1 Introduction
As a distributed search engine, Elasticsearch itself is highly available; but it can't withstand some special situations, such as:
More than half of the master nodes in the cluster are lost, the ES nodes cannot form a cluster, which leads to the cluster being unavailable;

File damage of the index shard, the shard cannot be normally recovered, which leads to the index being unable to provide normal services
Local disk node, multiple data node failures, the old node cannot join the cluster again, and data loss
In response to the above situations, today we will talk about the relevant solutions.
2 Basic Knowledge
2.1 Classic Cluster Architecture
Before discussing the solutions, let's first take a look at the basic knowledge of the ES cluster level, which is usually as shown in Figure 1-1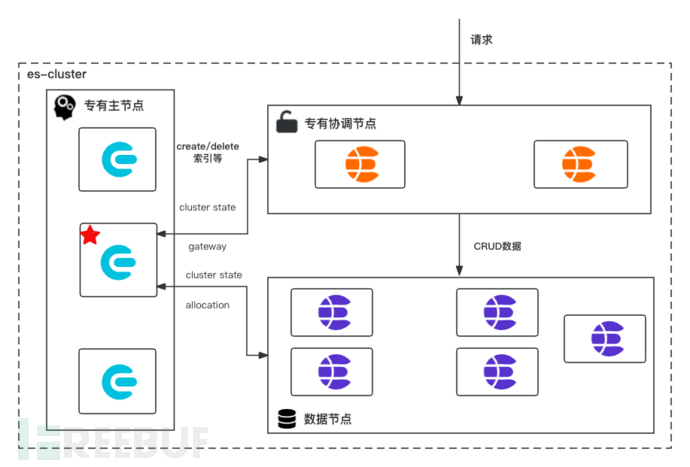
Figure 1-1 Common es cluster architecture
As shown in Figure 1-1, it is the classic architecture of the production environment es cluster, mainly composed of exclusive master nodes, exclusive coordination nodes, and data nodes:
Exclusive master node (Master-eligible node): Nodes with the master role, which qualifies them to be elected as master nodes, store only cluster metadata including cluster, index, and shard-level metadata; after such nodes are elected as master nodes, they will act as the brain of the entire ES cluster, responsible for maintaining cluster-level metadata, creating and deleting indexes, and other tasks. The number of such nodes must be odd, and we usually fix it at 3. If half of these nodes are lost, the es cluster will not be able to maintain the es nodes forming a cluster.
Exclusive coordination node (gateway node): This type of node does not have any role and is only used to process es requests; for example (1) classifying and forwarding write requests to the node where the data belongs (2) performing secondary aggregation calculations for query requests. We will also usually reserveingest role, the main function of ingest is to preprocess data; for example: renaming fields, applying fingerprints to data documents, and cleaning data are mainly throughpipeline capabilityto be processed
Data node (Data node): Store data and cluster metadata, perform operations related to data, such as CRUD, search, and aggregation. Different attributes can be applied to data nodes to make them hot, warm, or cold data nodes. The configuration is slightly different after version 7.9, but the principle is basically the same.
If the node role is not explicitly set, each node in es will contain the three roles mentioned above. In addition, there is alsoRemote-eligible node,ml-nodeandTransform nodesConfiguration that needs to be displayed for roles, and the node will have that role.
2.2 Cluster metadata
The complete startup of the cluster mainly includes important stages such as master node election, metadata, primary shard, and data recovery; as shown in Figure 2-1 [1].
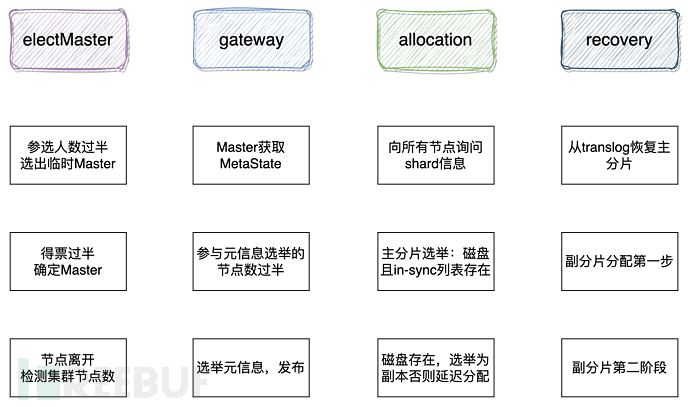
Figure 2-1 es cluster startup process
The process of master node election is not the focus of this article, but the election of cluster metadata. The level of the elected master and the newness of the cluster metadata are unrelated; after the master node is elected, the first task it needs to complete is to elect the cluster metadata.
(1) After the master election is successful, determine whether there is STATE_NOT_RECOVERED_BLOCK in the cluster state it holds. If it does not exist, it means that the metadata has
After recovery, skip the gateway recovery process, otherwise wait.org.elasticsearch.gateway.GatewayService#clusterChanged
// Skip metadata recovery
if (state.blocks().hasGlobalBlock(STATE_NOT_RECOVERED_BLOCK) == false) {
// already recovered
return;
}
// Some code is omitted here.
// Enter the gateway recovery process
performStateRecovery(enforceRecoverAfterTime, reason); (2)The Master actively fetches metadata information from each node.org.elasticsearch.gateway.Gateway#performStateRecovery
# Core code to obtain metadata
final String[] nodesIds = clusterService.state().nodes().getMasterNodes().keys().toArray(String.class);
logger.trace("performing state recovery from {}", Arrays.toString(nodesIds));
final TransportNodesListGatewayMetaState.NodesGatewayMetaState nodesState = listGatewayMetaState.list(nodesIds, null).actionGet();(3)From the metadata information obtained, select the version number with the largest as the latest metadata; metadata includes cluster level and index level.
## org.elasticsearch.gateway.Gateway#performStateRecovery
public void performStateRecovery(final GatewayStateRecoveredListener listener) throws GatewayException {
# Omitted several lines of code
## Enter the allocation phase;
## final Gateway.GatewayStateRecoveredListener recoveryListener = new GatewayRecoveryListener();
## listener is GatewayStateRecoveredListener
listener.onSuccess(builder.build());
}(4) After both are determined, call allocation module's reroute to allocate the unallocated shards, and during the allocation process of the primary shard, the metadata at each shard level is asynchronously obtained.
#The main implementation method is as follows
#org.elasticsearch.gateway.GatewayService.GatewayRecoveryListener#onSuccess
## The main task is to build the cluster state (ClusterState), where the content routing table depends on the allocation module to assist in completion, calling allocationService.reroute to enter the next stage: asynchronously executing the recovery of shard-level metadata and shard allocation. The updateTask thread ends.Data stored in ES:(1) state metadata information; (2) index Lucene-generated index files; (3) translog transaction log.
Metadata information:
nodes/0/_state/*.st, cluster-level metadata MetaData (clusterUUID, settings, templates, etc.);
nodes/0/indices/{index_uuid}/_state/*.st, index-level metadata IndexMetaData (numberOfShards, mappings, etc.);
nodes/0/indices/{index_uuid}/0/_state/*.st, shard-level metadata ShardStateMetaData (version, indexUUID, primary, etc.).
The above information is persisted to disk: the persisted state does not include the routing information such as which node a shard exists on, and when the cluster is restarted completely, the RoutingTable and RoutingNode are rebuilt through the recovery process of the gateway. When reading a document, after determining the target shard based on the routing algorithm, the shard located in the RoutingTable is searched, and then the request is forwarded to the target node [1].
⚠️ Notice: After es7.0.0, the storage method of Elasticsearch metadata has changed;
After es7.0.0, the storage of metadata has been changed to use the lucene storage method, seepr50928 Move metadata storage to Lucene)
7.10.2 Exclusive master node, cluster metadata
https://www.freebuf.com/articles/database/
-- _state
| |-- _39h.cfe
| |-- _39h.cfs
| |-- _39h.si
| |-- node-0.st
| |-- segments_50d
| `-- write.lock
`-- node.lock6.8.13 Exclusive master node, cluster metadata
https://www.freebuf.com/articles/database/
-- _state
| |-- global-230.st
| `-- node-2.st
-- indices
| |-- -hiy4JnoRfqUJHTJoNUt4Q
| | `-- _state
| | `-- state-4.st
| `-- ylJKVlqISGOi8EkpxHE_2A
| `-- _state
| `-- state-6.st
`-- node.lock3 Disaster scenarios and handling methods
3.1 Master node lost
⚠️ Note the number of master nodes mentioned in this article, assuming the premise is 3
Scenario 1: The master node is lost by more than half
The master node controls the entire cluster; when the role of this type of node is lost by more than half, due to the voting nodes in the cluster never being able to reach quorum, it is impossible to select a master, and the cluster cannot maintain es nodes to form a cluster; although the cluster cannot form a cluster, fortunately, the master-eligible nodes are still alive, and we can use the following methods to deal with it.
Before es7.0.0 version
1 Modify the elasticsearch.yaml configuration of the remaining nodes as follows, modify the quorum number, and then start the remaining nodes to form a new cluster;
discovery.zen.minimum_master_nodes: 1
discovery.zen.ping.unicast.hosts:
- masters-04 Rebuild the master-eligible nodes that were lost before, and join the cluster after that.
3 Modify the cluster configuration to the old configuration, and then restart each node in the cluster one by one, starting from the master-eligible.
After the es7.0.0 version (inclusive).
After the es7.0.0 version, due to the modification of the cluster startup configuration by es, a new configuration has been addeddiscovery.seed_hostsand cluster.initial_master_nodes;The first startup of the es cluster is called bootstrap, during which the cluster.initial_master_node in the configuration file is used as the initial voting nodeVoting configurationsVoting nodes have the right to elect master and commit cluster state, and a successful vote is achieved if more than half agree. If we need to take down more than half of the master-eligible nodes in a cluster health scenario, we must first use the voting configuration exclusion API to exclude the affected nodes from the voting configuration.
POST _cluster/voting_config_exclusions?node_names={node_names}
POST _cluster/voting_config_exclusions?node_ids={node_ids}
DELETE _cluster/voting_config_exclusionsHowever, if the lost master node exceeds half, the new cluster processing tool elasticsearch-node unsafe-bootstrap can be used pr37696and elasticsearch-node detach-cluster pr37979
The handling steps after losing half of the master-eligible nodes in es7.0.0 (inclusive) version are as follows:
1 Usebin/elasticsearch-node unsafe-bootstrapCommand to make the only master node rewrite the voting node in an unsafe way, just like re-performing bootstrap, and use the persisted cluster state to form a new cluster
2 Other data nodes cannot join the new cluster because the UUID is different (es uses UUID as the unique representation of nodes and clusters, each node will persist the current cluster's UUID), usebin/elasticsearch-node detach-clusterCommand to make the node leave the previous cluster
3 Start the data nodes and new master-eligible nodes (as follows, add two new master-eligible nodes), which will join the new cluster
cluster.initial_master_nodes:
- {master-0}
- {new-master-1}
- {new-master-2}
discovery.seed_hosts:
- {master-ip-0}
- {new-master-ip-1}
- {new-master-ip-2}Scenario 2: All master nodes are lost
Before es7.0.0 version
1 Disable the security feature (if it is enabled, it is better to disable the security plugin feature first):
1.1 Because the newly started master node does not have data nodes (if only one master role is configured), the initialization of the security plugin cannot be completed, and various interfaces are not easy to call
1.2 If the master node started up is configured with the master and data roles, the security plugin will initialize successfully. It will insert the index, but this index will conflict with the original data node. Don't know how to solve it.
Official of Elasticxpack-security; Disable authentication:xpack.security.enabled: false
2 Start enough new master-eligible nodes to form a new cluster.
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts:
- {new-masters-1}
- {new-masters-2}
- {new-masters-3}3 Modify the address of the data node to the new master, and delete the _state on the node (because the cluster UUID of the new cluster is different), as above
4 Start the data node, and the recovered data is added to the cluster
es7.0.0 (inclusive) version and later
There is no cluster state anymore, the only hope is the index data on the data node; the recovery method is to useelasticsearch-nodeTool
1 Disable the security feature (if it is enabled, it is better to disable the security plugin feature first), the reason is the same as above
2 Start enough new master-eligible nodes to form a new cluster
cluster.initial_master_nodes:
- {new-master-0}
- {new-master-1}
- {new-master-2}
discovery.seed_hosts:
- {new-master-ip-0}
- {new-master-ip-1}
- {new-master-ip-2}3 bin/elasticsearch-node detach-clusterThe command makes the data node leave the previous cluster
https://www.freebuf.com/articles/database/bin/elasticsearch-node detach-cluster
------------------------------------------------------------------------
WARNING: Elasticsearch MUST be stopped before running this tool.
------------------------------------------------------------------------
You should only run this tool if you have permanently lost all of the
master-eligible nodes in this cluster and you cannot restore the cluster
from a snapshot, or you have already unsafely bootstrapped a new cluster
by running `elasticsearch-node unsafe-bootstrap` on a master-eligible
node that belonged to the same cluster as this node. This tool can cause
arbitrary data loss and its use should be your last resort.
Do you want to proceed?
Confirm [y/N] y
Node was successfully detached from the cluster4 Query dangling indices,GET /_dangling, This API was introduced in es7.9 version pr58176
5 Start the data node and useImport dangling index APIImport index data into the cluster state (officially recommended, after es7.9 version). Or configuregateway.auto_import_dangling_indices: trueIntroduced in es7.6 versionpr49174(Available for es7.6.0-7.9.0 configurations, no configuration is required to load dangling indices by default before version 7.6) and start the data node
POST /_dangling/{index-uuid}?accept_data_loss=true6 After the import is completed, the index recovery can be performed for reading and writing
Note
Q1: Why do you need to configure after 7.6.0 to process dangling index (dangling index) so that data can join the new cluster, and are there no dangling indices after 7.6.0?
A1: In fact, there is, but the configuration was removed in es2 version (correspondingpr10016), by default, automatically loads dangling index (es2.0-es7.6); the specific implementation is atorg.elasticsearch.gateway.DanglingIndicesState#processDanglingIndiceses7.6 introduces the dangling configuration again, introduced in es7.9dangling index rest api
Q2: What is a dangling index?
A2: When a node joins the cluster, if any shard (shard) stored in its local data directory does not exist in the cluster, it will be considered as a 'dangling' index. The scenarios where a dangling index is generated (1) multiple indices are deleted when the Elasticsearch node is offlinecluster.indices.tombstones.sizeIndex, the node joins the cluster again (2) master node lost, data node re-joins the new cluster, etc.
3.2 Data node failure
After a data node disaster failure, it cannot be recovered and join the cluster; you can physically copy the data to a new node, and then join the data node to the cluster in the same way as the master node is lost.
3.3 Shards cannot be automatically allocated
View why the index shard cannot be allocatedPOST _cluster/allocation/explain
3.3.1 Shard is normal
If the shard data is normal, we can try to retry the allocation of the shard task;POST _cluster/reroute?retry_failed
Get the shard of the index on which nodes it is located, use_shard_stores api
GET indexName1/_shard_storesUsecluster rerouteReallocate
# Try to allocate a replica
POST /_cluster/reroute
{}}
"commands": [
{}}
"allocate_replica": {
"index": "{indexName1}",
"shard": {shardId},
"node": "{nodes-9}"
}
}
]
}If the primary shard cannot be allocated, you can try the following command to allocate.
POST /_cluster/reroute
{}}
"commands": [
{}}
"allocate_stale_primary": {}}
"index": "{indexName1}",
"shard": {shardId},
"node": {nodes-9},
"accept_data_loss": true
}
}
]
}If the primary shard is indeed unallocatable, the only choice is to lose the data of the shard and allocate an empty primary shard
POST /_cluster/reroute
{}}
"commands": [
{}}
"allocate_empty_primary": {
"index": "{indexName1}",
"shard": {shardId},
"node": "{nodes-9}",
"accept_data_loss": true
}
}
]
}Refer to before es5.0 version; https://www.elastic.co/guide/en/elasticsearch/reference/2.4/cluster-reroute.html
3.3.2 Shard data corruption
shard corrupted
Error referenceCorrupted elastic index
shard-toolThe es6.5 version introduced, this operation requires stopping the node
The elasticsearch-shard tool was introduced in es6.5 version pr33848
The introduction of elasticsearch-shard in es7.0.0 pR32281
bin/elasticsearch-shard remove-corrupted-data --index {indexName} --shard-id {shardId}
## Example: repair the 0th shard of index twitter
bin/elasticsearch-shard remove-corrupted-data --index twitter --shard-id 0
## If --index and --shard-id are replaced with the index shard directory parameter --dir, then directly repair data and translog
bin/elasticsearch-shard remove-corrupted-data --dir /var/lib/elasticsearch/data/nodes/0/indices/P45vf_YQRhqjfwLMUvSqDw/0After the repair is completed, start the node. If the shards cannot be automatically allocated, use the reroute command to perform shard allocation
POST /_cluster/reroute{
"commands":[
{}}
"allocate_stale_primary":{
"index":"index42",
"shard":0,
"node":"node-1",
"accept_data_loss":false
}
}
}Before version 5, it could be repaired by configuring at the index level
index.shard.check_on_startup: fix, this configuration was removed in es6.5 version pR32279
translog damage
To perform translog repair operations, a stop node is required.
The repair tool elasticsearch-translog was introduced in es5.0.0pr19342
elasticsearch-shard remove-corrupted-data was introduced starting from es7.4.1pr47866elasticsearch-shard can directly clear translog, or repair translog as specified in the above --dir
bin/elasticsearch-shard remove-corrupted-data --index --shard-id --truncate-clean-translog
## Example: repair the 0th shard of index twitter
bin/elasticsearch-shard remove-corrupted-data --index twitter --shard-id 0 --truncate-clean-translogAfter clearing, use cluster reroute to recover
Before version 5, it could be repaired by configuring at the index level
index.shard.check_on_startup: fix, this configuration was removed in es6.5 version pR32279
segments_N file missing
File damage in this scenario is the most difficult to repair; the official has not provided tools, and we are conducting our own research.
4 References
[1] elasticsearch cluster startup process
[2]https://www.elastic.co/guide/en/elasticsearch/reference/7.9/dangling-indices-list.html
[3]https://www.elastic.co/guide/en/elasticsearch/reference/7.10/node-tool.html
Author: JD Technology, Yang Songbai
Source: JD Cloud Developer Community. Please indicate the source when转载.

评论已关闭