Author: JD Technology, He Yuhang
Introduction
How to give full play to the potential of ChatGPT has become the focus of many enterprises. However, this change may not be a good thing for employees. IBM plans to replace 7800 jobs with AI, game companies are using MidJourney to reduce the number of concept artists... Such news is not uncommon. Understanding and applying this new technology is increasingly important for people in the workplace.
I. The principle of the GPT model

Understanding the principle is the first step in effective application. ChatGPT is an AI chat product based on the GPT model, hereinafter referred to as GPT.
Technically, GPT is a large language model (LLM) based on the Transformer architecture. The name GPT actually stands for "Generative Pre-trained Transformer", which means "Generative Pre-trained Transformer" in Chinese.
1. What is the difference between large models and traditional AI?
Traditional AI models are trained for specific targets and can only handle specific problems. For example, AlphaGO, which is very good at playing chess.
While natural language processing (NLP) tries to go further and solve more general problems for users. It can be divided into two key steps: natural language understanding (NLU) and natural language generation (NLG).
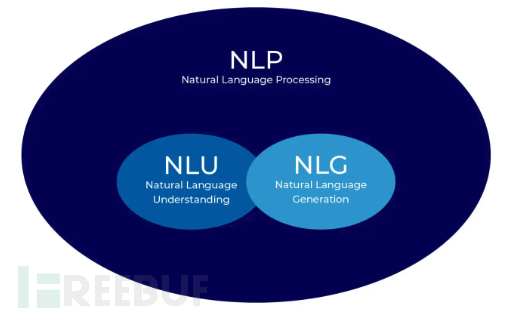
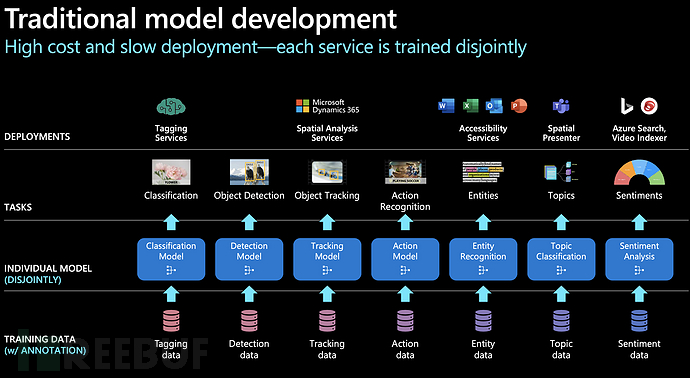
Artificial intelligence assistants represented by SIRI unified the NLU layer, using a single model to understand user needs, then allocating the needs to specific AI models for processing, realizing NLG and providing feedback to users. However, this model has significant drawbacks. As shown in the official illustration of Microsoft, like traditional AI, users need to train a corresponding model for each new scenario they encounter, which is expensive and slow to develop, and the NLG layer urgently needs to be changed.
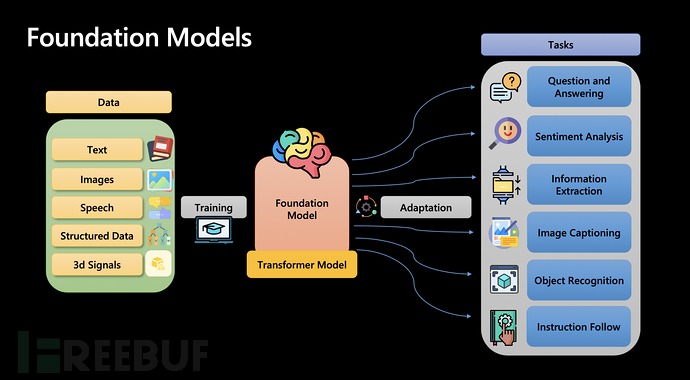
Large language models (such as GPT) adopt a completely different strategy to achieve the unification of the NLG layer. Adhering to the concept of "strength brings wonders", a vast amount of knowledge is integrated into a unified model, without training models for each specific task separately, greatly enhancing the AI's ability to solve various types of problems.
2. How does ChatGPT achieve NLG?
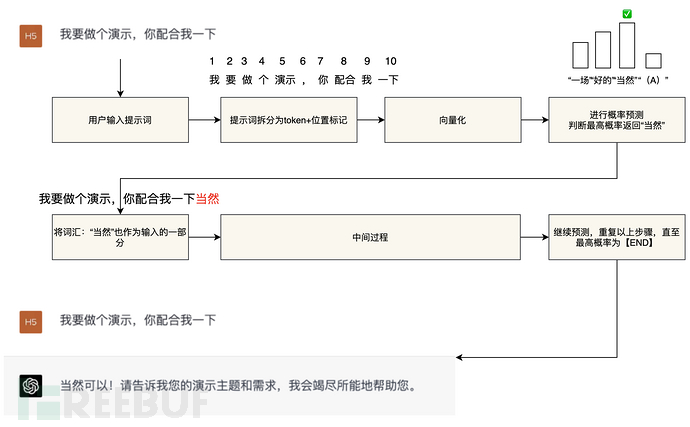
The essence of AI is an inverse probability problem. The natural language generation of GPT is actually a "text continuation" game based on probability. We can simplify the GPT model to a "function" with billions of parameters. When the user inputs a "prompt", the model executes the following steps:
① Convert the user's "prompt" into token (more accurately, "symbol", approximately equivalent to "vocabulary", hereinafter the same) + token position.
② Vectorize the above information as input parameters for the large model's "function".
③ The large model makes probability guesses based on the processed parameters, predicts the most suitable vocabulary for replying to the user, and then replies.
④ Add the replied vocabulary (token) to the input parameters, repeat the above steps until the highest probability vocabulary is [END], thus realizing a complete answer. This method enables the GPT model to generate coherent and reasonable responses based on user prompts, thus realizing natural language processing tasks.
3. The key technology of context understanding
GPT not only understands the current question of the user but also understands the background of the question based on the previous context. This is due to the 'self-attention mechanism' in the Transformer architecture. This mechanism enables GPT to capture the dependency relationships in long texts. In plain language, when GPT is making word continuation judgments, it not only bases on the 'prompt' just input by the user but also takes the 'prompt' and 'response' from previous multi-round dialogues as input parameters. However, this distance length is limited. For GPT-3.5, the distance limit is 4096 tokens; for GPT-4, this distance has been greatly extended to 32,000 tokens.
4. Why are large models stunning?
We have introduced the principle of GPT, so how does it achieve this magical effect? Mainly in three steps:
① Self-supervised learning: Utilizes massive text for self-learning, enabling GPT to have the basic ability to predict context probabilities.
② Supervised learning: With human participation, it helps GPT understand human preferences and expectations for answers, which is essentially fine-tuning (fine-tune).
③ Reinforcement learning: Continuously optimize and improve the quality of answers based on user feedback during use.
Among them, self-supervised learning is the most crucial. Because, the charm of large models lies in their 'large' - large in two aspects:
① Large training data:
That is, the scale of data used to train large models, taking GPT-3 as an example, its training data source is various selected information from the Internet and classic books, reaching 45TB, which is equivalent to reading a billion books.
② Large model parameters:
Parameters are a term in neural networks used to capture regularities and features in data. Typically, the large models claimed to have hundreds of billions or trillions of parameters refer to their parameter quantity.
The pursuit of large model parameters is to exploit their magical 'emergence ability' to achieve the so-called 'quantitative change leading to qualitative change'. For example, if we ask a large model to guess the name of a movie based on emoji, such as the fish symbol representing 'Finding Nemo'. It can be seen that when the model parameters reach the billion level, the matching accuracy is greatly improved. This indicates that the increase in model parameter quantity is of great significance in improving model performance.
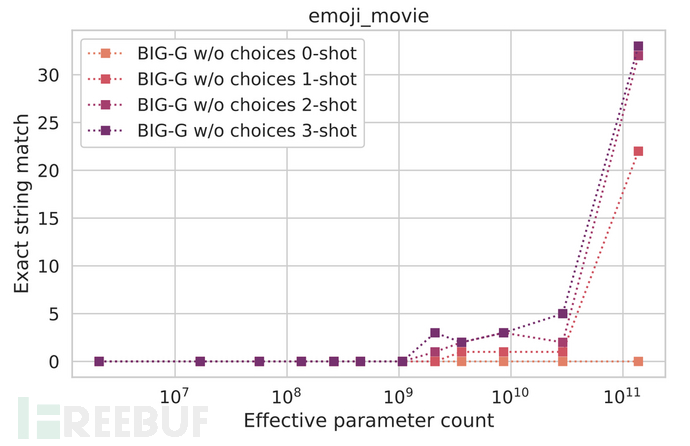
Similar effects are also observed when dealing with other multi-type tasks:
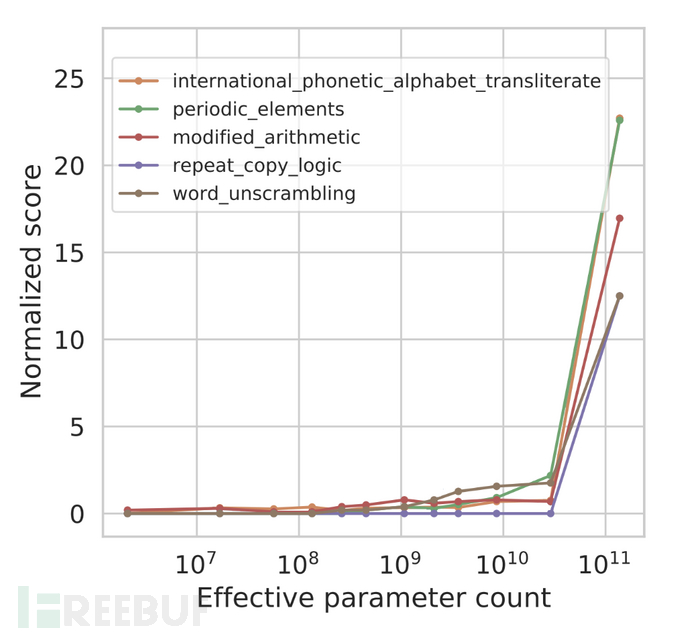
As experiments have shown, only when the model parameters reach the billion level do the advantages of large models become prominent. Other large models beyond GPT also show similar performance.
Why?
The mainstream view holds that to complete a task fully, one actually needs to go through many sub-steps. When the model size is insufficient, large language models cannot understand or execute all the steps, leading to incorrect final results. When the number of parameters reaches the billion level, their ability to solve problems across the entire chain is sufficient. People use the correctness of the final result as the criterion for evaluation, leading to the belief that it is a kind of 'emergence'.
In the issue of 'emergence,' the analogy of human and monkey is very interesting. The human brain capacity is three times larger than that of monkeys, which allows humans to engage in more complex thinking, communication, and creation. There is no significant difference in their structure, isn't this also 'emergence'?
GPT-3.5 is a billion-scale model with 175 billion parameters. Compared to GPT-3, GPT-3.5 mainly focuses on the fine-tuning of model parameters to make it more in line with human habits in question and answer scenarios. It is reported that the model parameters of GPT-4 even reach five times the amount of GPT-3.5, which also explains why GPT-4 performs so intelligently (those who have experienced it should understand). Here is the evolution history of the GPT model:

Secondly, the limitations of GPT
In summary, GPT models have obvious and breakthrough advantages. Typical advantages include: ① strong language understanding ability; ② extremely extensive knowledge base; ③ learning ability and reasoning ability, etc. These capabilities make people feel that artificial intelligence truly has a 'mind', imagining using GPT to solve all kinds of problems.
However, in order to deeply apply this technology, it is necessary to understand its limitations so that strengths can be complemented with weaknesses in practical applications. The main limitations can be summarized into six major points:
1. Lack of transparency in logic
The responses of GPT models are essentially probabilistic. In traditional software development, the input and output parameters of interfaces are determined, but GPT's responses have a certain degree of randomness when given input parameters (i.e., prompts). When people use ChatGPT as a chat tool, this inaccuracy can be a topic of conversation for users; when it comes to commercial software applications, it is necessary to pay special attention to reducing uncertainty in design, as users place a high value on determinism in most product scenarios.
2. Poor short-term memory
Thanks to the self-attention mechanism, ChatGPT has the ability to engage in multi-turn conversations. However, its memory length is quite limited; the GPT-3.5 model only supports a forward trace of 4096 tokens for reference in responses. Worse still, these 4096 tokens also include parts of ChatGPT's previous responses to users! This makes its memory, which is already stretched thin, even more difficult to bear, and it can be likened to an electronic goldfish. Fortunately, GPT-4 has expanded the upper limit of context tokens to 32,000, to some extent mitigating this issue.
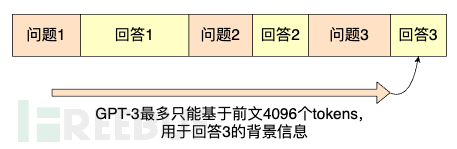
3. High resource consumption
The intelligence of ChatGPT requires a large amount of computing power, and running large-scale high-end graphics cards consumes a lot of electricity. Within five years, with the further advancement of semiconductor technology and the widespread application of large models, the marginal cost of computing power and electricity will gradually transform into fixed costs, thus solving this problem.
4. Slow Response Speed
Due to the large model, GPT cannot respond instantaneously either, just like the user's actual experience, ChatGPT responds word by word. When designing relevant products, enterprises need to pay special attention to the application scenarios:
① Avoid using GPT in high-concurrency scenarios, as the concurrency limit of the interface calls this service depends on is very low.
② Avoid using GPT in scenarios where users urgently need results, ensuring that users can 'wait it out'.
5. Shallow Industry Understanding
Of course, ChatGPT has rich knowledge from the Internet and classic books. However, the real enterprise-level professional knowledge often comes from in-depth research and practice in a specific field, which cannot be obtained solely by knowledge from the Internet. Therefore, if GPT is to act as an enterprise advisor, it can only help sort out the strategic framework, but it is difficult to provide the enterprise with insightful strategic advice.
6. Value Misalignment
① During the self-supervised learning stage, the English proportion of GPT training data reaches 92%. ② During the supervised learning stage, engineers who impart moral values mainly come from the English-speaking world. ③ In the reinforcement learning phase, it may also be affected by malicious users' input of incorrect values. Therefore, the 'spiritual core' of GPT is based on Western values, which may lead to the generated text being difficult to conform to our cultural background and values.
Three: GPT Multi-layer Application Guide
After understanding the principles and limitations of the GPT model, we can finally see how to make good use of this technology. I divide it into five layers according to the intuitiveness of its capabilities, and introduce them layer by layer.
First Layer: Chatting Ability
In this usage, GPT's answer is the deliverable to the customer, and it is the simplest and most intuitive usage of the GPT model.
1. Shell Chatbot
Developed chatbot products using the official OpenAI interface. The existence of such products is something that everyone understands. Otherwise, why wouldn't users use ChatGPT directly? These products are difficult to form a phenomenon-level application and are highly competitive. Due to their gray nature and unfiltered content, the story of website closures and domain name changes will continue to unfold.
2. Scenario-based Question and Answering
This model restricts the response scenarios of GPT. By limiting prompt words, embedding a large amount of specific domain knowledge, and fine-tuning technology, GPT can only answer specific types of questions based on a certain identity. For other types of questions, the robot will inform the user that it is not familiar with the relevant content. This usage can effectively restrict user input and reduce many unnecessary risks, but training an outstanding scenario-based robot also requires a lot of effort. Typical applications include intelligent customer service, intelligent psychological counseling, and legal consultation. Microsoft's new Bing is an outstanding representative of such applications, and its playful and proud response style is deeply loved by netizens.
Second level: Language ability
At this level, we give full play to ChatGPT's linguistic talent to assist various text-based processing tasks. Starting from this level, one-shot or few-shot (giving ChatGPT one or more examples in the prompt words) is needed to improve ChatGPT's performance. The interaction with users is no longer limited to the chat window, and prompt word templates are pre-prepared in advance, allowing users to only input limited information corresponding to the empty slots of the prompt words.

The basic process of the application of预制slot-based prompt word template is as follows:

1. Text processing
There are mainly three uses of this type of application:
①Article abstraction
You can input article paragraphs and require the extraction of the main theme of the paragraph. However, due to token number limitations, it is difficult to summarize the whole article. You can also request to generate short titles, subtitles, and so on. In the prompt words, reserve a slot for [case], allowing users to input some reference cases, so that GPT can learn the corresponding style and output targeted content.
②Polishing/rewriting
It can be used for the preliminary polishing of articles, which can eliminate spelling errors, incorrect punctuation, and so on. Rewriting can change the style of the article, such as changing it to the style of Xiaohongshu.
③Article expansion
Based on an outline, expand the article section by section. Due to token limitations, if the length is too long at one time, the expanded output is difficult to achieve consistency. ChatGPT itself does not produce new knowledge, and it is difficult to write profound insights in article expansion, only generating trivial articles. Generating regular short copy with given keywords and cases is an effective method to apply its article expansion capabilities.
2. Translation
The GPT model has learned a large amount of language during training and has cross-language capabilities. No matter what language is used to communicate with it, as long as the intention is understood, the ability to analyze problems is not language-specific. Therefore, translation is very easy for GPT. Of course, it is only basic translation, and don't expect it to be able to translate with 'faithfulness, expressiveness, and elegance'.
3. Sentiment analysis
GPT can understand the user's emotions behind the text. For example, by introducing GPT capabilities into the customer service module, it can quickly judge the emotional state based on user voice and text, identify potential customer complaints in advance, and effectively soothe them before the emotional outbreak.
Third level: Text capability
At this level, GPT's ability has exceeded language, and it can handle tasks related to text after a large amount of learning. It even has real learning ability, using few-shot techniques to solve problems that do not exist in the training data. The range of applications of this level is extremely wide, and a large number of highly creative products will emerge. I will only list some typical examples here.
1. Writing code
ChatGPT can write code in SQL, Python, Java, and help find bugs in code. Similar to the reason for writing articles, it is not possible to require it to write long code.
2. Write Prompts
It is required that GPT creates prompts in a simple way that is linked with other AI. For example, requiring GPT to write prompts for midjourney has become a very mainstream practice.
3. Data Analysis
ChatGPT can directly perform data analysis or analyze data in conjunction with EXCEL. It reduces the cost of data analysis operations to an extremely low level, greatly improving the efficiency of data analysis.
Fourth Layer: Reasoning Ability
In the previous layers, we have seen the reasoning ability of GPT. Replacing manual click operation flow with GPT's reasoning ability will bring a revolutionary change to the product design of both B-side and C-side. I believe that in the short term, there are more opportunities in B-side than in C-side. After 20 years of development of the Internet, the main needs of C-side users have basically been met. Disrupting the operation path of C-side users will bring a higher learning cost. However, B-side has a lot of room for development, and it is divided into three stages here:
1. Automation Workflow Linkage
By utilizing ChatGPT's ability to understand human intent and combining langChain technology to integrate prompts and web links of various internal company tasks, employees do not need to search for various links. When they need to perform related operations, they will automatically jump to the corresponding page for the next step. With ChatGPT as the intelligent core, truly realizing the organic integration of various operations on the B-side. The following figure is an example of the design concept.
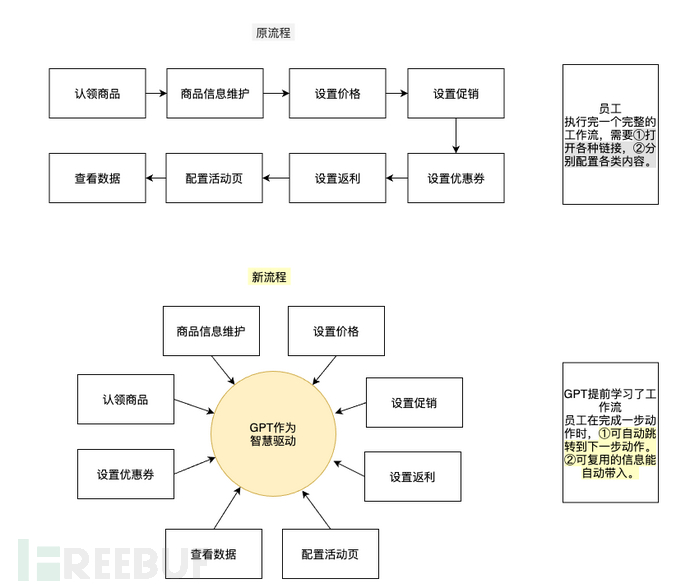
2. AI-assisted Decision Making
Based on the first stage, the corresponding page's partial functions are linked with GPT. In this way, when employees perform operations, some functions can be realized by AI, which can multiply improve efficiency. Microsoft Copilot is a representative of such products, for example, it can realize data analysis in Excel without the need to search for related formulas, and the data analysis is automatically done.
3. Fully Automatic AI Workflow
At this stage, it is still at the demonstration level, presenting the vision of the future. As mentioned earlier, GPT is difficult to solve specific domain details unless a large amount of fine-tuning and private data deployment is done for a specific scenario. AutoGPT and AgentGPT belong to this category.
Fifth Layer: Domestic Large Models
AI technology is science, not theology, and the principles of large models are not a secret. The United States can achieve this, and China can not only do it but also it is necessary. As long as the quality of the training data meets the standard, the model parameters break through ten billion, and it has the ability to reason; breaking through one hundred billion can compete with GPT-4. By using a large amount of Chinese corpus and Chinese fine-tuning, China will undoubtedly have large models that are in line with the national cultural background and values.
However, the road is long and arduous, with numerous difficulties, such as extremely high training costs, high requirements for the quality of training data, complex model optimization, and the obvious Matthew effect. Therefore, it is expected that in the next five years, China will have at most 3 well-known large model service providers.
Large models are the infrastructure of the AI era, and most companies choose to apply them directly to obtain commercial value. In this context, companies willing to invest in their own large models are even more valuable. Here, I would like to express my respect to those domestic enterprises that are brave enough to invest in the construction of their own large models on behalf of individuals.
Four, Summary
On the whole, ChatGPT is a groundbreaking product. The application of GPT technology at different levels reflects some common opportunities. I have summarized three future capabilities with great value.
1. Question Decomposition Technology
Given that the limitation of GPT's reply is that it can only be based on a maximum of 32,000 tokens, it is particularly crucial to effectively decompose the question into sub-questions and handle them by GPT. Future work modes may involve decomposing the question into sub-questions and then assembling the solutions to these sub-questions. In the implementation, it is also necessary to judge the difficulty of the sub-questions, as some questions can be handled by some small models, which can effectively control the application cost.
2. Three Optimization Methods
To make GPT play a specific role at multiple levels, there are mainly three interactive methods, with costs ranging from low to high:

① Prompt word optimization
By exploring, finding the optimal prompt word template, and reserving specific slots for user input. It is possible to achieve a wide range of functions simply through prompt word optimization. Many products based on GPT have their underlying layer based on the packaging of specific prompt words. Good prompt words should include roles, background, tasks that GPT needs to perform, and output standards. According to industry research, good prompt words can increase the usability of GPT3.5 results from 30% to over 80%. Prompt word optimization is undoubtedly the most important of the three methods.
② Embedding
This is a method to build an independent knowledge base, using embedding technology to vectorize the self-built knowledge base, so that GPT can answer questions based on its own data.
③ Fine-tuning (finetune)
By inputting a large number of Q&A, truly teaching GPT how to answer a certain type of question, the cost is higher than the previous two. The advantage lies in transforming the short-term memory of prompt words into the long-term memory of the private model, thereby releasing valuable Tokens to improve other details of the prompt words.
The above three methods are not conflicting, and they often complement each other in engineering practice, especially the first two.
3. Accumulation of Private Data
The value of private datasets has been further enhanced, and industries can use this to repackage GPT for secondary packaging and solve specific domain problems. It is recommended to use the GPT interface provided by Microsoft Azure to build large language model products with private data. Since Microsoft's GPT service for B-end is independently deployed, it will not use private data for large model training, which can effectively protect private data. After all, once private data is made public, its value will be greatly reduced.
With the support of these capabilities, large language models can fully unleash their productivity in solving repetitive labor dependent on computers. I summarize the business operation model of the next era (within 3 years) as shown in the following figure:
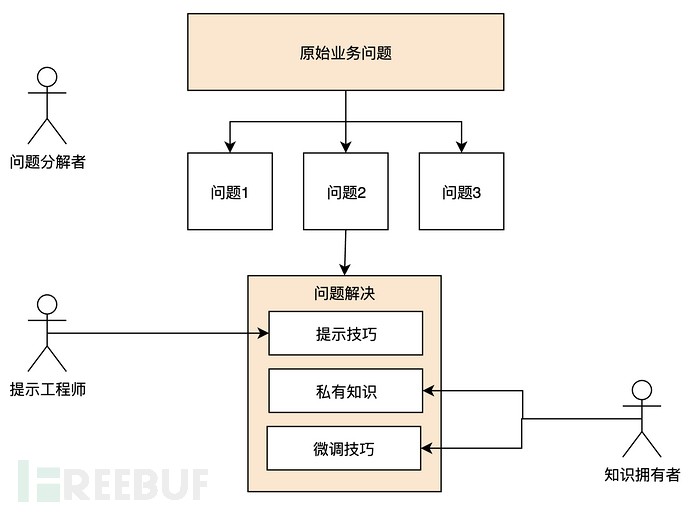
Enterprises will derive three types of roles based on the three major capabilities:
① Problem decomposers
These roles are very clear about the boundaries of large language model capabilities and can effectively decompose a business problem into sub-problems that GPT can handle, and can assemble sub-problems according to the results of the problem.
② Prompt engineers
These roles are well-versed in communicating with GPT and can provide effective prompt templates according to different types of questions, greatly improving the output quality of GPT.
③ Knowledge holders
These roles have a lot of industry know-how and can structure knowledge to teach GPT. Corresponding to the field experts of today.
Under the promotion of this model, GPT will become an important helper for enterprises to improve efficiency, which can solve a lot of repetitive labor and provide valuable references. However, the subjective initiative of humans still plays a decisive role.
V. Conclusion
Even with AI technologies represented by GPT-4 maintaining the current level, the efficiency improvement brought about is already astonishing, not to mention that they are still evolving at a rapid pace. From the history of technological revolution, a new technology that greatly improves efficiency often benefits B-end first, and then gradually starts to release its huge value in C-end. This is determined by the enterprises' natural sensitivity to efficiency, and changing the habits of C-end users requires a large amount of learning cost and scenario mining, with a strong lagging effect. Three examples will make it clear to everyone:
1. Looking back at the first industrial revolution, the appearance of the internal combustion engine first led to a large number of unemployed textile workers, and then gradually found various end-user scenarios, promoting a significant increase in social productivity.
2. ChatGPT can generate more quickly, but there is no increase in the demand for reading from end-users. For marketing companies, efficiency has improved, and fewer people are needed.
3. MidJourney can quickly generate pillow pattern designs, but end-users will not buy more pillows, so there will be fewer people who need to create images.
A revolution in the internal efficiency of information technology companies is about to arrive. The repetitive labor of computers will disappear because large models are most skilled at learning this. As I mentioned at the beginning of my article, the case of IBM Company reducing 7,800 positions, which will only happen more frequently.
The AI era has truly arrived, and every position needs to think about how to make AI a partner in work.

评论已关闭