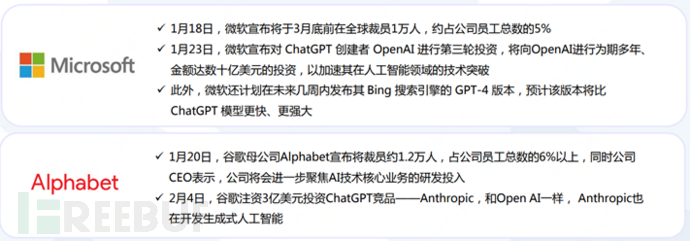
In early 2023, when ChatGPT shone brightly, technology giants at home and abroad such as Microsoft, Google, Amazon, Baidu, Tencent, etc., were even less willing to miss the opportunity. Following this are increased capital and research and development investments, burning money and burning people.

3.2 The curtain has been opened for the commercialization of ChatGPT
On February 1st, Microsoft announced the launch of the advanced paid version of Microsoft Teams Premium, a video conferencing and remote collaboration platform supported by ChatGPT, where subscribers can enjoy the large language model technology supported by OpenAI GPT to automatically generate meeting notes.
On February 2nd, OpenAI announced the launch of the paid subscription version of its artificial intelligence chatbot ChatGPT, named ChatGPT Plus, with a monthly fee of 20 US dollars. The subscription includes access to the chatbot during peak usage times. The current free version will limit user services during high-traffic periods.
On February 8th, Microsoft launched the new version of the search engine Bing and Edge browser supported by the latest technology from OpenAI.
ChatGPT has been used by Amazon in various different job functions, including answering interview questions, writing software code, and creating training documents.
The copywriting automatic generation platform Jasper, whose technical foundation is OpenAI's GPT-3, reached a valuation of 1.5 billion US dollars in just 18 months after its establishment.
On February 7th, Baidu announced that it will complete the internal testing of its ChatGPT product in March and open it to the public, and the project is named Wenxin Yanyi (ERNIEBot).


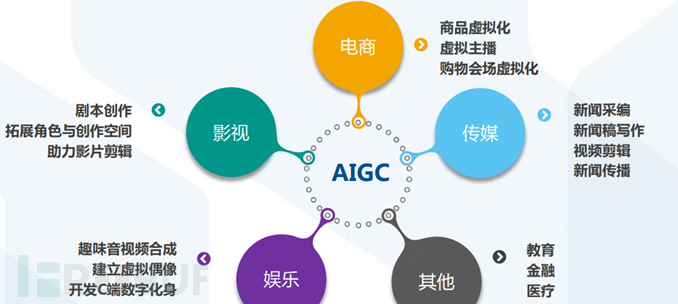
ChatGPT has a wide range of application scenarios and great commercial value, and is expected to empower many industries such as media, film and television, marketing, education, finance, medical research, scientific research, and games.
ChatGPT empowers the media industry: achieve intelligent news writing and enhance the timeliness of news
ChatGPT can help news media workers intelligently generate reports, automate part of the labor-intensive editorial work, and generate content faster, more accurately, and more intelligently.

ChatGPT empowers the film and television industry: broaden creative materials, improve the quality of works
ChatGPT can tailor film and television content according to public interests, thereby more likely to attract public attention and achieve better ratings, box office, and reputation. ChatGPT can provide new ideas for scriptwriting, and creators can screen and process the generated content by ChatGPT for secondary processing, thereby inspiring creators' inspiration, broadening creative ideas, and shortening the creative cycle.
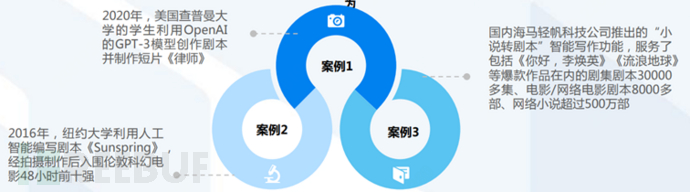
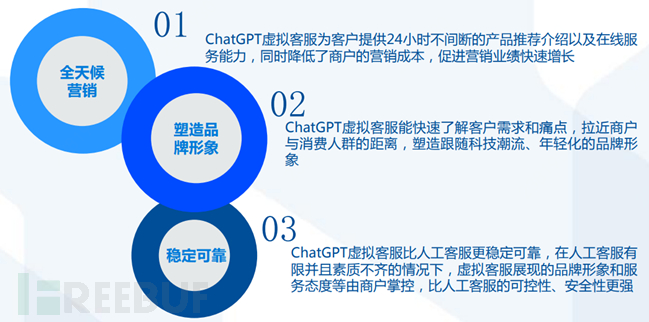
ChatGPT empowers marketing: Creating virtual customer service, helping pre-sales and after-sales
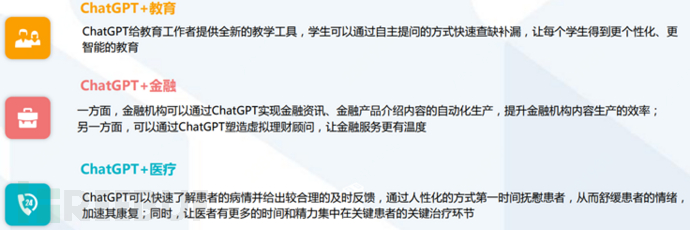
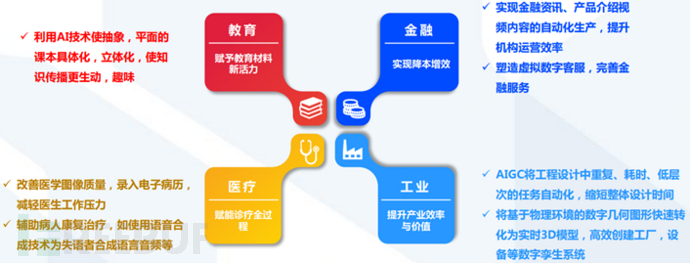
ChatGPT empowers education, finance, and medical care: Promoting the coexistence of digital and real, helping industrial upgrading
ChatGPT + Education: Endowing educational textbooks with new vitality, making educational methods more personalized and intelligent;
ChatGPT + Finance: Help financial institutions reduce costs and improve efficiency, making financial services more warm and friendly;
ChatGPT + Medical: Empowering the whole process of medical treatment in medical institutions.
In addition, ChatGPT and the previously hyped metaverse are obviously quite different.
So far, the metaverse is more like a beautiful idea without actual products and mature models, and the public even cannot understand what the metaverse is supposed to do when looking up information.
But ChatGPT and the generative artificial intelligence (AIGC) behind it not only have products with a strong To C touch like ChatGPT, but also have seen some relatively clear commercialization models as mentioned above.
What is missing now is capital acceleration and technological breakthroughs.
3.3 ChatGPT helps AIGC surge again
AIGC (Artificial Intelligence Generated Context) refers to the use of artificial intelligence technology to generate content, commonly such as AI painting, AI writing, AI-generated images, code, and videos.
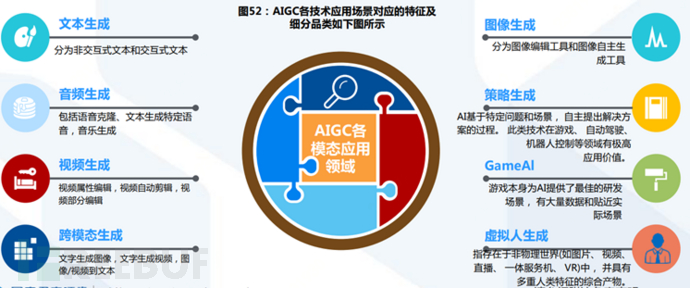
AIGC follows the context of AI development and has roughly gone through three major stages:
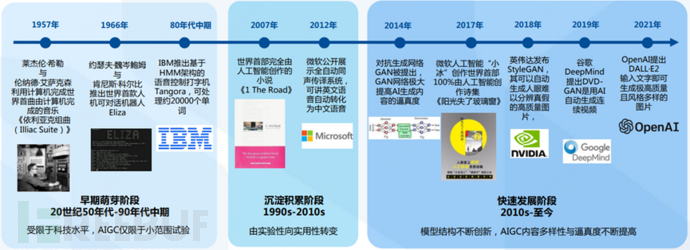
Since 2010, with the rapid breakthrough of deep learning and the massive growth of digital content, the related technologies in the AIGC field have broken through the limitations of predefined rules, and the structure of algorithmic models has been innovatively created, making it possible to quickly and conveniently output multi-modal digital content with intelligence.
From Microsoft Xiaobing's poetry creation in 2017 to Nvidia's StyleGAN generating high-quality images in 2018, and then to Google DeepMind's DVD-E2 generating continuous video in 2019, AIGC is experiencing a period of vigorous development.
Until the protagonist of this article, ChatGPT, appeared at the end of 2022, AIGC finally ushered in a breakthrough inflection point, and a new wave is unfolding slowly.
AIGC application scenarios
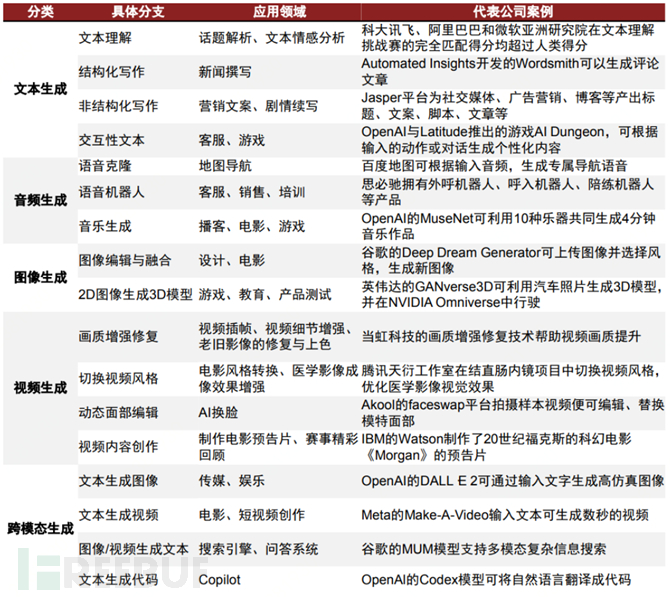
AIGC can be divided into four major categories according to the content generation category: text, code, images, and audio-visual content, while cross-modal generation technology is the core of truly realizing generative intelligence.
The significance of AIGC lies in enhancing content productivity and opening up imaginative spaces for content creation, which may also be the reason why giants are competing to increase their investment in AIGC. From the existing application scenarios, AIGC can already replace some repetitive labor and assist in some creative labor. The development of AI technology in the future is expected to continuously reduce the cost of content production, improve production efficiency, and expand the boundaries of content.
AIGC market space
In 2023, artificial intelligence has gradually moved from academic research to industrialization, and the integration of business and AI technology has formed a development pattern that supports each other, entering the commercial period of industrial-scale application. AI technology will continuously penetrate into various fields of AI digital business.
According to Quantum Leaper's prediction, the AIGC market size is expected to exceed one trillion yuan by 2030. In the content field, human-machine collaboration, for existing businesses, the value of AIGC lies in cost reduction and efficiency improvement, and for incremental businesses, its value lies in cross-modal content generation, etc.
According to Gartner's 'Artificial Intelligence Technology Maturity Curve', generative AI is still in its infancy, but its broad application scenarios and demand space attract a large amount of capital and technology investment, and it is expected to achieve scaled applications within 2-5 years.
AIGC has the potential to generate tens of trillions of yuan in economic value. With the prosperous development of AIGC, asset services will quickly follow suit, through the constitution of AIGC's complete ecosystem chain by generating content compliance assessment, asset management, intellectual property protection, and transaction services, and reshape value, fully releasing its commercial potential, with the scale of China's generative AI commercial applications reaching 207 billion yuan by 2025.
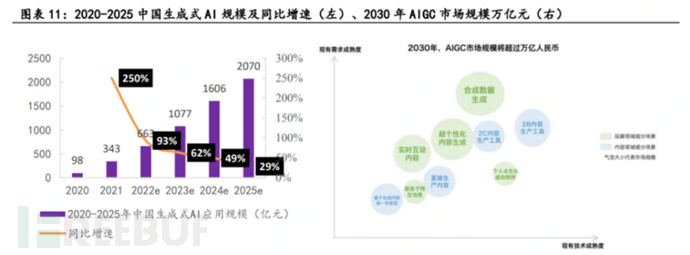
AIGC business model
Although AI has made some significant achievements in many fields over the years, from the perspective of the entire AI industry, the past applications were more like 'technical college graduates' who have undergone professional studies and do not have the generalization of generic scenarios.
However, the emergence of ChatGPT has proven that AIGC based on large models has become like an 'undergraduate' who has received a general education, although its functions are limited in specific professional fields in the early stage of development, it has stronger extensibility and can empower and implement in various commercial fields. And intuitively, ChatGPT has told the world that AI has become a tool that ordinary people can easily use and improve efficiency.
This means that the business model of AIGC is more explicit, not only To B but also To C.
The main pain points that the AIGC To B model aims to solve are: replacing manual production with AI to help enterprises achieve cost reduction and efficiency improvement. Because the effects brought to the B-end are fast and significant, the willingness of customers to pay is strong.
Under the To C model, for individual users, on the one hand, AIGC applications can act as efficiency tools, improving the efficiency of individual users in information acquisition, format organization, and workflows, and AI models as infrastructure can be integrated into existing workflows; on the other hand, they can act as creative tools, similar to video editing and photo editing software, enabling AIGC to significantly reduce the threshold for mass users' creativity in the era of user-generated popularity and strengthen the IP value of personal media.
From a business perspective, the SaaS subscription of AIGC as a foundational infrastructure will become a long-term trend. The logic of users choosing to pay lies in: more efficient ways of obtaining information; from auxiliary expression to representative expression; integration into existing workflows; and expanding user creativity.
AIGC industry chain
On the one hand, the AIGC industry chain can be divided into three layers: basic layer, middleware, and application layer, according to the model level
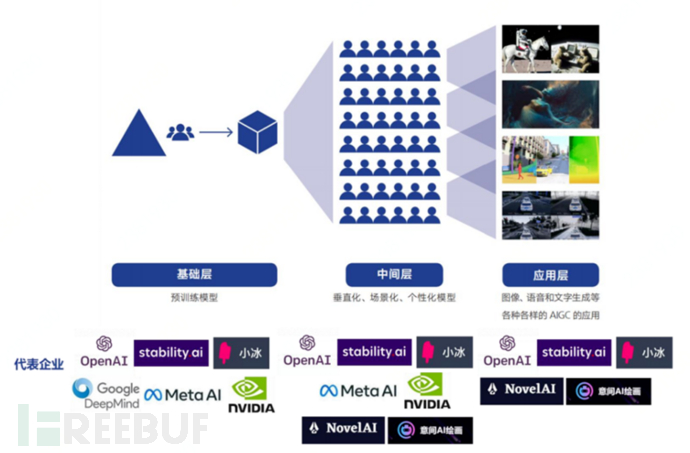
(1) Basic Layer: Utilizes pre-trained models to build infrastructure, this stage has the highest entry threshold, with participants mainly being leading enterprises
Pre-trained models serve as the universal foundation for many small models, reducing the threshold for AI development and application for developers. Pre-trained models have high initial and operating costs, and put forward higher requirements for both software and hardware, so the enterprises involved in this link are mainly leading technology giants such as Microsoft, Google, NVIDIA, Meta, and AI research institutions such as OpenAI and Stability.ai.
Taking OpenAI as an example, the hardware and electricity costs of training GPT-3 in 2020 reached $12 million; taking Meta as an example, to provide more powerful computational power support, Meta has partnered with NVIDIA, Penguin Computing, and Pure Storage to build AI supercomputer RSC. The test data shows that RSC improves the speed of training large NLP models by 3 times and the speed of running computer vision tasks by 20 times.
(2) Middleware: Develops verticalized, scenario-based, and personalized models and application tools based on pre-trained models
Middleware manufacturers generate scenario-based and customized small models based on pre-trained large models, helping different industries and vertical fields to quickly deploy AIGC. On the basis of pre-trained models, developers can generate corresponding small models according to different industries and functional scenarios, with basic layer enterprises extending to the middle layer to do things in a timely manner.
In addition, basic layer enterprises can also act as MaaS (Model-as-a-Service) service providers, opening up their models to more enterprises for secondary development, such as Novel AI, which developed a 2D style AI painting tool based on the open-source model Stable Diffusion from Stability.ai.
(3) Application Layer: Provides content generation services such as text, images, and audio-visual content to C-end users
The application layer refers to providing AIGC-related services to the C-end users, with typical enterprises including Microsoft, Meta, Baidu, Tencent, Alibaba, and others. Based on the models and tools of the basic and intermediate layers, application layer enterprises can focus on meeting user needs and even creating content consumption needs, with AIGC applications such as AI writing and AI painting already landing in marketing, entertainment, art collection, and other fields.
Taking domestic enterprises as an example, Visual China relies on its digital copyright content advantage to layout AIGC digital collectibles, leveraging AI to continuously expand artistic diversity. As of now, all rounds of AIGC digital collectibles have been sold out; Blue Focus Robotics' Little Blue Bo, a robot, has launched AI painting and AI writing tools for advertisers, among which the AI painting tool's creative gallery can generate abstract style paintings to fit different marketing scenarios.
On the other hand, 'data computing power, algorithm models, and upper-level applications' constitute the direct upstream, middle, and downstream relationships of the AIGC industry chain.
The upstream of AIGC mainly includes data suppliers, algorithm institutions, creator ecosystems, and underlying cooperation tools, the middle stream is mainly text, image, audio, and video processing manufacturers, among which there are many players; the downstream is mainly various content creation and distribution platforms as well as content service institutions.
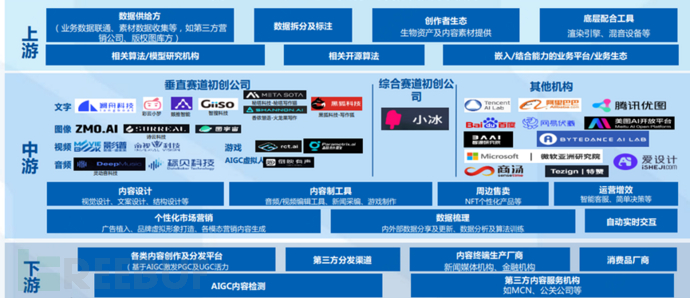
Postscript
ChatGPT, as an AI application with a significant impact, is the product of the rapid development, continuous updating, and iterative combination of various technologies in artificial intelligence and computer technology over the past 10 years. It is the crystallization of research in the field of natural language processing (NLP) in recent years.
ChatGPT has realized a complete and effective technical route for machines to obtain language intelligence, but this research direction still faces many challenges and needs further exploration in science and technology.
At the same time, looking to the future, it will also have a profound impact on the rapid development of AIGC, industrial internet, digital economy, and other fields.
Finally, several controversial topics are appended for readers to think about and discuss.
Will ChatGPT lead the fourth technological revolution?
Keywords: productivity, scale, efficiency
Will ChatGPT bring about a wave of unemployment for humans?
Keywords: emotions, creativity, scarcity
Is ChatGPT suitable for starting a business?
Keywords: technology, capital, team, business model
Are there any worthwhile investment companies in the ChatGPT and AIGC industry chain?
Keywords: NASDAQ 100, Chinese Internet stocks, Tencent, Baidu,科大讯飞
References
Academic papers:
Transformer: Attention Is All You Need, 2017. BERT: Bidirectional Encoder Representation from Transformers, 2018.
GPT-1: Improving Language Understanding by Generative Pre-Training, 2018.
GPT-2: Language Models are Unsupervised Multitask Learners, 2019.
GPT-3: Language Models Are Few-shot Learners, 2020.
InstructGPT: Training language models to follow instructions with human feedback, 2022.
ChatGPT: Optimizing Language Models for Dialogue, 2022.
Security research report:
1. Computer Industry: Research Framework of ChatGPT (2023) - Guotai Junan Securities
2. In-depth Research Report on Computer Industry: ChatGPT, Opening a New Era of AI - Guoxia Securities
3. Computer Industry: Top Chatbot ChatGPT, Opening a New Chapter in the Field of Natural Language Processing - Galaxy Securities
4. Computer Industry: ChatGPT Rapidly Popular, Reconstructing AI Business Model - China Merchants Securities
5. Computer Industry: ChatGPT Wind at the Peak, Accelerating Commercialization - Guolian Securities
6. Computer Industry: ChatGPT Leads the New Wave of AI, AIGC Commercialization Begins - Dongfang Securities
7. Computer Industry: From AIGC to ChatGPT, Principles, Prospects, and Opportunities - Industrial Securities
8. Computer Industry: Deep Analysis of ChatGPT - Haitong Securities
9. China Internet Industry: Development Prospects of ChatGPT & AIGC in the Chinese Market - China Merchants Securities
Public account article:
Huibao Information: 'In-depth Report on ChatGPT Industry'
Huibao Information: 'In-depth Report on AIGC Industry'
TJUNLP: 'Twenty Points of View on ChatGPT', Author: Teacher Xiong Deyi
Zhihu article:
https://zhuanlan.zhihu.com/p/589621442
https://zhuanlan.zhihu.com/p/517219229
https://zhuanlan.zhihu.com/p/34656727
https://zhuanlan.zhihu.com/p/595891945
https://zhuanlan.zhihu.com/p/597264009
https://zhuanlan.zhihu.com/p/563166533
https://zhuanlan.zhihu.com/p/606901798
https://www.zhihu.com/question/570431477/answer/2888747398
https://www.zhihu.com/question/581311491/answer/2882281060

评论已关闭