Author: Geng Hongyu
1 Brief Description of Table Engine
1.1 Official Description
The MergeTree series of engines is designed to insert an extremely large amount of data into a single table. Data can be quickly written one after another in the form of data segments, and the data segments are merged in the background according to certain rules. Compared with continuously modifying (rewriting) the stored data during insertion, this strategy is much more efficient.

The difference between the ReplacingMergeTree engine and the MergeTree engine is that it will delete duplicate items with the same sorting key value.
Data deduplication will only be performed during data merging. Merging will be performed in the background at an unspecified time, so you cannot make a plan in advance. Some data may not have been processed yet. Although you can call the OPTIMIZE statement to initiate an out-of-plan merge, do not rely on it because the OPTIMIZE statement will cause a large amount of read and write operations on the data.
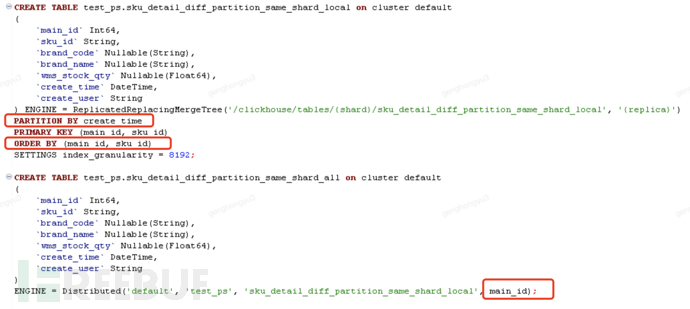
1.2 Local Table Syntax
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = ReplacingMergeTree([ver]) [PARTITION BY expr] [PRIMARY KEY expr] [ORDER BY expr] [SAMPLE BY expr] [TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...] [SETTINGS name=value, ...]
Parameter introduction
- ver — Version column. Type is UInt*, Date, or DateTime. Optional parameter.
When merging data, ReplacingMergeTree selects one row from all rows with the same sorting key to keep:
1. If the ver column is not specified, retain the last one.
2. If the ver column is specified, retain the version with the largest ver value. - PRIMARY KEY expr Primary Key. If you want to select a primary key different from the sorting key, specify it here, optional.
By default, the primary key is the same as the sorting key (specified by the ORDER BY clause). Therefore, in most cases, there is no need to specify a PRIMARY KEY clause separately. - SAMPLE BY EXPR Expression for Sampling, Optional
- PARTITION BY expr Partition Key
ORDER BY expr Sorting Key
1.3 Partition Table Syntax
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]]) [SETTINGS name=value, ...]
Parameter introduction
- cluster cluster name
- table remote data table name
- sharding_key sharding rule
- policy_name rule name, it will be used to store temporary files for asynchronous data transmission
2 The concept of key
The deployment of ClickHouse is divided into single-machine mode and cluster mode, and replicas can also be enabled. There are certain differences in the syntax, steps, and subsequent usage of data tables between the two modes.

When defining the table structure, it is necessary to specify different keys, the role is as follows.

Sharding: the sum of the weights of all sharding nodes is S, which can be understood as the basis for the modulo operation of the sharing action, X=W/S. The value obtained by Mod S of the sharding key matches which sharding node, and the data will be written to which shard. Different shards may exist in different cluster nodes. Even if different shards are on the same node, when ck merges, the dimension is the same partition + the same shard, which is the scope of physical file merging.
If the weights are set to 1, 2, 3 respectively, then the total weight is 6, so the total interval is [0,6), the node01 in the first place of shard configuration, the weight proportion is 1/6, so it belongs to the interval [0,1), the node02 in the second place of shard configuration, the proportion is 2/6, so the interval is [1,3), and the last node03 is [3,6). So if the number produced by rand() is divided by 6 and the remainder falls in which interval, the data will be distributed to which shard. Through weight configuration, data can be distributed according to the desired proportion.
The role of sharding
3.1 Shard rule
In the distributed mode, ClickHouse will divide the data into multiple shards and distribute them to different nodes. Different shard strategies have respective advantages when dealing with different SQL patterns. ClickHouse provides a wealth of sharding strategies, allowing the business to select according to actual needs.
- Random sharding: the written data will be randomly distributed to a certain node in the distributed cluster.
- Constant fixed sharding: the written data will be distributed to a fixed node.
- Column value sharding: sharding by hash based on the value of a certain column.
- Custom expression sharding: specify any legal expression, and sharding by hash based on the value calculated by the expression.
3.2 Analogy
Taking the sharding and table splitting scenario of MySQL as an example:
- 2 databases, 1 table divided into 4 sub-tables, using a master-slave mode.
- db01 contains tab-1 and tab-2, db-2 contains tab-3 and tab-4;
- When configuring sharding rules, it is necessary to set the sharding rule and table rule;
When a record is written, it calculates which table and which database it needs to be written to, and the written record will be replicated from the node.
This MySQL example is logically consistent with CK's partition + sharding + replication. Partition is understood as where the data is written to the table, sharding can be understood as where the data is written to the database, and the replica is the copy of the node.
3.3 Sharding, Partitioning, and Replication
Clickhouse shard is a concept under the cluster mode, which can be compared to MySQL's sharding logic, and the replica is to solve the high availability scenario under the Sharing solution.
The following figure describes the relationship between various keys of a Merge table and also reflects the writing process of a record.
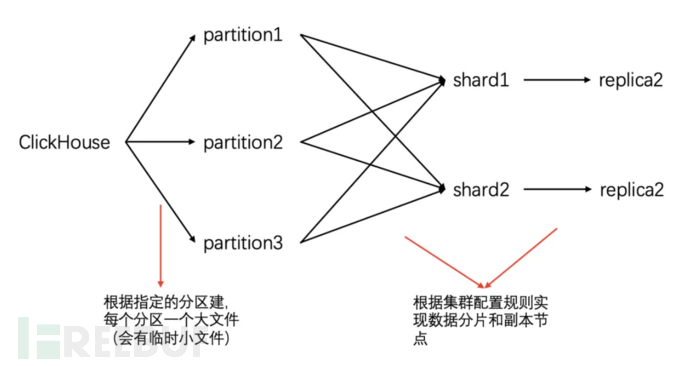
4 Data Merging Restrictions
Understand the concept of partition and shard, and it is clear why CK's data merging needs to be limited to the same partition and the same shard, because they affect the storage location of the data. The merge operation can only be performed on data with the same physical location (partition directory), and the shard affects where the data is stored on which node.
In one word, the deduplication feature of the CK's ReplacingMergeTree engine, the expected deduplication data must meet the same sorting key, the same partition, and the same shard.
Next, verify this requirement on the data.
5 Data Verification
5.1 Scene Setting
Here we need to verify the above conclusion, “The expected deduplication data must meet the same sorting key, the same partition, and the same shard;
Firstly, the same sorting key must be owned before the merge operation can be judged as a duplicate, so the sorting key of the test data must be guaranteed to be the same; the remaining scenes to be tested are partition and shard.
Therefore, the scene setting is carried out as follows:
- The same record can be written into the same partition and the same shard
- The same record can be written into the same partition and different shards
- The same record can be written into different partitions and different shards
- The same record can be written into different partitions and the same shard
Then add the synchronous write mode: - Write directly to the local table
- Write directly to the distributed table
Supplementary: Is it necessary for the partition key and the shard key to be the same?
5.2 Test on the first day
Scenario 1: The same record can be written into the same partition and the same shard
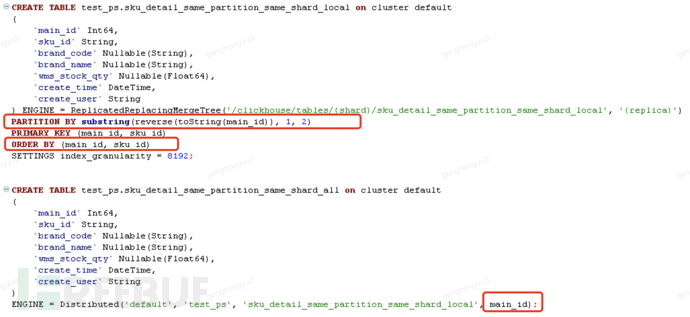
Insert 3 records at a time, insert into local table
[main_id=101,sku_id=SKU0002;barnd_code=BC01,BC02,BC03]
select * from test_ps.sku_detail_same_partition_same_shard_all;

Execute in three times, insert into local table
[main_id=101,sku_id=SKU0001;barnd_code=BC01,BC02,BC03]
select * from test_ps.sku_detail_same_partition_same_shard_all;

Insert data into the distributed table in three batches
[main_id=101,sku_id=SKU0001;barnd_code=BC001,BC002,BC003]
select * from test_ps.sku_detail_same_partition_same_shard_all;

select * from test_ps.sku_detail_same_partition_same_shard_all final;

Conclusion 1
1. Insert data using a distributed table, and ensure that the values of the shard key and partition key are the same to guarantee the success of merge deduplication
Exclude the scenario of inserting data using a local table
2. Insert data using a local table, and under the condition that the shard key and partition key are the same, merge deduplication cannot be guaranteed
- In a session (a single submission), multiple records are included, and a single record will be obtained directly, and deduplication will be performed during the insertion process
In the first insert, the 3 insert statements prepared are executed at one time, and only 1 record is found after the query. - In multiple sessions (multiple submissions), deduplication will not be performed directly, but it is possible to write to different cluster nodes, resulting in inability to deduplicate
Execute 3 insert statements in 3 batches, and after the query, there are 3 records. After the final query, there are 2 records, and the 2 deduplicated records are written to the same cluster node. [Refer to the execution results of SKU0002]
The next step is to directly verify the insertion into the distributed table scenario.
Scenario 2: The same record can be written to the same partition and different shards
- The shard key uses the rand() method to generate randomly.
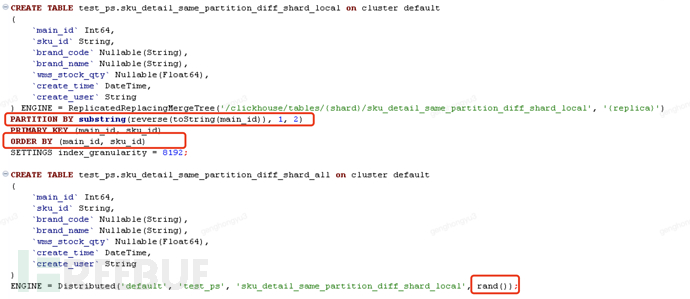
Insert data into the distributed table in three batches
[main_id=103,sku_id=SKU0003;barnd_code=BC301,BC302,BC303]
Check the data insertion status
select * from test_ps.sku_detail_same_partition_diff_shard_all where main_id =103 ;

Check the deduplication result of merge
select * from test_ps.sku_detail_same_partition_diff_shard_all final where main_id =103 ;

Inserted into the distributed table in five times
[main_id=104,sku_id=SKU0004;barnd_code=BC401,BC402,BC403,BC404,BC405]
Check the data insertion status
select * from test_ps.sku_detail_same_partition_diff_shard_all where main_id =104 ;

Check the deduplication result of merge
select * from test_ps.sku_detail_same_partition_diff_shard_all final where main_id =104 ;

Conclusion 2
Inserting data into a distributed table ensures that the value of the partition key is the same and the value of the shard key is random, which cannot guarantee merge deduplication
- If the value after modulus operation of the number generated by rand() is the same when inserting records, it is very fortunate that the merge deduplication can be successful in the end
- If the value obtained after modulating the number generated by rand() is different when inserting records, it will ultimately be unable to pass deduplication by merge
Scenario 3: The same record can be written to different partitions and different shards
- The shard key is generated randomly using the rand() method;
- The partition key is set to creation time for convenience of testing
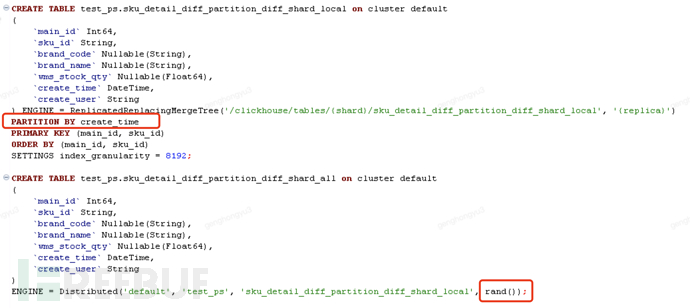
Inserted into the distributed table in five times
[main_id=105,sku_id=SKU0005;barnd_code=BC501,BC502,BC503,BC504,BC505]
Check the data insertion status
select * from test_ps.sku_detail_diff_partition_diff_shard_all where main_id =105 ;

Check the deduplication result of merge
select * from test_ps.sku_detail_diff_partition_diff_shard_all final where main_id =105;

Conclusion 3
Inserting data into the distributed table, the value of the partition key is inconsistent with the sorting key, and the value of the shard key is randomly generated, which cannot guarantee deduplication by merge
- According to the current test results, although the create_time are all different, that is to say, the partitions are different, and data merging has also occurred
- The data has been merged, but the result is not completely merged according to the sorting key
Scenario 4: The same record can be written to different partitions and the same shard
- The shard key uses main_id;
- The partition key is set to creation time for convenience of testing
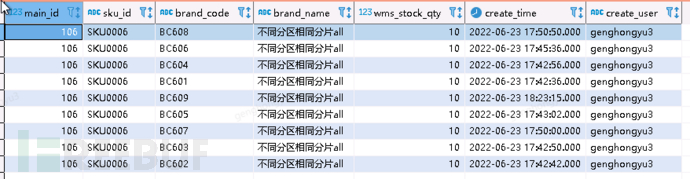
Inserted into the distributed table in six times
[main_id=106,sku_id=SKU0006;barnd_code=BC601,BC602,BC603,BC604,BC605,BC606]
Check the data insertion status
select * from test_ps.sku_detail_diff_partition_same_shard_all where main_id =106 ;

Check the deduplication result of merge
select * from test_ps.sku_detail_diff_partition_same_shard_all final where main_id =106;

In this scenario, after the second day's search, the data has not been merged, and the deduplicated results can still be retrieved using the final keyword. That is to say, the final keyword only performs deduplication in memory, as the files in different partitions have not been merged, so there is no deduplication. On the contrary, the data table in the same partition and the same shard has been merged, and only one record can be obtained through normal search.
Conclusion 4
Using distributed table to insert data, the value of the partition key is inconsistent with the sorting key, and the value of the shard key is fixed, which cannot achieve merge deduplication
5.3 Second day check
The following all use normal queries, and the following situations are found
- The data of the table with different shards has not been merged
- The merging of those with the same shard but different partitions has not been merged
- The merging of those with the same shard and partition has been completed
select * from test_ps.sku_detail_same_partition_same_shard_all;

select * from test_ps.sku_detail_same_partition_diff_shard_all;

select * from test_ps.sku_detail_diff_partition_diff_shard_all;

select * from test_ps.sku_detail_diff_partition_same_shard_all;
6 Summary
According to the test results, the merging situation under different scenarios:
- If the data exists in the same shard and the same partition, it is absolutely possible to perform merge deduplication.
- If the data is stored in different shards and different partitions, no merging deduplication will be performed.
- If the data is stored in different shards but the same partition is guaranteed within the same shard, merge deduplication will be performed under this shard.
- If the data exists in the same shard but different partitions, it will not perform merge deduplication, but deduplication can be performed on the data with the same partition and the same shard in CK memory through the final keyword.
When ReplacingMergeTree in Clickhouse performs a merge operation, it identifies whether it is a duplicate or needs to be merged based on the sorting key (order by). Partition and shard affect the storage location of the data, on which cluster node, and in which file directory. Therefore, when ReplacingMergeTree table engine merges, it will only perform merge operations on the current node and the data with the same physical location in the same table directory.
Finally, when designing the table, if we expect to use the deduplication feature of ReplacingMergeTree automatically, thenIt must be stored in the same partition and the same shard;When setting the partition key and shard key, they do not require that they must be the same, but they must be stable. The meaning of stability is that the output must be the same as the input when the input parameters are the same.

评论已关闭