Kafka use cases
Why use Kafka message queues?
Decoupling, peak shaving: In traditional ways, upstream data needs to be received in real-time by downstream, if upstream is in some business scenarios: for example, the traffic will peak at ten o'clock in the morning, then the downstream resources may not be able to bear the pressure. But if message queues are used, messages can be temporarily stored in message pipelines, and downstream can process them step by step at their own pace;
![Get educated on Kafka? Read this article enough!]}](/zb_users/upload/auto_pic/1506.jpg)
Scalability:By horizontally scaling producers, consumers, and brokers, Kafka can easily handle massive message streams;
High throughput, low latency:Can achieve a throughput rate of 100,000/s on a regular server;
Disaster recovery: KafkaThrough the setting of replica replication and the disaster recovery mechanism of leader/follower, the security of messages is guaranteed.
How does Kafka achieve high throughput and low latency?
1. Sequential read and write
Kafka uses disk sequential read and write to improve performance
Comparison of sequential read and write performance with random read and write performance:
| Sequential read | Random read | Sequential write | Random write | |
|---|---|---|---|---|
| Mechanical hard drive | 84.0MB/s | 0.033MB/s (512 bytes) | 79.0MB/s | 0.083MB/s (512 bytes) |
| Solid-state hard drive | 220.7MB/s | 5.296MB/s (512 bytes) | 77.2MB/s | 10.203MB/s (512 bytes) |
From the data, it can be seen that the sequential read and write speed of the disk is much higher than the random read and write speed, which is becauseTraditional head and probe structureis required during random read and write operations.Frequent seekThis also requires the frequent movement of heads and probes, and the adjustment of the position of heads and probes in the mechanical structure is very time-consuming, which seriously affects the hard disk's addressing speed, and in turn affects the random write speed.
Kafka's messages are continuously appended to the end of local disk files, rather than being written randomly, which significantly improves Kafka's write throughput. Each Partition is actually a file, and after receiving messages, Kafka will insert data at the end of the file.

2.页缓存(pageCache)
PageCache是系统级别的缓存,它把尽可能多的空闲内存当作磁盘缓存使用来进一步提高IO效率;
PageCache同时可以避免在JVM内部缓存数据,避免不必要的GC、以及内存空间占用。对于In-Process Cache,如果Kafka重启,它会失效,而操作系统管理的PageCache依然可以继续使用。
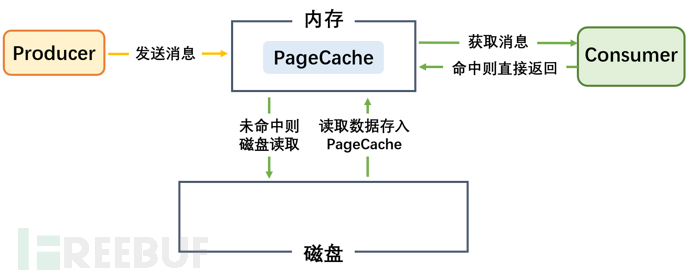
•producer把消息发到broker后,数据并不是直接落入磁盘的,而是先进入PageCache。PageCache中的数据会被内核中的处理线程采用同步或异步的方式定期刷盘至磁盘。
•Consumer消费消息时,会先从PageCache获取消息,获取不到才回去磁盘读取,并且会预读出一些相邻的块放入PageCache,以方便下一次读取。
•如果Kafka producer的生产速率与consumer的消费速率相差不大,那么几乎只靠对broker PageCache的读写就能完成整个生产和消费过程,磁盘访问非常少
3.零拷贝
正常过程:
1.操作系统将数据从磁盘上读入到内核空间的读缓冲区中
2.应用程序(也就是Kafka)从内核空间的读缓冲区将数据拷贝到用户空间的缓冲区中
3.应用程序将数据从用户空间的缓冲区再写回到内核空间的socket缓冲区中
4.操作系统将socket缓冲区中的数据拷贝到NIC缓冲区中,然后通过网络发送给客户端

在这个过程中,可以发现, 数据从磁盘到最终发出去,要经历4次拷贝,而在这四次拷贝过程中, 有两次拷贝是浪费的。
1.从内核空间拷贝到用户空间;
2.从用户空间再次拷贝到内核空间;
除此之外,由于用户空间和内核空间的切换,会带来Cpu上下文切换,对于Cpu的性能也会造成影响;
零拷贝省略了数据在内核空间和用户空间之间的重复穿梭;用户态和内核态切换时产生中断,耗时;
4.分区分段索引
Kafka的message是按topic分类存储的,topic中的数据又是按照一个一个的partition即分区存储到不同broker节点。每个partition对应了操作系统上的一个文件夹,partition实际上又是按照segment分段存储的。符合分布式系统The design idea of partition bucketing.
Through this design of partition segmentation, Kafka's message messages are actually distributed in one small segment after another, and each file operation is directly operated on the segment. To further optimize query, Kafka also defaults to building an index file for the segmented data files, which is the .index file on the file system. This design of partition segmentation + index not only improves the efficiency of data reading but also improves the parallelism of data operations.
5. Batch processing
Kafka sends messages not one by one, but in batches, which greatly improves the throughput of message sending.
Assuming it takes 1ms to send a message, and the throughput at this time is 1000 TPS. However, if we send messages in batches, 1000 messages need 10ms, and the throughput at this time reaches 1000 * 100 TPS. Moreover, this also greatly reduces the number of requests to the broker, improving overall efficiency.
Kafka architecture
Basic concept
| Noun | Concept |
|---|---|
| Producer | Producer (sending messages) |
| Consumer | Consumer (receiving messages) |
| ConsumerGroup | Consumer group, which can consume messages from the same topic in parallel |
| Broker | An independent Kafka server is called a broker. The broker receives messages from producers, sets offsets for messages, and submits messages to disk for storage. The broker provides services to consumers, responds to requests to read partitions, and returns messages that have been submitted to disk. It can play a role in load balancing and fault tolerance. |
| Topic | Topic, a queue, which can be understood as dividing messages into different topics according to the logical classification of messages |
| Partition | The physical grouping of topics, a topic can be divided into multiple partitions, each partition is an ordered queue. It can improve scalability and handle high concurrency scenarios. |
| replica | Replicas, to ensure high availability of the cluster, Kafka provides a replica mechanism, with each partition of a topic having several replicas, one leader, and several followers |
| leader | The leader of multiple replicas in each partition, the object that producers send data to, and the object that consumers consume data from are all leaders |
| offset | For each partition in Kafka, each message has a unique offset, which is used to indicate the position of the message in the partition. |
架构图
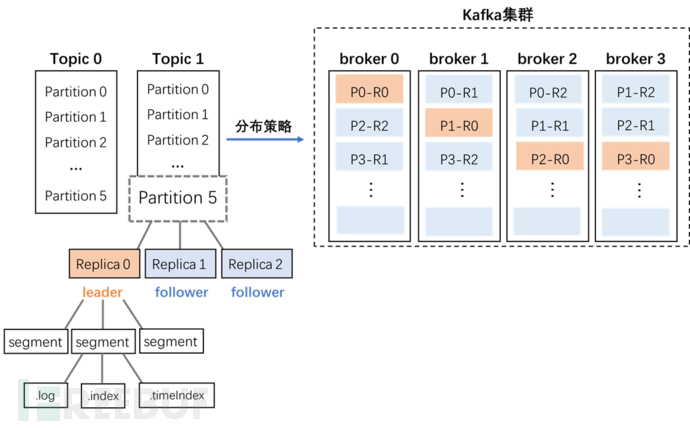
Q1:Topic的分区及副本在broker上是如何分配的呢?
这里涉及到两个参数:
startIndex:第一个分区的第一个副本放置位置(P0-R0)
nextReplicaShift:其他分区的副本的放置是依次后移的,间隔距离就是 nextReplicaShift 值。
Q2:Kafka的架构是基于什么设计思想呢?
分治思想:
1. topic分治:对于kafka的topic,我们在创建之初可以设置多个partition来存放数据,对于同一个topic的数据,每条数据的key通过哈希取模被路由到不同的partition中(如果没有设置key,则根据消息本身取模),以此达到分治的目的。
2. partition分治:为了方便数据的消费,kafka将原始的数据转化为”索引+数据“的形式进行分治,将一个partition对应一个文件转变为一个partition对应多个人不同类型的文件,分别为:
•.index文件:索引文件,用来记录log文件中真实消息的相对偏移量和物理位置,为了减少索引文件的大小,使用了稀疏索引
•.log文件:用来记录producer写入的真实消息,即消息体本身;
•.timeindex文件:时间索引文件,类比.index文件,用来记录log文件中真实消息写入的时间情况,跟offset索引文件功能一样,只不过这个以时间作为索引,用来快速定位目标时间点的数据;
3. 底层文件分治:不能将partition全部文件都放入一套 ”.index+.log+.timeindex“ 文件中,因此需要对文件进行拆分。kafka对单个.index文件、.timeindex文件、.log文件的大小都有限定(通过不同参数配置),且这3个文件互为一组。当.log文件的大小达到阈值则会自动拆分形成一组新的文件,这种将数据拆分成多个的小文件叫做segment,一个log文件代表一个segment。
kafka工作流程
生产流程:
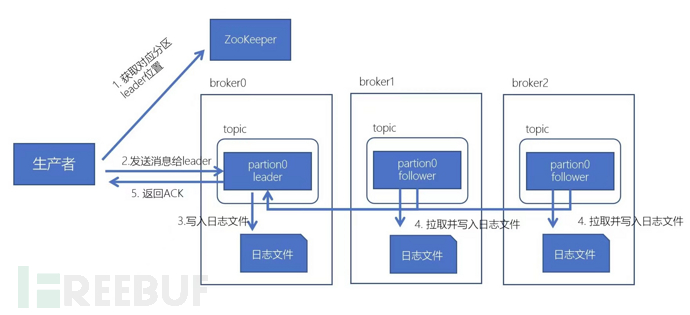
1.先从zk获取对应分区的leader在哪个broker
2.broker进程上的leader将消息写入到本地log中
3.follower从leader上拉取消息,写入到本地log,并向leader发送ACK
4.leader接收到所有的ISR中的Replica的ACK后,并向生产者返回ACK
Consumption process:
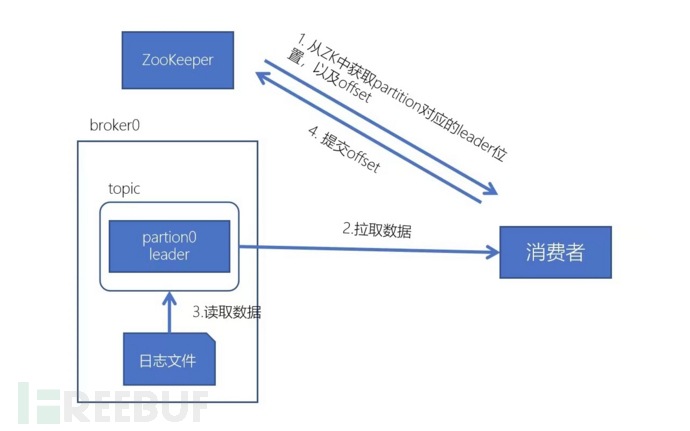
1.Each consumer can obtain the partitions to be consumed according to the allocation strategy
2.Get the broker where the leader of the consumer corresponds to and the offset
3.Pull data
4.Consumer submits offset
Partition strategy
I believe the above content has given you a general understanding of the process of message production and consumption: messages within a topic will be sent to different partitions for different consumers to pull messages.
So, in this process, two issues are involved:
1.What strategy does the producer use to distribute data to partitions?
2.What strategy do consumers use to pull messages from different partitions?
Producer partition strategy
When the producer writes messages to the topic, Kafka will distribute the data to different partitions based on different strategies:
1. Round Robin partition strategy
That is, partitioning by message order is theThe default strategy, also the most commonly used strategy, can ensure that all messages are evenly distributed to a partition to the maximum extent
If the key is null, the round-robin algorithm is used to evenly distribute the partitions
2. Partition allocation strategy by key
If the key is not null, key.hash() % n
However, partitioning data based on the key may cause data skew
3. Random partition strategy
Random partition, not recommended for use
4. Custom partition strategy
Determine the partition strategy according to business needs
Disorder issues in Kafka are due to the writer strategy of producers. If a topic has multiple partitions, the data will be stored in different partitions. When the partition number is greater than 1, the data (messages) will be scattered across different partitions. If there is only one partition, messages are ordered
Consumer partition strategy
At the same time, only one consumer instance in the group can consume a message:
1.Consumer number = partition number: One partition corresponds to one consumer
2.Consumer number < partition number: One consumer corresponds to multiple partitions
3.Consumer number > partition number: The extra consumers will not consume any messages
Partition allocation strategy: Ensure that each consumer can consume partition data as evenly as possible, and prevent a consumer from consuming a particularly large number of partitions or a particularly small number of partitions
1. Range allocation strategy (Range allocation strategy):Kafka's default allocation strategy
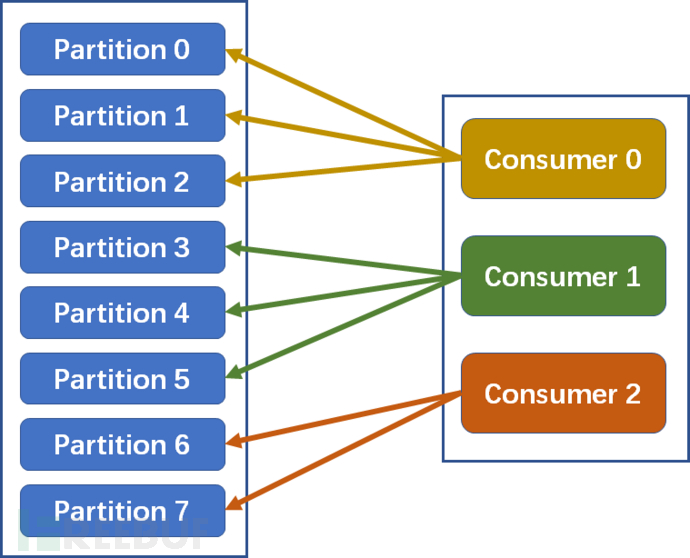
Calculation formula:
n=partition number / consumer number
m=partition number % consumer number
The first m consumers consume n+1 partitions, and the remaining consumers consume n partitions
Taking the above figure as an example: n=8/3=2, m=8%3=2, so the first 2 consumers consume 2+1=3 partitions, and the remaining 1 consumer consumes 2 partitions
2. RoundRobin allocation strategy(Round Robin allocation strategy)
Each consumer is allocated consumption partitions individually:
As shown in the figure below, 3 consumers collectively consume 8 partitions
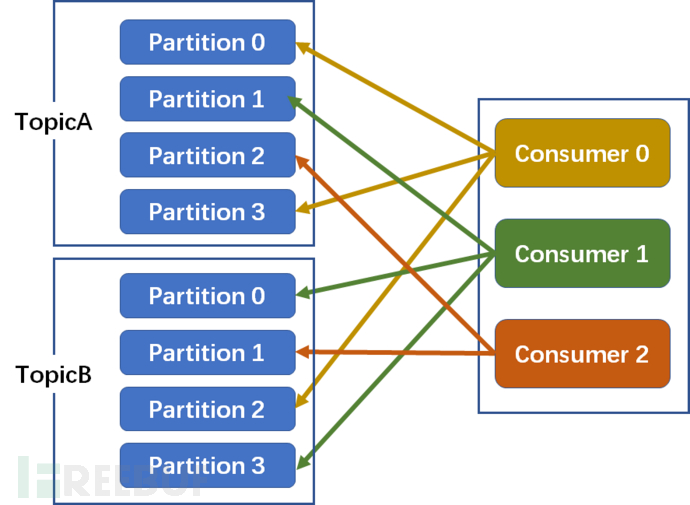
First round: Consumer0-->A-Partition0; Consumer1-->A-Partition1; Consumer2-->A-Partition2
Second round: Consumer0-->A-Partition3; Consumer1-->B-Partition0; Consumer2-->B-Partition1
Third round: Consumer0-->B-Partition2; Consumer1-->B-Partition3
3. Striky sticky allocation strategy
Without rebalance, the round-robin allocation strategy is consistent.
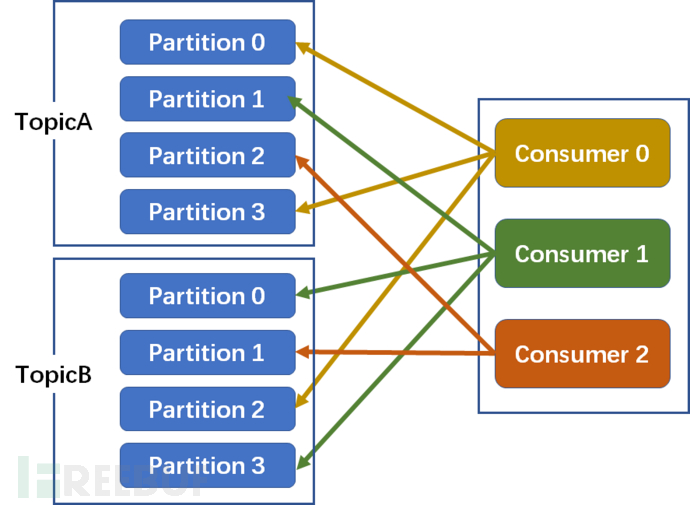
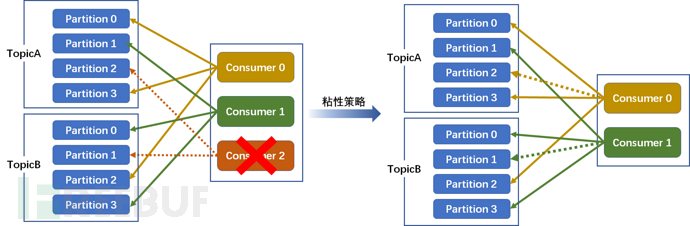
If a rebalance occurs (such as Consumer2 failing and going down), the round-robin allocation strategy is used, and the round-robin allocation process is gone through again. Sticky ensures consistency with the last one, just evenly distribute the new partitions that need to be allocated to the existing available consumers, which reduces the context switching.
Replica ACK mechanism
The producer continuously writes data to Kafka, and there will be a return result indicating whether the write is successful. Here there is a corresponding ACKs configuration.
•acks = 0: The producer only writes and does not care whether the write is successful, which may result in data loss. The performance is the best.
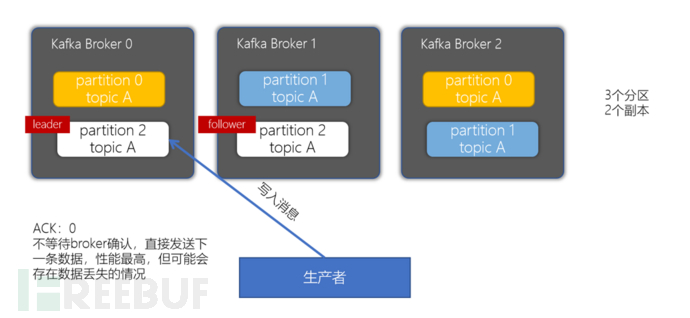
•acks = 1: The producer will wait until the leader partition is written successfully before returning success and sending the next one.
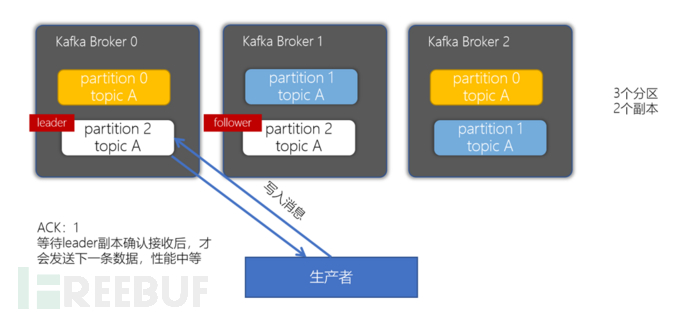
•acks = -1/all: Ensures that the message is written to the leader partition and also ensures that the message is successfully written to the corresponding replica before sending the next one, which has the worst performance.
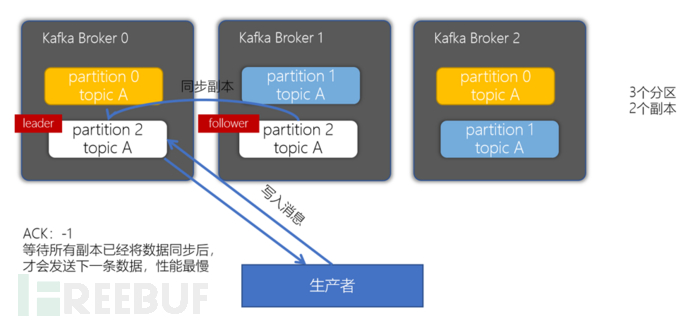
Choose the ack mechanism according to the business situation, if the highest performance is required and the loss of some data has little impact, 0/1 can be chosen. If it is required that the data cannot be lost at all, it must be configured as -1/all.
There is a concept of leader and follower in the partition, in order to ensure that the data consumed by the consumer is consistent, one can only read and write messages from the partition leader, and the follower's job is to synchronize the data.
Q&A:
1. Where is the offset stored?
Before version 0.9, the default was zk, but due to frequent access to zk, zk needs to update the offset for each node one by one, which cannot be updated in bulk or grouped, leading to the offset update becoming a bottleneck.
In the new version of Kafka and subsequent versions, the Kafka consumer's offset is stored by default in a topic called __consumer_offsets within the Kafka cluster. The offset is sent as a message to this topic and stored in the broker. This way, when the consumer submits the offset, it only needs to connect to the broker, without accessing zk, thus avoiding the bottleneck of zk node updates.
2. What is the leader election strategy?
2 types of leaders: ① broker's leader, i.e., controller leader ② partition's leader
1.Controller leader: When a broker starts up, a KafkaController object is created, but only one leader can provide services to the outside in the cluster. These KafkaController objects on each node will create temporary nodes under the specified Zookeeper path. Only the KafkaController that successfully creates the first node can become the leader, and the rest are followers. When the leader fails, all followers will receive a notification and compete to create nodes under this path again to elect a new leader
2.Partition leader: executed by the controller leader
•Read the current Partition's all ISR (in-sync replicas) set from Zookeeper
•Call the configured partition selection algorithm to select the leader of the partition
How to handle the situation where all Replicas are not working? When there is at least one follower in the ISR, Kafka can ensure that committed data is not lost. However, if all Replicas of a Partition fail, it cannot guarantee that data loss will not occur. In this case, there are two feasible solutions: wait for any Replica in the ISR to become 'alive' and select it as the Leader; or select the first 'alive' Replica (not necessarily in the ISR) as the Leader. This requires making a simple compromise between availability and consistency. If you must wait for an ISR Replica to become 'alive', the time of unavailability may be relatively long. Moreover, if all Replicas in the ISR cannot become 'alive' or the data is lost, this Partition will be permanently unavailable. If the first 'alive' Replica is selected as the Leader and this Replica is not in the ISR, even if it does not guarantee that it contains all committed messages, it will still become the Leader and serve as the data source for consumers (as explained earlier, all reads and writes are completed by the Leader). Kafka 0.8.* uses the second method. According to Kafka's documentation, in future versions, Kafka supports users to configure and choose one of these two methods to select high availability or strong consistency based on different usage scenarios.
3. Increasing the number of partitions can improve scalability and throughput. Is it better to have more partitions?
It is not necessarily better to have more partitions; there are the following drawbacks to having too many partitions:
•The cost of producer memory and consumer thread overhead increases as partitions increase. Partition is the basic logical organization unit for Kafka to manage data. More partitions mean more data storage files (at least 3 data files correspond to one partition).
•Increased Partitions Lead to Decreased Data Continuity
•Reduced Availability
4. What are the advantages of Kafka compared to databases?
•Different business scenarios and underlying data structures result in less functional requirements for Kafka data storage, which makes the read and write operations faster. The data structure of the file storing Kafka data (messages themselves) is an array. The characteristics of the array are: data are stored contiguously, and if read in order or appended, the time complexity is O(1), which is the most efficient.
5. Ways to Update Consumer OffsetsWhether it is the default Kafka API or the Java API, there are two ways to update offsets: automatic commit and manual commit.
1.Automatic Commit (Default Method)
The automatic offset commit in Kafka is controlled by the parameters enable_auto_commit and auto_commit_interval_ms. When enable_auto_commit=True, Kafka will submit offsets to the built-in topic (__consumer_offsets) at the frequency of auto_commit_interval_ms during the consumption process. Specifically, the submission is to which Partition: Math.abs(groupID.hashCode()) % numPartitions.
This method is also known as at most once. After fetching the message, the offset can be updated, regardless of whether the consumption is successful.
2. Manual submission
Given the inflexibility and inaccuracy of Kafka's automatic offset submission (it can only be submitted at a specified frequency), Kafka provides a manual offset submission strategy. Manual submission can provide more flexible and accurate control over offsets to ensure that messages are not consumed repeatedly and messages are not lost.
There are mainly 3 ways to manually submit offset:
Synchronous submission: It will keep trying to submit until it encounters an unretryable situation before ending. Under synchronous mode, the consumer thread will be blocked when pulling messages. It will keep blocking until the offset submission operation is successful or an exception occurs during the submission, which limits the message throughput.
Asynchronous submission: When manually submitting offset asynchronously, the consumer thread will not be blocked, and it will not retry on failure. It can also be配合 with a callback function to record error information when the broker responds. For asynchronous submission, since there is no retry on failure, if the offset has not been submitted before the consumer is abnormally closed or before rebalancing is triggered, it will cause the offset to be lost.
Asynchronous + Synchronous: To address the issue of lost offset in asynchronous submission, the consumer is submitted asynchronously in batches and synchronized at shutdown. This way, even if the previous asynchronous submission fails, it can still be remedied through synchronous submission. The synchronization will keep retrying until the submission is successful. The finally block will trigger consumer.commit() at the end regardless of whether there is an exception, ensuring that the offset will not be lost.
References:
https://www.jianshu.com/p/90a15fe33551
https://www.jianshu.com/p/da3f19cee0e2
https://www.modb.pro/db/373502
https://blog.csdn.net/anryg/article/details/123579937
https://toutiao.io/posts/ptwuho/preview
Author: JD Technology, Yu Tianxin
Source: JD Cloud Developer Community. Please indicate the source when转载.

评论已关闭